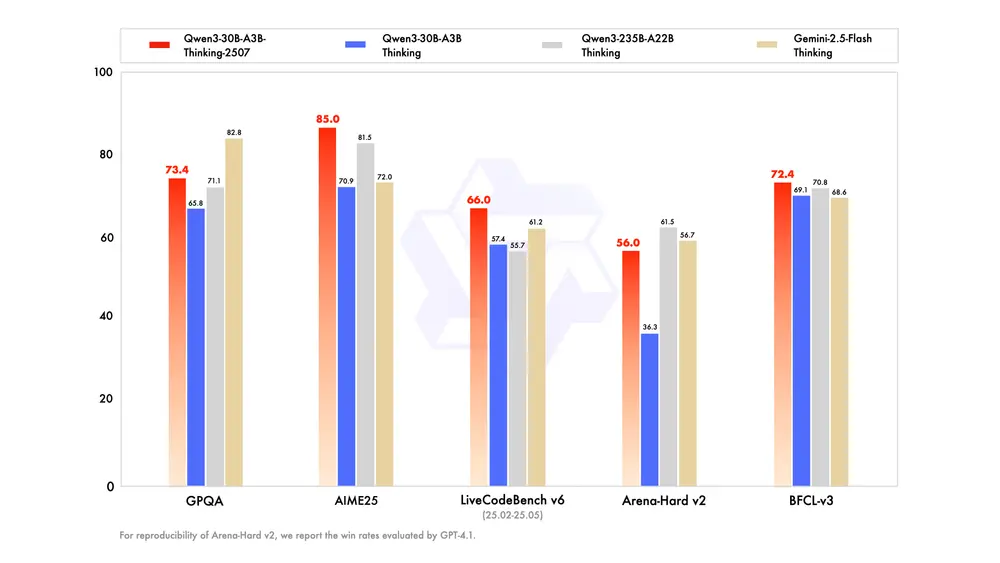
阿里通义千问团队再次升级其 30B 级模型线,正式推出 Qwen3-30B-A3B-Thinking-2507。
这并非一次简单迭代,而是针对复杂推理能力的深度优化版本。过去三个月中,项目组重点提升了模型在逻辑、数学、科学、编码等高阶任务上的表现,使其更接近“人类专家式思考”的行为模式。
- Qwen Chat:https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507
- Hugging Face:Qwen3-30B-A3B-Thinking-2507 | Qwen3-30B-A3B-Thinking-2507-FP8
- 魔塔:Qwen3-30B-A3B-Thinking-2507 | Qwen3-30B-A3B-Thinking-2507-FP8
- Ollama:https://ollama.com/library/qwen3:30b
如今,这个轻量级但高潜力的模型,已成为处理复杂问题的有力工具。
核心升级:专为“深度思考”而生
相比此前的非思考版本,Thinking-2507 在多个维度实现显著提升:
| 能力维度 | 提升表现 |
|---|---|
| 逻辑推理 | 更严密的因果链构建,减少跳跃性结论 |
| 数学与科学 | 在 Olympiad 级别题目中准确率明显上升 |
| 代码生成 | 能处理算法竞赛级问题,支持多步推导 |
| 通用能力 | 指令遵循、工具调用、文本生成更符合人类偏好 |
尤其在需要多步抽象、符号推理或领域专业知识的任务中,该模型展现出远超同类 30B 级模型的表现。
🔍 官方提示:强烈建议在高度复杂的推理任务中使用此版本。
模型概述
| 项目 | 参数 |
|---|---|
| 类型 | 因果语言模型(Decoder-only) |
| 训练阶段 | 预训练 + 后训练(含强化学习) |
| 总参数量 | 30.5B |
| 激活参数量 | 3.3B(MoE 架构,128 专家中激活 8 个) |
| 层数 | 48 |
| 注意力头数(GQA) | Query: 32,KV: 4 |
| 上下文长度 | 原生支持 262,144 tokens(约 256K) |
该模型采用与 Qwen3 系列一致的 混合专家(MoE)架构,在保持较低激活成本的同时,支持超长上下文理解,适用于整库分析、长文档推理等场景。
关键变化:仅支持“思考模式”
与之前的版本不同,Thinking-2507 版本仅支持思考模式,且已做默认集成:
- ✅ 不再需要手动设置
enable_thinking=True - ✅ 聊天模板自动注入
<think>标签
这意味着:
模型在收到输入后,会自动进入“内部推理”状态,生成 <think>...</think> 内容,但输出中可能只显示 </think>,而没有显式的开始标签——这是正常行为。
📌 示例输出结构:
</think> 根据题意,我们先列出方程组…… 最终答案是 \boxed{42}。
系统已自动补全 <think>,开发者无需干预。
最佳实践建议
为充分发挥模型潜力,官方推荐以下配置:
1. 采样参数
temperature: 0.6 # 降低随机性,提升推理稳定性
top_p: 0.95 # 广泛采样高质量候选
top_k: 20
min_p: 0 # 可选,配合 top_p 使用
presence_penalty: 0.5–1.5 # 减少重复生成(支持框架可用)
⚠️ 注意:
presence_penalty过高可能导致语言混合(如中英夹杂),建议根据任务微调。
2. 输出长度设置
- 一般任务:建议最大输出长度为 32,768 tokens
- 高度复杂任务(如数学竞赛、算法推导):建议提升至 81,920 tokens
长输出空间可让模型充分展开推理链,避免因截断导致结论不完整。
3. 标准化输出格式(适用于评测)
为便于评估和自动化解析,建议在提示词中加入标准化指令:
- 数学题:
“请逐步推理,并将最终答案放在 \boxed{} 中。”
- 选择题:
“请以 JSON 格式输出答案,仅包含字段:{"answer": "选项字母"},例如 {"answer": "C"}。”
这能显著提升模型输出的结构化程度和评测一致性。
多轮对话中的历史管理
在连续对话中,历史记录不应包含 <think> 内容。
正确的做法是:
- 保留用户输入和模型最终输出
- 忽略模型内部的思考过程(即
<think>...</think>部分)
✅ 该逻辑已在官方 Jinja2 聊天模板中实现。
但对于未使用标准模板的框架(如自定义 API 服务),开发者需自行剥离思考内容,否则可能引发上下文污染或无限递归。
适用场景
| 场景 | 推荐理由 |
|---|---|
| 数学/物理题解答 | 支持多步符号推理,输出可验证 |
| 编程竞赛辅助 | 能分析 LeetCode Hard 或 Codeforces 题目 |
| 科研文献理解 | 结合 256K 上下文,解析整篇论文 |
| 企业知识推理 | 在私有数据上做深度问答与决策支持 |
结语
Qwen3-30B-A3B-Thinking-2507 的发布,标志着 30B 级模型已不再局限于“快速响应”或“基础生成”,而是可以承担真正意义上的复杂推理任务。
它在性能、成本与能力之间找到了新的平衡点:
👉 不需要千亿参数,也能做深度思考;
👉 不依赖多卡集群,单卡即可部署;
👉 自动化思考流程,降低使用门槛。
对于希望在本地或私有环境中运行高推理质量模型的团队和个人来说,这是一个极具价值的选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











