语言模型正在越来越多地承担需要世界知识的任务:回答问题、生成事实性文本、辅助决策……但一个根本性问题仍未解决:
模型是如何从训练数据中“学会”知识的?
我们训练模型时喂的是文本,但它输出的却是“信念”——比如“布法罗比尔是一支美式足球队”。这种从数据到知识的转化过程,至今仍像一个黑箱。
为推动这一基础问题的研究,来自特拉维夫大学与麦吉尔大学的研究团队推出了 LMEnt —— 一套专为分析语言模型在预训练阶段知识获取过程而设计的开源工具集。
- GitHub:https://github.com/dhgottesman/LMEnt
- 模型:https://huggingface.co/collections/dhgottesman/lment-68a9dd370e1f746cacd8ce58
它不追求性能突破,而是提供一个可控、可追溯、可干预的实验环境,帮助研究者理解:
- 模型何时学到某个事实?
- 哪些训练样本最关键?
- 频率是否决定学习顺序?
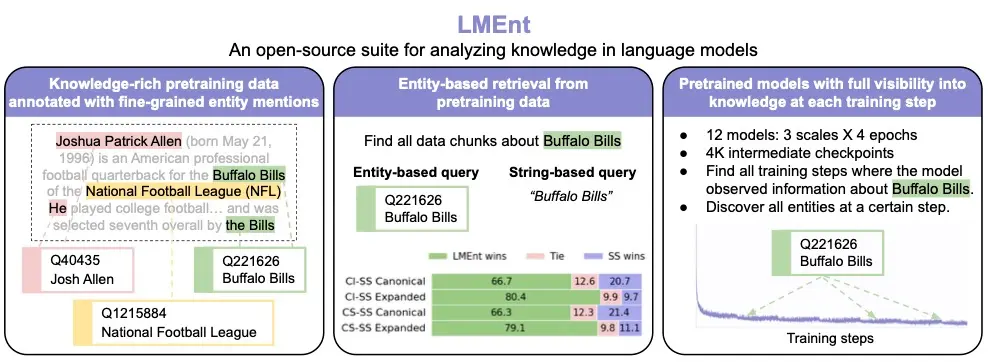
LMEnt 是什么?
LMEnt(Language Model Entity Tracking)是一个面向语言模型知识研究的综合性工具套件,包含三大核心组件:
| 组件 | 说明 |
|---|---|
| 1. 知识丰富语料库 | 基于维基百科构建,每个文档均标注了实体提及(entity mentions) |
| 2. 高效实体检索系统 | 支持通过 Wikidata ID 精准查找包含特定实体的训练块,性能比传统方法高 80.4% |
| 3. 12 个预训练模型 + 4000 个中间检查点 | 覆盖 100M–1B 参数规模,每步记录模型“看到”的实体,便于追踪学习动态 |
📦 所有资源均已开源,支持对知识表示、学习路径、编辑归因等方向的深入研究。
核心设计:让“知识获取”可被观测
传统研究通常只能观察模型最终状态,而 LMEnt 的目标是:把预训练变成一场可回放的实验。
1. 实体提及标注:构建“知识坐标系”
LMEnt 对整个预训练语料库进行了细粒度标注,识别出每处实体提及,并链接到 Wikidata 唯一标识符(QID)。
标注方法融合三种信号:
- 维基百科超链接(天然标注)
- 实体链接系统(跨文本消歧)
- 共指消解(识别“他”“该公司”等代词指向)
✅ 结果:每个训练样本不仅是一段文本,更是一个带有“知识标签”的观测单元。
2. 基于实体的检索:精准定位知识来源
以往研究难以回答:“模型学到‘爱因斯坦是物理学家’,是因为读了哪几段文本?”
LMEnt 构建了基于 Elasticsearch 的实体索引,支持:
- 按 QID 检索所有提及该实体的文本块
- 查询特定时间步中模型“看到”了哪些实体
相比基于字符串的检索,其召回率最高提升 80.4%,且精确度保持在 97% 以上。
💡 优势:避免因别名、拼写变体导致的漏检(如 “Barack Obama” vs “Obama”)
3. 中间检查点记录:追踪知识演化过程
LMEnt 提供了 4000 个训练过程中的中间检查点,覆盖 12 个不同规模的模型(最大 1B 参数)。
每个检查点都记录:
- 当前模型参数
- 最近训练样本中的实体分布
- 在知识问答任务上的表现变化
这使得研究者可以绘制出:“某个事实是在第几步被掌握的?”
实验结果:我们学到了什么?
使用 LMEnt,研究团队首次系统分析了预训练中的知识获取动态。
1. 模型性能对标主流开源模型
尽管训练计算量更少,LMEnt 模型在 PopQA 等知识基准上表现与 Pythia-1.4B 和 OLMo-1B 相当:
| 模型 | PopQA 准确率(全体实体) | (流行实体) |
|---|---|---|
| LMEnt-1B | 7.4% | 66% |
| Pythia-1.4B | 8.7% | 67% |
| OLMo-1B | 10.4% | 66% |
✅ 验证了数据标注与训练流程的有效性
2. 知识学习的关键因素:频率重要,但不唯一
研究发现:
- 高频事实更容易被早期学习:出现次数多的实体更早出现在模型输出中
- 但频率无法完全解释学习顺序:某些低频但上下文清晰的事实也可能被快速掌握
- 上下文质量与位置(如段首、标题附近)也显著影响学习速度
这表明:模型并非简单“记忆高频词”,而是具备一定的语义整合能力。
应用场景
LMEnt 不是一个应用级工具,而是一个基础研究平台,适用于以下方向:
| 研究方向 | LMEnt 的支持能力 |
|---|---|
| 知识表示 | 分析模型如何编码事实,是否形成结构化记忆 |
| 学习动态 | 追踪知识获取的时间线,识别关键训练样本 |
| 知识编辑 | 研究修改预训练数据是否能定向改变模型信念 |
| 归因分析 | 回答“模型为什么知道这个?”——溯源至具体训练样本 |
| 可塑性研究 | 探索模型对新知识的接受能力与遗忘机制 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











