
微软今天宣布推出 Phi 模型家族的最新成员 —— Phi-4-mini-flash-reasoning。这款模型专为计算、内存和延迟受限的场景设计,为边缘设备、移动应用等资源受限环境提供高效的推理能力。
该模型在 Phi-4-mini 的基础上进行了架构创新,采用全新的 SambaY 混合架构,实现了 高达10倍的吞吐量提升 和 平均2至3倍的延迟降低,推理速度显著提升,同时保持了强大的逻辑推理能力。

无妥协的效率:专为数学推理优化
Phi-4-mini-flash-reasoning 是一个 38亿参数 的开源模型,支持 64K token 上下文长度,专为数学推理任务设计。它通过高质量合成数据进行微调,在逻辑密集型任务中表现出色,适用于教育应用、实时逻辑推理等场景。
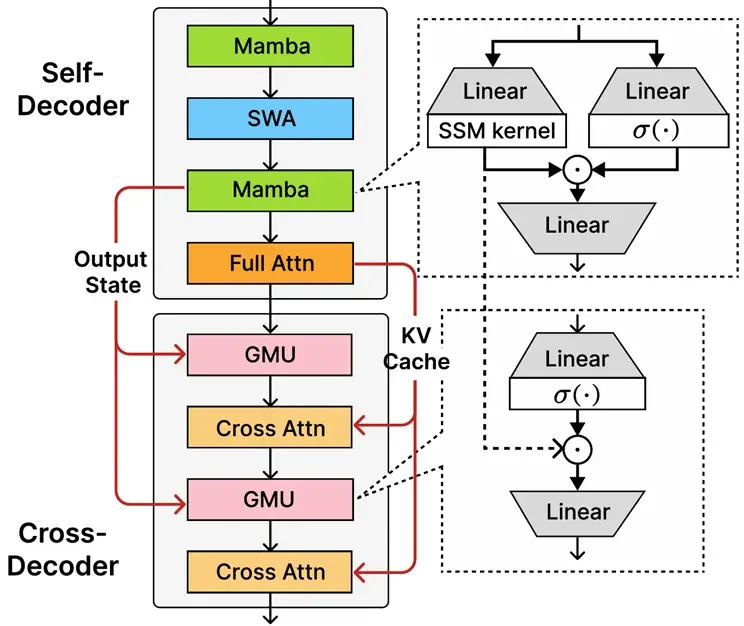
核心新特性:SambaY 混合架构
Phi-4-mini-flash-reasoning 的核心升级在于其全新架构 —— SambaY,该架构结合了以下关键技术:
- 门控内存单元(GMU):实现高效的层间信息共享。
- 混合解码器结构:结合状态空间模型(Mamba)与滑动窗口注意力(SWA)。
- 交叉解码器设计:融合全注意力机制与高效 GMU 模块。
SambaY 架构优势:
- 显著提升解码效率
- 保持线性预填充时间复杂度
- 支持更长上下文(最高64K token)
- 吞吐量提升最高达10倍
- 延迟随生成 token 数量增长接近线性,具备更强可扩展性
模型性能对比:小模型也有大能力
尽管只有38亿参数,Phi-4-mini-flash-reasoning 在多个数学推理基准测试中表现优异:
| 模型 | AIME24 | AIME25 | Math500 | GPQA Diamond |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 29.58 | 20.78 | 84.50 | 37.69 |
| DeepSeek-R1-Distill-Qwen-7B | 53.70 | 35.94 | 93.03 | 47.85 |
| DeepSeek-R1-Distill-Llama-8B | 43.96 | 27.34 | 87.48 | 45.83 |
| Phi4-mini-Reasoning (3.8B) | 48.13 | 31.77 | 91.20 | 44.51 |
| Phi4-mini-flash-reasoning (3.8B) | 52.29 | 33.59 | 92.45 | 45.08 |
在多个关键指标上,Phi-4-mini-flash-reasoning 已接近甚至超越部分更大模型,成为轻量级数学推理模型中的佼佼者。
主要使用场景
Phi-4-mini-flash-reasoning 专为以下场景设计:
- 形式证明生成
- 符号计算
- 高级文字题解析
- 多步骤数学推理
- 自适应学习系统
- 边缘设备推理助手
- 交互式辅导系统
该模型擅长在多步骤任务中保持上下文、应用结构化逻辑,并提供准确、可靠的推理结果。
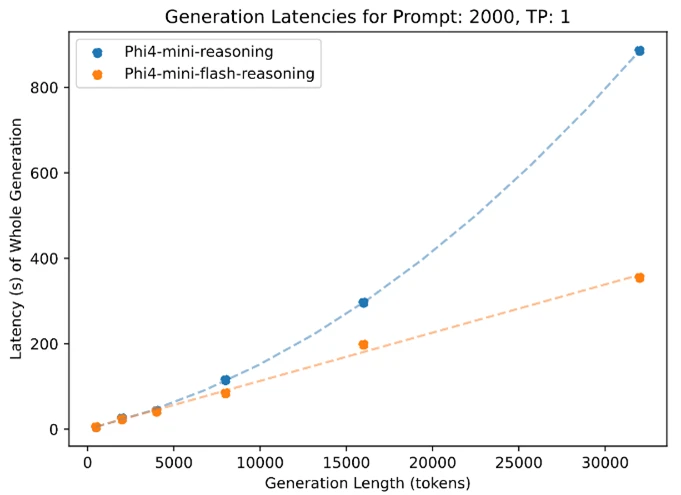
模型效率实测:低延迟、高吞吐
在英伟达A100-80GB GPU 上的测试显示:
- 在 2K提示长度 + 32K生成长度 的任务中,Phi-4-mini-flash-reasoning 吞吐量提升最高达10倍。
- 推理延迟随生成 token 数量增长接近线性,远优于前代模型的二次增长趋势。
这意味着,Phi-4-mini-flash-reasoning 在长上下文生成任务中具有更强的扩展性,非常适合部署在资源受限的边缘设备和移动应用中。
开发者友好:支持本地部署与微调
Phi-4-mini-flash-reasoning 支持高达 200064个 token 的词汇量,并提供可扩展的分词器模块,便于开发者进行下游任务的微调和扩展。
模型可在 单 GPU 上部署,适用于多种本地与边缘场景,是构建轻量级智能系统、教育工具和自动化推理平台的理想选择。
⚠️ 使用注意事项
该模型专为数学推理任务设计,未针对所有下游用途进行优化。开发者在部署前应评估以下方面:
- 模型准确性与逻辑可靠性
- 安全性与公平性
- 多语言性能差异
- 合规性(如隐私、数据使用法规)
微软建议在高风险场景中进行充分验证,并结合负责任 AI 实践进行部署。
微软对可信 AI 的承诺
微软始终致力于构建安全、隐私保护、可靠的 AI 系统。Phi 模型家族遵循微软 AI 原则开发,包括:
- 透明性
- 公平性
- 可靠性与安全性
- 隐私与安全
- 包容性
Phi-4-mini-flash-reasoning 通过 SFT、DPO、RLHF 等后训练策略,确保输出内容安全、有帮助,并覆盖广泛的安全类别。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











