蚂蚁集团百灵大模型团队正式推出其新一代通用语言模型——Ling-1T。作为“百灵”Ling 2.0 系列的首款旗舰级非思考(non-thinking)模型,Ling-1T 拥有 总计1万亿参数,单次推理激活约500亿参数,是目前全球已知规模最大的 FP8 训练基础模型之一。
- HuggingFace:https://huggingface.co/inclusionAI/Ling-1T
- ModelScope:https://modelscope.cn/models/inclusionAI/Ling-1T
- GitHub:https://github.com/inclusionAI/Ling-V2
- Ling chat:https://ling.tbox.cn/chat
该模型在多项复杂任务中展现出卓越的推理效率与精度平衡,在代码生成、数学竞赛、逻辑推理等高难度基准测试中表现领先,部分指标超越主流闭源模型,成为当前开源领域最具竞争力的旗舰级大模型之一。
核心亮点:更大 ≠ 更慢,而是更聪明
尽管参数规模达到万亿级别,Ling-1T 并未牺牲响应速度或推理效率。相反,它通过架构创新与训练策略优化,在“准确率 vs. Token 消耗”之间实现了新的帕累托前沿。

✅ 高效推理:用更少Token达成更高准确率
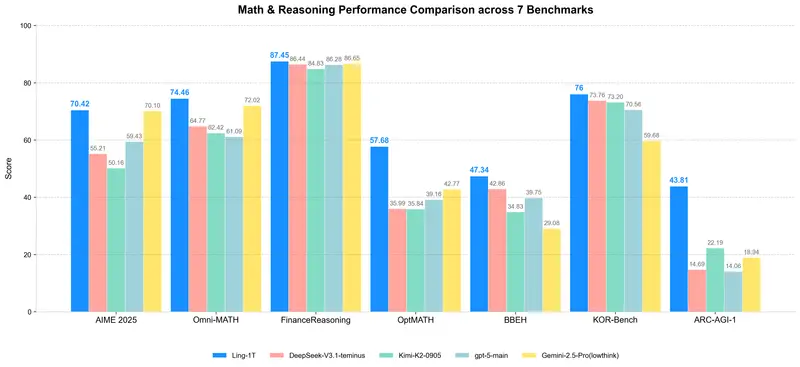
以美国邀请数学考试 AIME 25 基准为例:
- Ling-1T:平均使用 4000+ tokens,准确率达到 70.42%
- Gemini-2.5-Pro:平均消耗 5000+ tokens,准确率为 70.10%
这意味着 Ling-1T 不仅结果更优,还节省了近20%的推理成本。这一优势源于其独特的“进化式思维链”(Evo-CoT)训练方法,在中训练与后训练阶段逐步提升模型的深层推理能力。
架构设计:为万亿级扩展而生
Ling-1T 基于全新设计的 Ling 2.0 架构,从底层支持超大规模稳定训练与高效推理。关键技术创新包括:
| 技术 | 说明 |
|---|---|
| MoE 结构(1/32 激活比) | 总参数1万亿,每步仅激活约500亿,兼顾性能与算力开销 |
| MTP 层 | 增强组合性推理能力,提升多跳逻辑处理效果 |
| QK 归一化 | 保证注意力机制在长序列下的数值稳定性 |
| Sigmoid 评分专家路由 + 零均值更新 | 提升专家选择稳定性,减少训练震荡 |
此外,Ling-1T 是目前已知最大规模采用 FP8 混合精度训练的基础模型,相较传统 BF16 实现 端到端15%以上的加速,同时保持 ≤0.1% 的损失偏差,显著提升训练效率与内存利用率。

系统层面,团队通过融合内核、异构流水线调度(1F1B 交错)、重计算与动态检查点等优化手段,确保万亿级训练的稳定性与高 GPU 利用率(提升超40%)。
训练数据与流程:高质量 + 高密度推理语料
