距离中国 AI 初创公司 DeepSeek 发布其热门开源模型 DeepSeek-R1-0528 不到两个月,该模型因其低成本训练和高性能推理能力迅速风靡全球 AI 社区。
如今,这款强大模型已被广泛改编、混合使用,并通过 Apache 2.0 许可免费提供给开发者与企业。而就在本周,来自德国的科技咨询公司 TNG Technology Consulting GmbH 正式推出了一款基于 R1-0528 的新变体 —— DeepSeek-TNG R1T2 Chimera,成为其 Chimera 系列大语言模型(LLM)的最新成员。
这款模型不仅在智能基准测试中达到 R1-0528 的 90% 以上得分,同时输出 token 数量仅为后者的 不到 40%,意味着更简洁的回答、更低的成本与更快的响应速度。
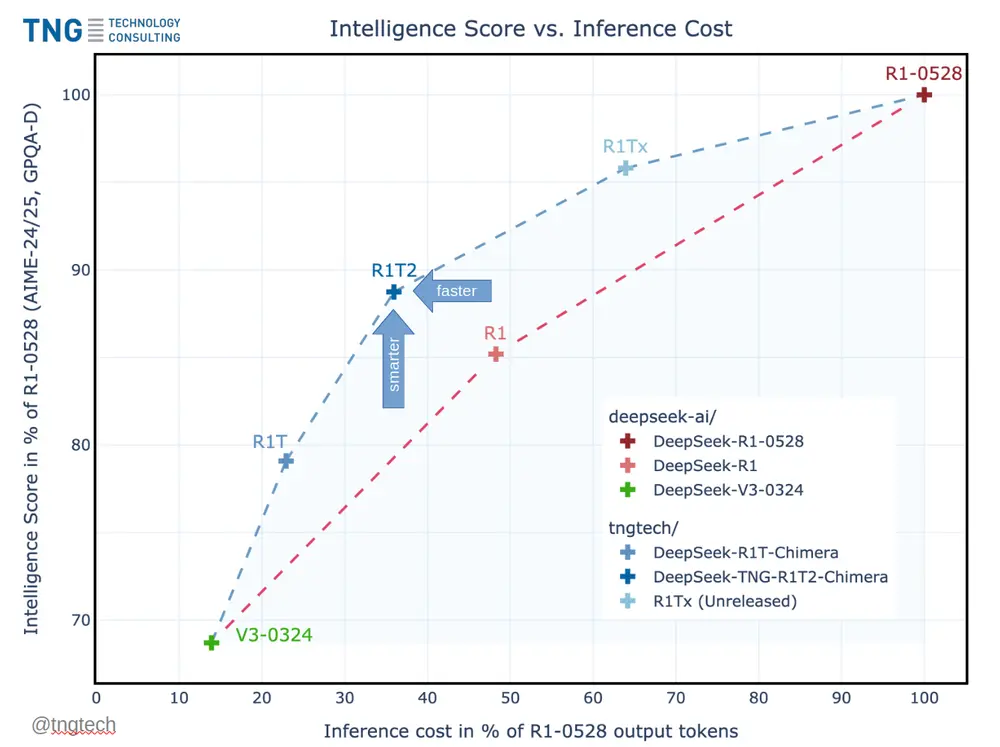
🚀 性能飞跃:比 R1 快 20%,比 R1-0528 快两倍以上
根据 Hugging Face 上发布的模型卡信息,R1T2 在推理效率上实现了显著提升:
- 比今年 1 月发布的常规 DeepSeek-R1 快约 20%
- 比 DeepSeek 官方 5 月更新的 R1-0528 快超过 200%
这种性能提升并非来自传统的微调或蒸馏方法,而是源于 TNG 独创的 “专家组装”(Assembly of Experts, AoE) 技术 —— 一种无需重新训练即可构建高效 LLM 的新方法。
什么是“专家组装”?它与 MoE 有何不同?
