
由Together AI和Agentica联合推出了一款编码模型DeepCoder-14B,正以其卓越的性能和完全开源的特点,引发AI社区的广泛关注。这款基于DeepSeek-R1构建的模型,在多个编程基准测试中表现优异,甚至可与OpenAI的o3-mini等领先专有模型媲美。更重要的是,团队不仅开源了模型本身,还公开了训练数据、代码、日志以及系统优化方法,为研究人员和开发者提供了前所未有的透明度和灵活性。
- 模型:https://huggingface.co/agentica-org
- GitHub:https://github.com/agentica-project/rllm
- Ollama:https://ollama.com/library/deepcoder
小巧但强大:DeepCoder-14B的核心优势
尽管仅拥有140亿个参数,DeepCoder-14B在多个具有挑战性的编码基准测试中展现了令人印象深刻的性能:
LiveCodeBench(LCB):实时代码生成能力表现出色; Codeforces:复杂算法竞赛任务中表现稳定; HumanEval+:代码功能正确性评估中得分接近顶级模型。
研究团队指出:“我们的模型在所有编码基准测试中表现出色,性能与o3-mini(低配版)和o1相当。”这表明DeepCoder-14B在保持紧凑模型规模的同时,能够提供与更大规模模型相媲美的性能。
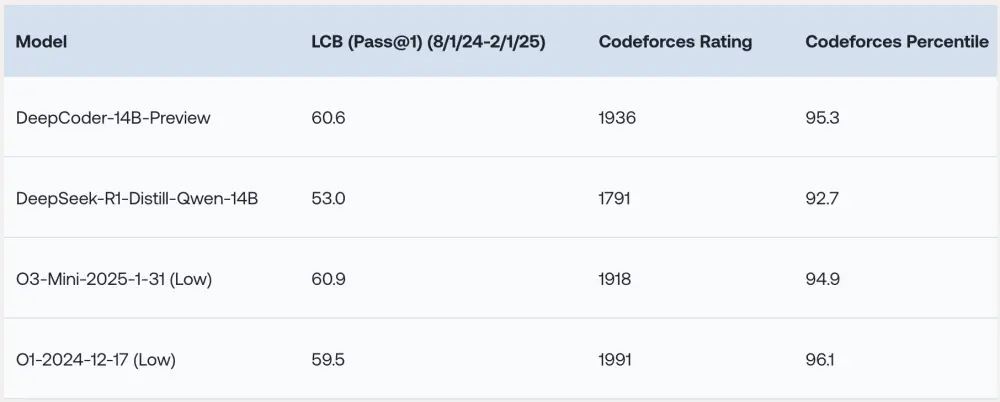
此外,DeepCoder-14B的能力并不仅限于编码任务。尽管主要针对编程进行训练,它在数学推理领域也取得了显著进步。例如,在AIME 2024基准测试中,该模型得分为73.8%,比其基础模型(DeepSeek-R1-Distill-Qwen-14B)提高了4.1%。这一结果表明,通过强化学习(RL)培养的推理技能可以有效泛化到其他领域。
推动性能的关键创新
DeepCoder-14B的成功背后,是研究团队在强化学习(RL)训练过程中解决了一系列关键挑战的成果。
1. 高质量训练数据的筛选
强化学习需要可靠的奖励信号来指导模型学习,但编码领域的高质量数据相对稀缺。为了解决这一问题,研究团队设计了一套严格的流程,从不同数据集中收集样本,并对其进行有效性、复杂性和重复性的过滤。最终,他们生成了24,000个高质量问题,为有效的强化学习训练奠定了坚实基础。
2. 简单而高效的奖励函数
团队设计了一个以结果为导向的奖励函数,仅当生成代码在特定时间限制内通过所有抽样单元测试时,才提供正向信号。这种机制避免了模型学习一些“取巧”的策略,如打印记忆答案或优化简单边界用例而不解决核心问题。
3. 改进的强化学习算法
DeepCoder-14B的核心训练算法基于Group Relative Policy Optimization(GRPO),这是在DeepSeek-R1中取得成功的强化学习算法。然而,团队对该算法进行了多项修改,使其更加稳定,并允许模型在训练时间延长时持续改进。
4. 长上下文窗口的优化
为了支持复杂的推理任务,团队逐步扩展了模型的上下文窗口,从16K增加到32K,最终使模型能够处理高达64K令牌的问题。同时,他们开发了“超长过滤技术”,在训练期间屏蔽截断序列,确保模型不会因生成深思熟虑但超长的输出而受到惩罚。
加速训练的创新工具:verl-pipeline
使用强化学习训练大型模型,尤其是在需要长生成序列的任务(如编码或复杂推理)上,往往计算密集且速度较慢。为解决这一瓶颈,研究团队开发了verl-pipeline,这是开源库verl的优化扩展,专门用于基于人类反馈的强化学习(RLHF)。
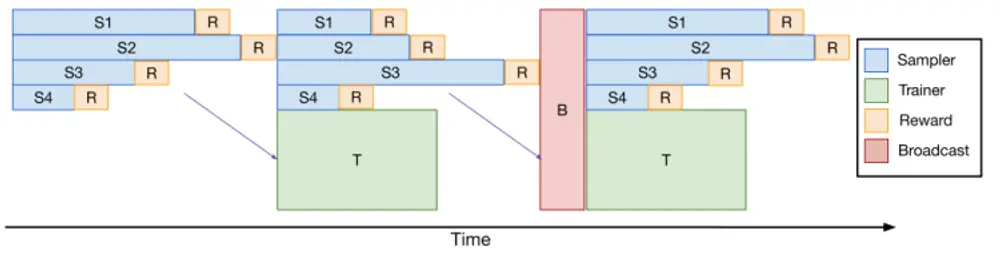
核心创新点在于“一次性流水线”技术,它重新安排了响应采样和模型更新的顺序,减少GPU空闲时间并加速训练过程。实验显示,与基线实现相比,这项优化为编码强化学习任务提供了高达2倍的加速。正是得益于这一技术,DeepCoder-14B得以在32个H100 GPU上完成为期2.5周的训练。
目前,verl-pipeline已作为开源项目发布,供社区进一步开发和使用。
对企业的影响:降低AI门槛,推动创新
DeepCoder-14B的完全开源为AI领域带来了深远影响。研究团队已在GitHub和Hugging Face上发布了所有相关资源,包括数据集、代码和训练配方。这种透明度赋予了社区重现研究工作、改进模型以及探索新应用场景的能力。
对于企业而言,这一趋势意味着更多的选择和更高的先进模型可访问性。尖端性能不再局限于超大规模公司或愿意支付高昂API费用的用户。像DeepCoder这样的模型,能够让各种规模的组织利用复杂的代码生成和推理能力,定制符合其特定需求的解决方案,并在自己的环境中安全部署。
此外,这种开源协作模式有助于培育一个更具竞争力和创新性的生态系统,推动AI技术的快速发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











