
在图形用户界面(GUI)日益复杂的背景下,如何让AI代理像人类一样流畅操作系统、完成多步骤任务,是自动化与智能体研究的重要方向。然而,当前自主GUI代理的发展仍面临诸多挑战:训练数据难以规模化获取、多轮交互中的策略优化不稳定、操作局限于界面点击、环境缺乏一致性等问题长期制约技术进步。
针对这些难题,字节跳动Seed项目组近日推出新一代以GUI为核心的原生代理模型——UI-TARS-2。该模型通过系统化的训练架构设计,在数据生成、强化学习稳定性、环境扩展性和部署能力等方面实现了显著突破。
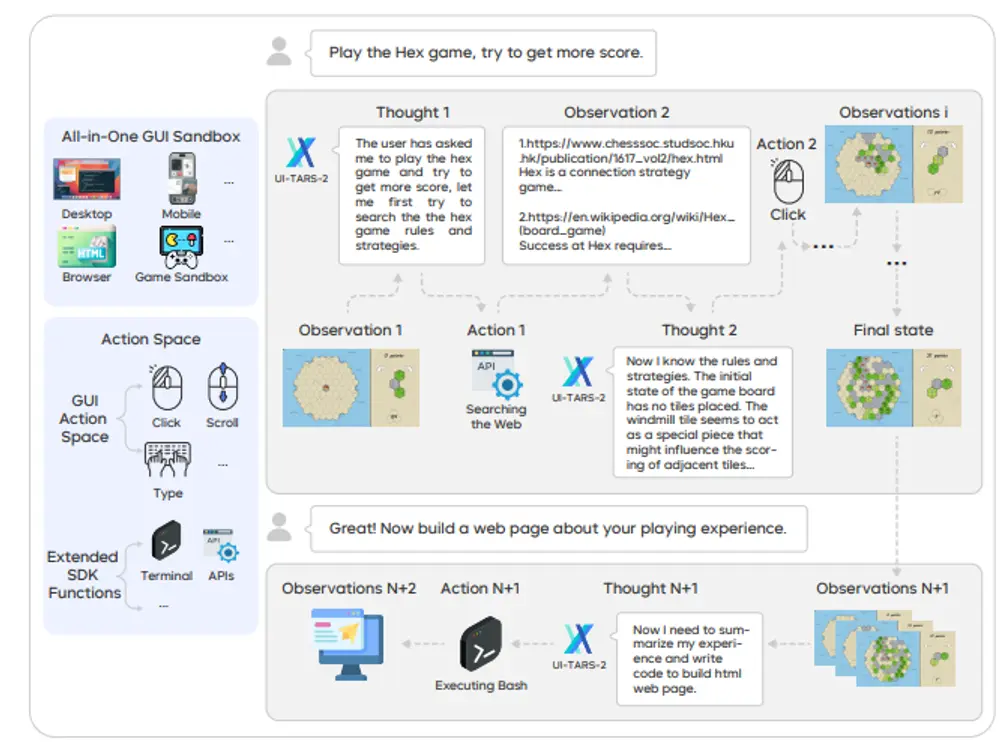
核心挑战:为什么GUI代理难做?
