在大模型迈向“自主思考”的过程中,一个关键瓶颈逐渐显现: 现有基准任务太简单,无法真正测试模型的复杂推理能力。
Natural Questions、HotpotQA 等主流数据集虽然推动了多跳推理的发展,但其问题结构相对扁平,存在知识泄露、捷径推理等问题,难以衡量模型是否真正具备分解问题、协调子任务、综合跨源证据的能力。
为此,智源研究院提出 InfoSeek —— 一种全新的、可扩展的数据合成框架,专门用于构建结构复杂、层次清晰、内在可验证的深度研究任务。
它不依赖人工标注,而是通过一个双代理系统,从公开网页中自动挖掘实体与关系,递归构建“研究树”,并将其转化为需要多步遍历才能解答的自然语言问题。
这不仅是数据集的升级,更是对“深度研究”能力定义的一次重构。
什么是深度研究任务?
深度研究(Deep Research)任务的核心特征是:
- 问题复杂:不能通过一次检索或简单推理解决
- 结构分层:需将主问题分解为多个逻辑相关的子问题
- 约束嵌套:答案需满足多个层级的条件组合
- 证据综合:信息来自不同来源,需交叉验证与整合
例如:
“找出一个未被纳入的城市,它位于阿肯色州牛顿县,该城市位于一条被指定为阿肯色州风景道的高速公路上,其中一些也是国家风景道。”
这个问题需要模型:
- 定位“阿肯色州牛顿县”
- 找到该县内的高速公路
- 筛选出被列为“州级风景道”的路段
- 进一步判断哪些同时也是“国家级风景道”
- 最终识别出“未被纳入”的城市(即不在现有列表中)
每一步都依赖前一步的结果,形成严格的推理链。
InfoSeek 的核心设计
InfoSeek 的目标是:自动化生成这类高复杂度、无捷径、可验证的问题。其方法由三个关键环节构成。
1. 双代理系统:递归构建研究树
InfoSeek 使用两个协同工作的代理:
- Extractor Agent:从大规模网页中提取实体及其关系(如“X 位于 Y”、“Z 属于类别 W”)
- Builder Agent:基于提取的知识,递归构建研究树(Research Tree)
- 根节点:最终答案
- 内部节点:中间子问题
- 边:逻辑依赖关系(如“必须先找到 A,才能确定 B”)
这种树状结构天然支持多步推理,且每一层都构成一个有效的子任务。
2. 模糊化中间节点:防止知识泄露
传统合成方法常因中间信息过于明确而导致“捷径推理”——模型无需真正推理,仅凭关键词匹配即可作答。
InfoSeek 引入模糊化技术(Fuzzing):
- 将中间节点的描述泛化或替换为等价表达
- 保留语义一致性,但隐藏具体实体名称
- 确保模型必须通过完整推理路径才能获得答案
✅ 例如:“某县内的高速公路”替代“牛顿县的AR-16号公路”
这有效阻断了短路径,迫使模型进行完整遍历。
3. 自然语言转换 + 轨迹生成
研究树构建完成后,InfoSeek 将其转换为自然语言问题,并生成对应的推理轨迹(reasoning trace):