✅ 专家混合(MoE)简介
专家混合(Mixture-of-Experts, MoE)是一种常见的大语言模型架构设计。在 MoE 中,不同的“专家”模块会根据输入内容动态激活,从而实现高参数规模下的高效推理。例如,在一个拥有 256 个专家的 MoE 模型中,每个 token 处理仅激活其中的 8 个。
这种方法使得超大规模模型既能保持强大的推理能力,又能控制推理成本。
✅ 专家组装(AoE):一种模型融合策略
与 MoE 不同,专家组装(AoE)是一种模型合并技术,而非运行时架构设计。
它通过选择性插值多个预训练模型的权重张量来构建新模型。在 TNG 的实现中,主要聚焦于合并 MoE 层中的路由专家张量 —— 这些是负责专业推理的关键部分。
具体来说,R1T2 Chimera 集成了三个母模型的优势:
- DeepSeek-R1-0528:提供最高级别的推理能力
- DeepSeek-R1:带来结构化思维模式
- DeepSeek-V3-0324:增强简洁性和指令执行能力
最终形成一个兼具高智能与高效推理的新模型。
三脑配置:继承优势,摒弃冗余
作为原始 R1T Chimera 的继任者,R1T2 引入了“三脑”(Tri-Mind)架构,融合三个 DeepSeek 模型的核心能力:
- DeepSeek-R1-0528:提供最强推理能力
- DeepSeek-R1:确保逻辑清晰、语义连贯
- DeepSeek-V3-0324:带来更高的响应简洁性和执行效率
值得注意的是,R1T2 无需进一步微调或训练,便能继承 R1-0528 的推理能力、R1 的结构化表达风格以及 V3 的简洁指令导向行为。
这使得它在不牺牲智能表现的前提下,大幅降低了推理延迟和计算资源消耗。
📈 基准测试结果:智能与效率的平衡典范
根据 TNG 提供的评估数据,R1T2 在多个权威推理任务中表现亮眼:
| 测试集 | 表现对比 |
|---|---|
| AIME-24/25 | 接近 R1-0528 水平 |
| GPQA-Diamond | 达到 R1-0528 的 90%+ 得分 |
尽管 R1-0528 能生成更长、更详尽的答案,但 R1T2 更注重简洁性与效率,平均输出 token 数量减少约 60%,推理速度提升 200%。
这种优化尤其适用于需要快速响应、低延迟部署的企业级应用,如客服助手、自动化报告生成、代码理解等场景。
🌐 开源可用性与许可说明
R1T2 采用 MIT 许可协议,已正式发布于 Hugging Face 平台,允许自由用于商业用途。这意味着:
- 全球开发者和企业可以直接下载并部署
- 支持本地化私有部署,满足对数据安全敏感的应用需求
- 可基于模型进行定制化开发与二次训练
不过,TNG 也指出当前版本存在一些局限性:
- 不推荐用于高度依赖函数调用或工具集成的任务(因继承自 R1 的限制)
- 某些特定人格风格可能不如前代模型鲜明
未来版本有望逐步完善这些短板。
🇪🇺 合规提醒:欧盟 AI 法案即将生效
由于《欧盟人工智能法案》将于 2025 年 8 月 2 日 正式实施,TNG 建议所有位于欧盟境内的用户:
- 仔细阅读法案条款,评估合规风险
- 若无法满足要求,建议在 8 月 1 日后停止使用该模型
对于非欧盟地区运营的企业,则不受此限制,可在全球范围内灵活部署 R1T2,尤其是在美国及亚洲市场。
💼 对企业技术决策者的启示
对于 CTO、AI 平台负责人、工程主管和技术采购团队而言,R1T2 提供了以下几个方面的战略价值:
1. 更低的推理成本
- 输出 token 减少 60%,节省 GPU 时间与能耗
- 特别适合高吞吐量或实时交互场景
2. 无过高开销的高质量推理
- 继承 R1-0528 的推理能力,但避免冗长输出
- 更适合结构化任务(数学、编程、逻辑推理)
3. 完全开放与可定制性
- MIT 许可支持私有部署、模型调整和本地训练
- 为受监管行业提供更强可控性
4. 模块化趋势初现
- AoE 方法展示了如何通过重组现有模型优势来创建专用变体
- 为企业提供“无需从头训练”的模型演进路径
⚠️ 注意事项:
- 当前版本尚未优化函数调用与工具集成能力
- 依赖高级代理编排的系统应关注后续更新
关于 TNG Technology Consulting GmbH
TNG Technology Consulting 成立于 2001 年,总部位于德国巴伐利亚州,是一家专注于软件工程、AI和 DevOps/云服务的技术咨询公司。公司员工超过 900 人,技术背景深厚,博士比例高。
TNG 以技术创新和开源贡献著称,此次发布 R1T2 Chimera 及其底层技术论文,再次展现了其在 AI 模型融合领域的前沿探索。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...