GUI代理的目标是让AI能够理解屏幕内容、做出决策并执行操作,例如打开浏览器搜索信息、填写表单、调用终端命令等。但与文本或代码任务不同,GUI交互具有以下特殊难点:
- 感知与动作耦合:模型需将视觉输入(如界面截图)转化为具体操作(如点击、输入),涉及跨模态建模。
- 长周期任务依赖:许多任务需要连续多步操作,上下文保持和长期规划能力至关重要。
- 反馈稀疏:成功或失败信号往往只在任务结束时出现,不利于强化学习优化。
- 环境不可控:真实GUI环境易受网络延迟、页面加载失败等因素影响,训练过程不稳定。
此前的代理模型虽在部分场景中展现潜力,但在可扩展性、鲁棒性和泛化能力上仍有明显局限。
UI-TARS-2的设计思路
UI-TARS-2采用“以GUI为中心”的原生代理架构,从数据、训练、环境到部署四个层面进行系统性优化,构建了一个可持续进化的代理训练闭环。
1. 数据飞轮:构建自我增强的训练循环
为解决数据稀缺问题,团队提出“数据飞轮”机制,整合三个阶段:
- 持续预训练(CT):利用大规模未标注GUI轨迹数据,学习通用界面理解能力。
- 监督微调(SFT):基于高质量人工标注数据,训练初始行为策略。
- 强化学习(RL):在真实环境中执行任务,收集成功轨迹,并筛选优质样本回流至前两个阶段。
这一闭环使得模型性能提升的同时,也不断生成更高价值的训练数据,形成正向循环。
2. 多轮强化学习框架:提升长期决策稳定性
传统RL在长序列任务中容易出现梯度爆炸、策略崩溃等问题。UI-TARS-2引入多项关键技术:
- 异步代理回滚机制:当任务失败时,自动恢复到关键检查点,减少无效探索。
- 状态保持环境:确保跨轮次交互中上下文不丢失,支持复杂任务拆解。
- 流式更新策略:避免处理超长轨迹带来的内存瓶颈。
- 奖励塑形 + 自适应优势估计:优化稀疏奖励下的学习效率,提升策略收敛速度。
实验表明,该框架显著提升了多轮任务的成功率和训练稳定性。
3. 混合GUI环境:打破“仅限点击”的局限
以往代理大多只能模拟鼠标和键盘操作,难以应对需要调用系统功能的任务。UI-TARS-2构建了融合文件系统与终端的混合环境,使代理具备:
- 读写本地文件
- 执行shell命令
- 调用API服务
- 管理进程与资源
这大大扩展了其任务覆盖范围,使其能处理安装软件、调试程序、批量处理文档等真实场景任务。
4. 统一沙箱平台:支持大规模训练与评估
为保障训练效率与环境一致性,团队开发了统一的沙箱管理平台,支持:
- 云虚拟机集群
- 浏览器沙盒容器
- 移动设备模拟器(Android)
- Windows桌面环境
所有环境通过标准化API接入,实现任务分发、状态监控、异常恢复的自动化管理,支撑千级并发训练任务。
实测表现:全面超越前代与主流基线
UI-TARS-2在多个公开基准和自研测试集上进行了严格评估,结果如下:
1. GUI任务基准测试
| 基准 | UI-TARS-2得分 | 对比模型表现 |
|---|---|---|
| Online-Mind2Web | 88.2 | 超过Claude、OpenAI代理 |
| OSWorld | 47.5 | 显著优于UI-TARS-1.5 |
| WindowsAgentArena | 50.6 | 达到当前开源模型领先水平 |
| AndroidWorld | 73.3 | 在移动端任务中表现突出 |
2. 游戏环境测试
在包含15款小游戏的测试套件中(如2048、扫雷、贪吃蛇等),UI-TARS-2取得平均归一化得分59.8,约为人类平均水平的60%。其中在2048游戏中,其最高分甚至超过多数普通玩家。
在LMGame-Bench评测中,其表现与OpenAI o3等前沿专有模型接近,展现出较强的通用交互能力。
3. 跨领域泛化能力
除了标准GUI任务,UI-TARS-2还在非训练分布的任务中展示了良好泛化性:
- 长周期信息检索任务(BrowseComp):准确率达29.6%,说明其具备跨页面导航与信息整合能力。
- 软件工程辅助任务:可完成代码搜索、日志分析、配置修改等,为未来IDE智能助手提供可能。
训练动态分析:揭示大规模代理学习规律
研究团队还对训练过程进行了深入分析,发现:
- 数据飞轮每轮迭代可带来约3.5%的任务成功率提升;
- 多轮RL中,前5轮增益显著,后续趋于平缓;
- 引入外部工具(如终端)后,复杂任务完成时间平均缩短40%;
- 沙箱平台的稳定性使训练中断率下降至不足2%。
这些观察为后续大规模代理训练提供了可复用的经验。
向真实世界交互迈进
UI-TARS-2并非追求短期刷榜的实验模型,而是一套面向实际应用构建的代理系统。它在数据闭环、训练稳定性、环境扩展和部署能力上的综合设计,标志着GUI代理正从“演示级”走向“可用级”。
尽管距离完全自主的通用操作代理仍有差距,但UI-TARS-2的进展表明:通过工程与算法的协同优化,AI已经能够在多样化GUI环境中稳定执行复杂任务。这一方向的持续探索,或将为个人助理、企业自动化、无障碍交互等领域带来实质性推动。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