Ling-1T 在超过 20万亿 tokens(20T+) 的高质量文本上完成预训练,其中后期阶段包含 >40% 的高推理浓度数据,涵盖数学证明、编程逻辑、科学论述等内容。
训练分为三个阶段:
- 预训练:基于大规模通用语料建立基础语言理解;
- 中训练(Mid-training):引入精选的“推理预激活”思维链数据,强化模型内在推理路径;
- 后训练(Post-training):采用 Evo-CoT(进化式思维链) 方法,结合新型强化学习算法 LPO(语言单元策略优化),进一步打磨推理质量。
💡 LPO 创新点:不同于传统的 token 级(GRPO)或 sequence 级(GSPO)策略优化,LPO 将“句子”作为语义动作单元进行奖励建模,使反馈信号更贴近人类推理结构,提升训练稳定性和泛化能力。
实测表现:多项任务位居开源榜首
Ling-1T 在多个权威基准测试中取得领先成绩:
数学与逻辑推理
- AIME 25:70.42% 准确率(开源第一)
- GSM8K、MATH、TheoremQA:均进入当前开源模型前列
- 支持最长 128K 上下文窗口,适用于长文档分析与复杂问题拆解
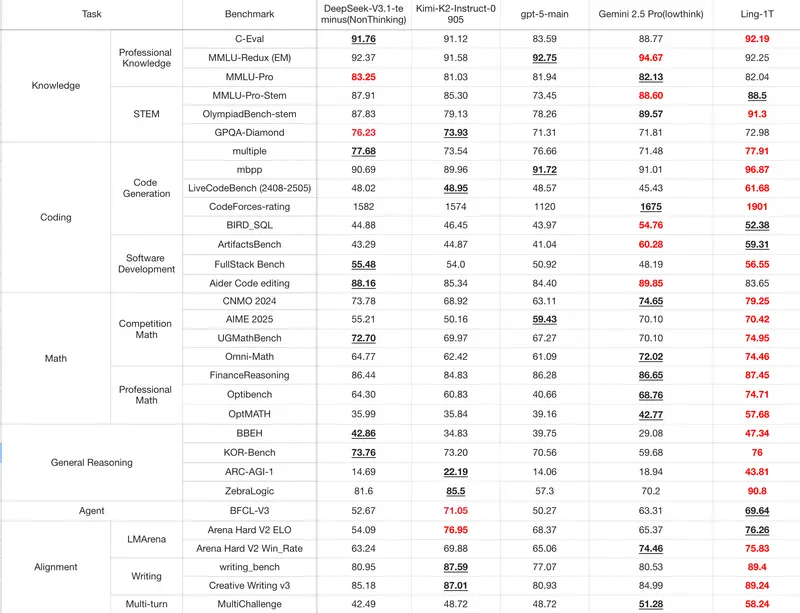
代码与软件开发
- 在 HumanEval、MBPP、LiveCodeBench 等代码生成任务中表现优异
- 可根据自然语言指令生成跨平台兼容的前端代码,支持 React、Vue 等主流框架
审美理解与前端生成
- 引入“语法–功能–审美”混合奖励机制,在 ArtifactsBench 测试中位列开源模型第一
- 能将模糊需求转化为可视化组件原型,并输出具备视觉美感的 HTML/CSS/JS 代码
- 本文所附图表即由 Ling-1T 自动生成
智能体能力初现
- 在工具调用基准 BFCL V3 上,仅经轻量指令微调,即实现约 70% 的调用准确率
- 尽管未大量接触操作轨迹数据,仍展现出良好的迁移能力:
- 解析复杂自然语言指令
- 将抽象逻辑转为可执行功能模块
- 生成风格一致的营销文案与多语种内容
这些能力表明,Ling-1T 已初步具备构建通用AI智能体的技术基础。
当前局限与未来方向
尽管 Ling-1T 在推理效率与泛化能力上取得突破,团队也坦诚指出其现有不足:
| 局限 | 后续改进方向 |
|---|---|
| 注意力机制仍基于 GQA | 探索混合注意力架构,降低长上下文推理成本 |
| 多轮交互与长期记忆较弱 | 加强工具理解、状态追踪与主动决策能力 |
| 指令遵循偶有偏差 | 引入强化式身份对齐与安全微调,提升一致性 |
未来,Ling 系列将持续在架构设计、推理深度与对齐机制上迭代,推动向更高水平的通用智能演进。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