- 问题生成:使用模板与语言模型将树结构转为流畅问句
- 轨迹生成:通过拒绝采样(reject sampling),确保每条轨迹:
- 完整覆盖所有推理步骤
- 使用真实可访问的信息源
- 可被独立验证
输出格式包含:问题、标准答案、参考链接、推理路径
核心特点总结
| 特性 | 说明 |
|---|---|
| 层次化约束满足问题(HCSP) | 将深度研究形式化为带层级约束的问题,区别于平面或多跳任务 |
| 可扩展性强 | 基于网页自动提取知识,支持快速生成大规模数据 |
| 高质量与可控性 | 复杂度、深度、领域均可调节,适合不同训练目标 |
| 内在可验证 | 每个问题都有明确证据链和验证路径,便于评估 |
| 开源开放 | 框架与数据集均已公开,支持社区复现与扩展 |
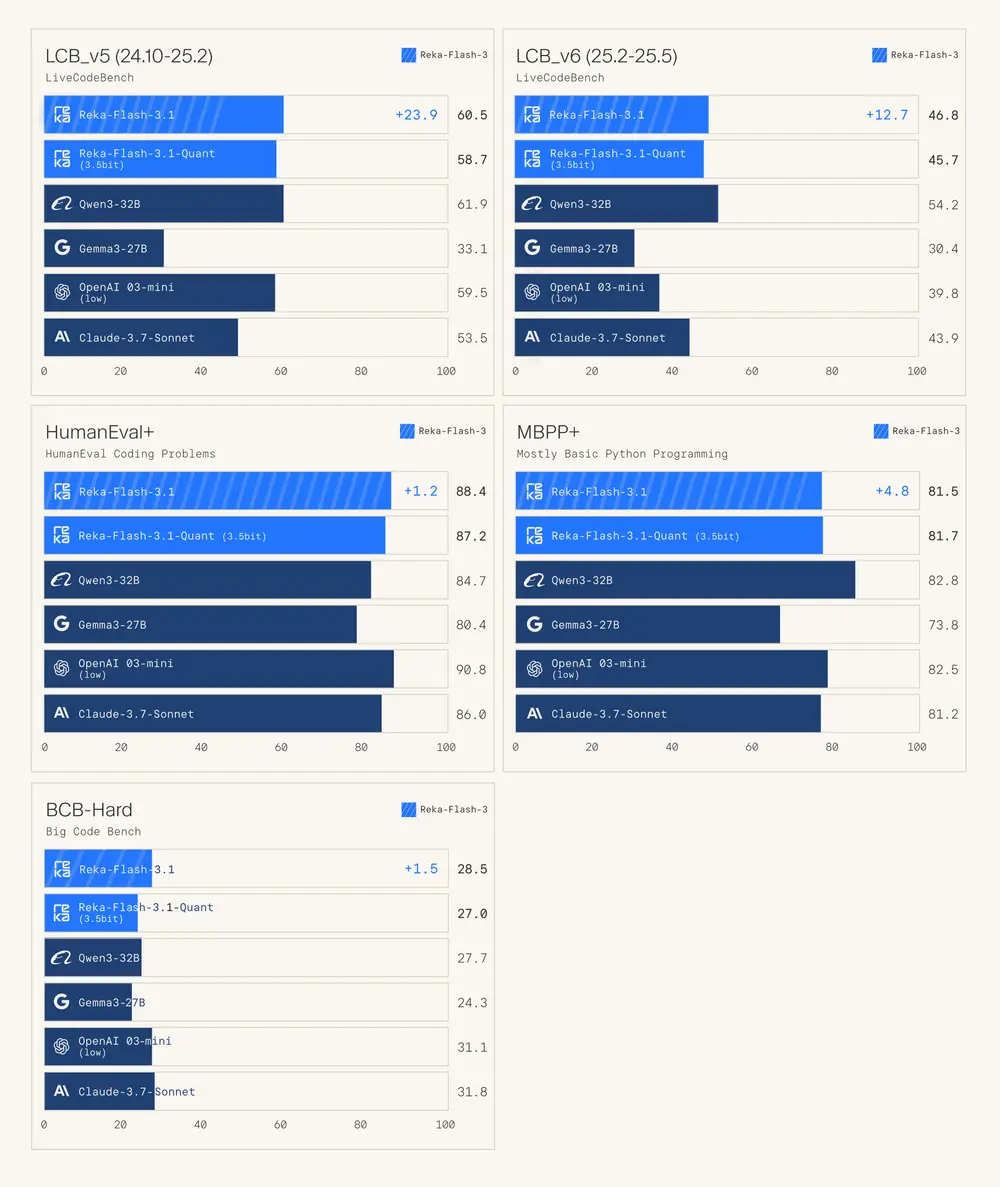
实验结果:小模型,大能力
使用 InfoSeek 构建的数据集训练出的模型,在 BrowseComp-Plus 基准上表现出色:
| 模型 | 参数量 | 准确率 |
|---|---|---|
| InfoSeeker-3B | 3B | 16.5% |
| Qwen3-32B | 32B | 3.5% |
| SearchR1-32B | 32B | 3.9% |
💡 关键发现:
- 3B 模型性能远超 32B 模型,说明训练数据的质量显著影响推理能力
- InfoSeeker 平均每次任务仅调用 8.24 次搜索,低于对比模型,表明其推理更高效
这验证了 InfoSeek 的核心假设:
更好的训练数据,比更大的模型更能提升复杂推理能力。
应用场景
| 场景 | 价值 |
|---|---|
| 复杂推理模型训练 | 提供高质量监督信号,提升模型分解问题与综合证据的能力 |
| AI 助手与搜索引擎 | 训练能执行真实研究任务的智能体(如自动撰写行业报告) |
| 科学发现辅助 | 支持跨文献的知识整合与假设生成 |
| 政策分析与风险评估 | 处理多条件、多来源的决策支持任务 |
| 学术研究基准 | 提供新的评估标准,推动“深度研究”能力的标准化评测 |
为什么重要?
InfoSeek 的意义不仅在于生成了一个新数据集,更在于提出了一套可复制的深度研究建模范式:
- 从“问答”到“研究”
不再只是回答问题,而是模拟人类研究者的思维过程。 - 从“结果监督”到“过程监督”
提供完整的推理轨迹,支持对中间步骤的建模与评估。 - 从“静态数据”到“动态合成”
可持续扩展,适应新领域、新任务,降低人工标注成本。
它为下一代 AI 系统——那些能真正“做研究”的智能体——奠定了数据基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











