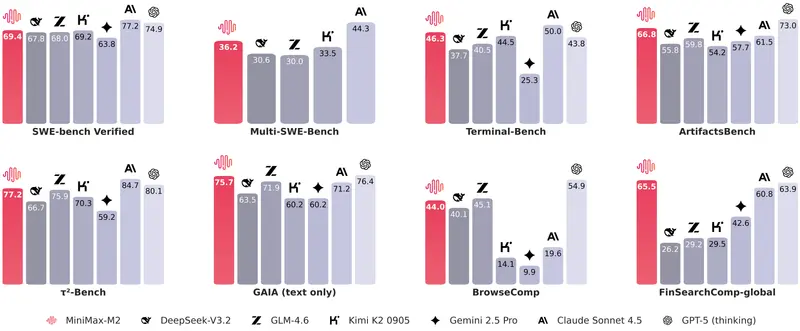
谷歌宣布推出其最新开源模型 Gemma 3n 的预览版,这是继 Gemma 3 和 Gemma 3 QAT 后,谷歌在轻量级大模型领域的又一重要进展。

Gemma 3n 专为手机、平板和笔记本电脑等设备设计,具备高性能、低内存占用和多模态能力,是目前最适合在本地运行的 AI 模型之一。它不仅继承了 Gemma 系列的开放精神,还进一步推动了“设备端 AI”的普及,让每个人都能在日常设备上体验强大而高效的智能服务。
更强性能,更低内存:AI 终于能跑在手机上了
过去,运行大规模 AI 模型通常需要依赖云端服务器。但随着设备算力提升和模型压缩技术的发展,越来越多 AI 能力开始向终端迁移。
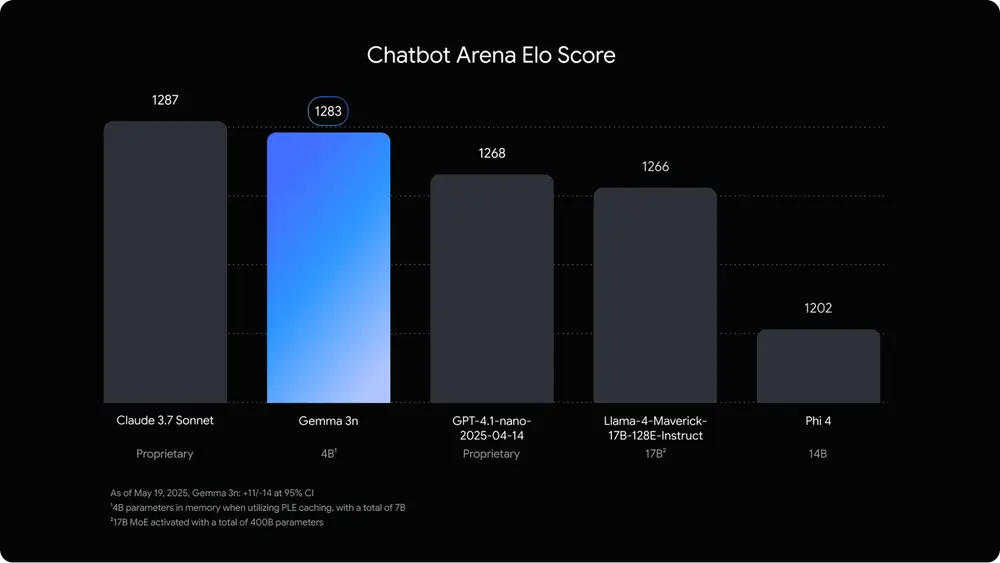
Gemma 3n 正是这一趋势下的产物。通过谷歌 DeepMind 的创新技术——逐层嵌入(Per-Layer Embeddings, PLE),Gemma 3n 在内存使用上实现了显著优化:
- 原始参数量分别为 50 亿和 80 亿;
- 实际运行时,仅需 2GB 或 3GB 动态内存,即可完成高质量推理任务;
- 相当于以 20 亿或 40 亿参数模型的资源开销,运行更大更强的模型。
这种“高效降维”技术,使得 Gemma 3n 可在主流智能手机和平板设备上实现快速响应和稳定运行。
三大核心特性:让 AI 更聪明、更灵活、更私密
✅ 1. 更快更省资源的设备端推理
- 相比 Gemma 3 4B 版本,响应速度提升约 1.5 倍;
- 支持高级激活量化、KVC 共享等优化技术,显著降低内存占用;
- 让开发者可以在本地部署更强大的 AI 模型。
✅ 2. 多合一架构 + 动态子模型混搭
- 单个模型中包含一个原生的 20 亿活跃参数子模型(基于 MatFormer 训练);
- 支持从主模型中动态生成不同规模的子模型,适应不同场景的质量/延迟需求;
- 不再需要维护多个独立模型,节省开发与部署成本。
✅ 3. 隐私优先 + 多模态理解增强
- 所有处理均可在设备端完成,无需上传数据至云端;
- 支持文本、图像、音频、视频等多种输入形式;
- 新增高质量语音识别与翻译功能,适用于会议记录、实时翻译等场景;
- 改进多语言支持,在日语、德语、韩语、西班牙语和法语等语言上的表现显著提升。
推动新一代移动 AI 应用落地
Gemma 3n 的推出,将为开发者带来全新的可能性:
- 构建实时交互式应用,如环境感知助手、语音控制机器人;
- 实现上下文感知的内容生成,结合图像、音频、文本进行复杂推理;
- 开发语音中心型产品,如自动会议纪要、跨语言对话系统;
- 提供离线可用的智能服务,保障隐私且不受网络限制。
更重要的是,Gemma 3n 是下一代 Gemini Nano 的技术基础。未来,这些能力将被集成到 Google 自身的应用和服务中,并通过 Android 和 Chrome 平台向更多开发者开放。
安全与责任并重:负责任地推进开源 AI
作为 Gemma 系列的一部分,Gemma 3n 在发布前经历了严格的安全评估与数据治理流程,确保其在广泛使用中的安全性与合规性。
谷歌始终致力于推动 AI 技术的开放与透明,同时也强调对社会影响的责任意识。随着 AI 技术的发展,这一理念也将持续迭代和完善。
如何体验 Gemma 3n?
即日起,开发者可以通过以下方式开始探索 Gemma 3n:
🔧 Google AI Studio(云端体验)
- 无需安装任何工具,直接在浏览器中试用 Gemma 3n 的文本处理能力;
- 快速了解模型的表现与适用场景。
📱 Google AI Edge(设备端开发)
- 提供完整的 SDK 与示例代码,支持在 Android 设备上部署 Gemma 3n;
- 支持图像与文本的理解与生成,后续还将扩展音频与视频功能。
访问 Google AI Studio 或 AI Edge 文档 获取更多信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











