
腾讯正式发布自研大模型 混元 2.0(Tencent HY 2.0),包含 HY 2.0 Think(推理优化版)与 HY 2.0 Instruct(指令对齐版)两个版本。该模型采用 混合专家(MoE),总参数达 406B,激活参数 32B,支持 256K 上下文窗口,在推理能力、效率与实用场景表现上“居国内顶尖行列”。
核心能力全面跃升
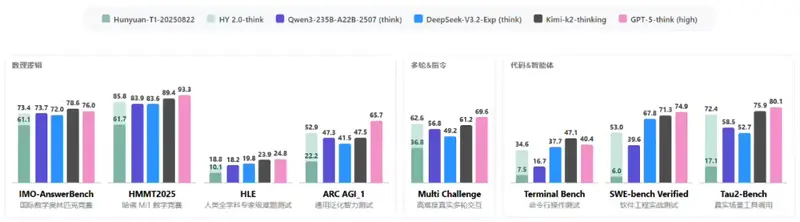
1. 复杂推理:稳居国内第一梯队
通过高质量预训练数据与 Large Rollout 强化学习,HY 2.0 Think 在以下权威评测中取得一流成绩:
- IMO-AnswerBench(国际数学奥林匹克竞赛基准)
- HMMT2025(哈佛-MIT 数学竞赛)
- Humanity's Last Exam(HLE,综合知识极限测试)
- ARC-AGI(抽象推理与泛化能力)
模型在数学、科学、逻辑推理等高难度任务上的泛化性显著增强。
2. 指令遵循与长文多轮交互
- 采用 重要性采样修正,缓解训练/推理不一致问题;
- 实现 长窗口 RL 的高效稳定训练(256K 上下文);
- 通过 多样化可验证任务沙盒 + 基于打分准则的 RL,在 Multi Challenge 等多轮复杂指令任务中效果大幅提升。
3. 代码与智能体能力突破
- 构建 规模化可验证环境 与 高质量合成数据;
- 显著提升 Agentic Coding 与 工具调用 能力;
- 在 SWE-bench Verified(真实软件工程任务)与 Tau2-Bench(智能体工具使用)等面向落地场景的评测中实现跃升。
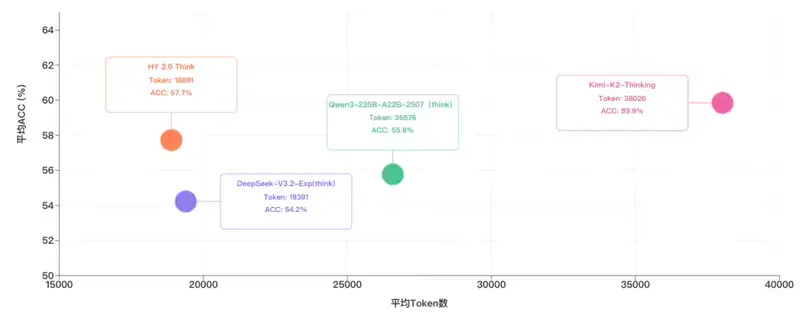
效率与“智能密度”领先业界
HY 2.0 Think 引入 精细长度惩罚策略,有效抑制冗余思维链,避免“堆砌废话”,在保证准确率的同时大幅降低 token 消耗。
对比 IMO-AnswerBench、HMMT2025、ARC-AGI、HLE 四项任务表现与 token 使用量,HY 2.0 Think 的 单位 token 智能密度 处于行业领先水平。
实用场景体验升级
基于 RLVR + RLHF 双阶段强化学习,HY 2.0 的输出“质感”显著提升,在以下场景展现差异化优势:
- 高质量文本创作(如文案、故事、报告)
- 前端开发辅助(HTML/CSS/JS 生成与调试)
- 复杂指令精准执行(多步骤、条件判断、上下文依赖)
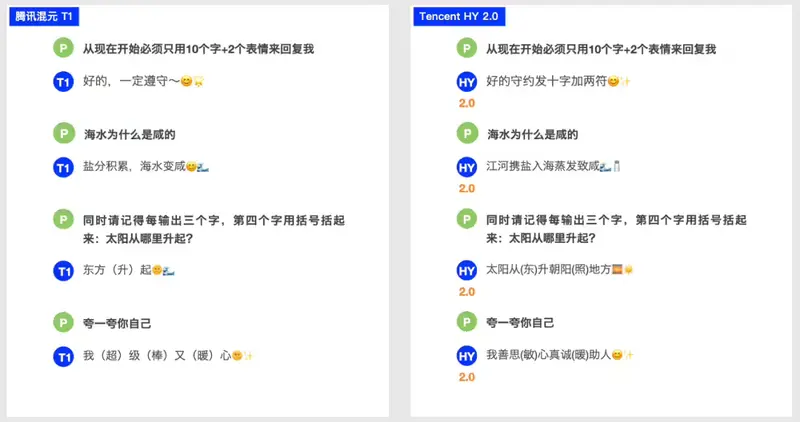
相比上一版本(Hunyuan-T1-20250822),指令遵循准确率明显提升,错误率显著下降。
已上线应用与开放计划
- 已接入产品:腾讯元宝、ima 等原生 AI 应用;
- 开发者可用:腾讯云已开放 HY 2.0 API,支持直接调用或私有化部署;
- 未来方向:持续迭代 代码能力、智能体交互、个性化风格、长程记忆;
- 开源承诺:相关技术与模型将逐步以 开源形式 向社区开放。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











