
谷歌昨日(4月18日)通过官方博文发布了量化感知训练(QAT)优化版的Gemma 3模型。这一版本在保持高质量输出的同时,显著降低了对硬件内存的需求,为本地部署和普通硬件用户带来了福音。
- MLX 版本地址: https://huggingface.co/collections/mlx-community/gemma-3-qat-68002674cd5afc6f9022a0ae
- GGUF版本:https://huggingface.co/lmstudio-community
- Ollama:https://ollama.com/library/gemma3
Gemma 3的背景与优势
Gemma 3是谷歌上月推出的开源模型,以其高性能和高效运行能力受到广泛关注。该模型能够在单台英伟达H100 GPU上以BFloat16(BF16)精度运行,展现了强大的计算能力。然而,对于普通用户而言,高显存需求仍然是一个门槛。
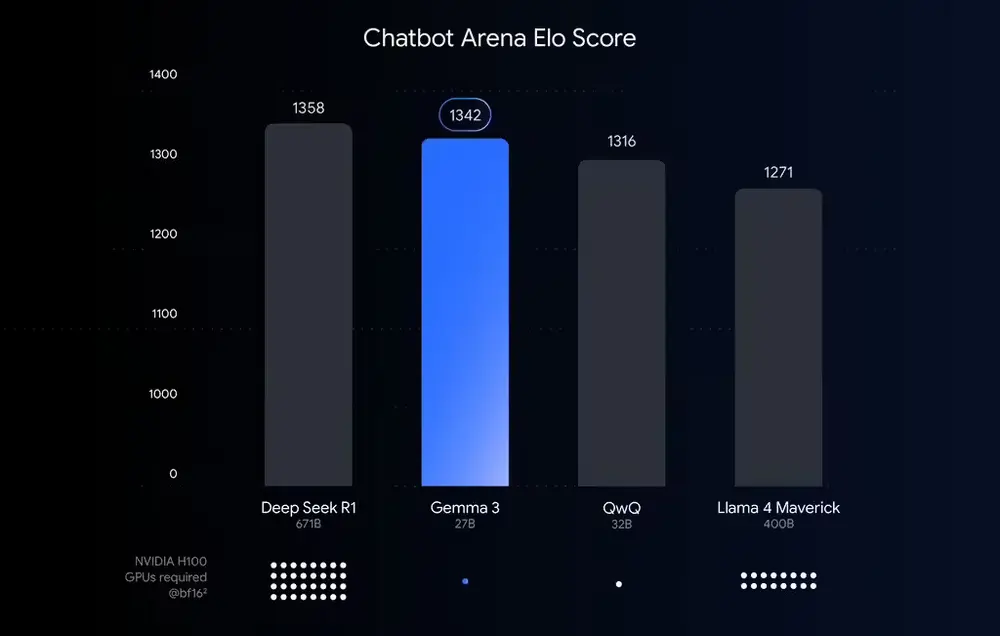
为了让更多用户能够轻松使用Gemma 3,谷歌推出了基于量化技术的优化版本——Gemma 3 QAT。通过降低模型参数的数值精度(例如从BF16的16位降到int4的4位),该模型大幅减少了显存占用,同时保持了接近半精度的质量。
量化技术的核心作用
量化技术类似于图像压缩中减少颜色数量的操作,通过降低数据存储量来节省硬件资源。具体来看:
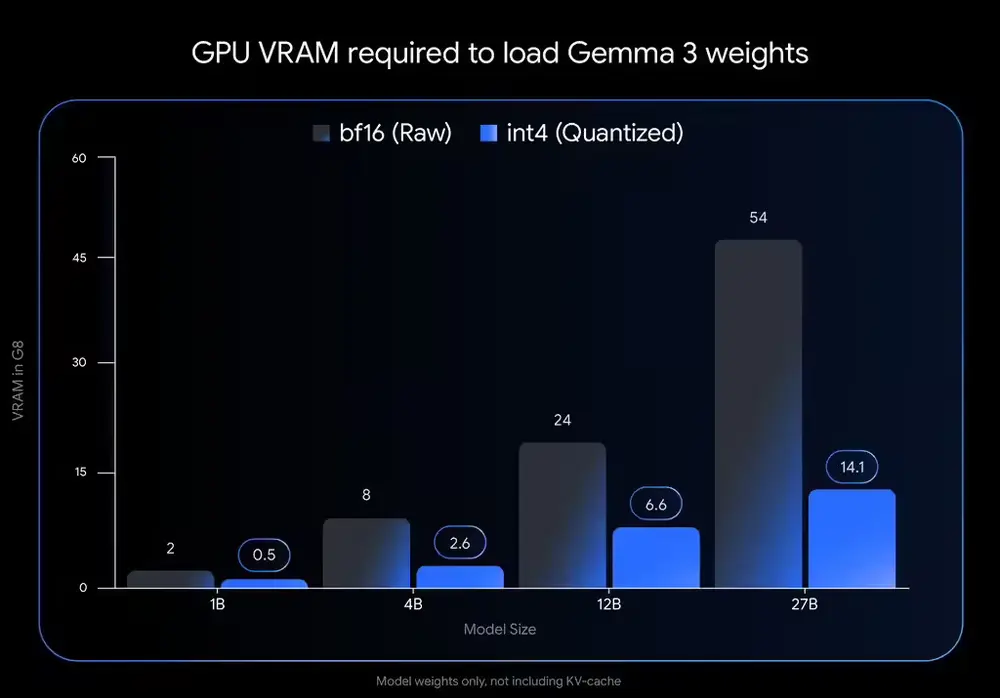
显存需求锐减:以int4量化为例,Gemma 3 27B的显存需求从54GB降至14.1GB;Gemma 3 12B从24GB降至6.6GB;而Gemma 3 1B仅需0.5GB显存。 适配更多设备:经过优化后,Gemma 3可以在桌面级显卡(如NVIDIA RTX 3090)或笔记本GPU(如NVIDIA RTX 4060 Laptop GPU)上流畅运行,甚至手机也能支持小型模型。
量化感知训练(QAT)的关键突破
单纯降低精度可能导致性能下降,因此谷歌采用了量化感知训练(QAT)技术。QAT在模型训练过程中模拟低精度运算,提前适应量化带来的影响,从而确保模型在压缩后仍能保持高准确性。
据谷歌介绍,Gemma 3 QAT模型在约5000步训练中,成功将困惑度下降幅度减少了54%。这意味着即使在低精度条件下,模型依然能够提供高质量的推理结果。
主流平台的支持与获取方式
目前,Ollama、LM Studio、MLX、Gemma.cpp和llama.cpp等主流推理框架均已支持Gemma 3 QAT模型。用户可以通过Hugging Face和Kaggle获取官方提供的int4和Q4_0模型文件,轻松在Apple Silicon或CPU上运行。
此外,Gemmaverse社区还提供了更多量化选项,满足不同硬件配置和应用场景的需求。无论是开发者还是普通用户,都可以根据自身条件选择合适的版本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











