
在当前大语言模型(LLM)领域中,解码器独占架构凭借其强大的生成能力成为主流。然而,经典的编码器-解码器架构——如 T5(文本到文本转换变换器)——因其出色的推理效率、灵活的设计以及对输入语义的深度理解能力,在许多现实任务中仍具有不可替代的优势。
为了进一步探索这一架构的潜力,谷歌推出了 T5Gemma 系列模型,这是基于预训练解码器模型(如 Gemma 2)通过“模型适配”方法构建的一整套新型编码器-解码器语言模型。它不仅继承了 Gemma 的高质量生成能力,还结合了 T5 架构的高效推理特性,为研究者和开发者带来了全新的质量与效率平衡方案。

技术核心:从解码器独占走向编码器-解码器
谷歌提出一个关键问题:
能否基于已有的解码器独占模型,构建出性能优异的编码器-解码器模型?
为此,T5Gemma 引入了一种名为“模型适配(Model Adaption)”的技术。该方法利用预训练的解码器模型权重来初始化编码器-解码器架构中的参数,并在此基础上进行进一步的预训练(基于 UL2 或 PrefixLM 目标),从而实现从单向解码器到双向架构的迁移。
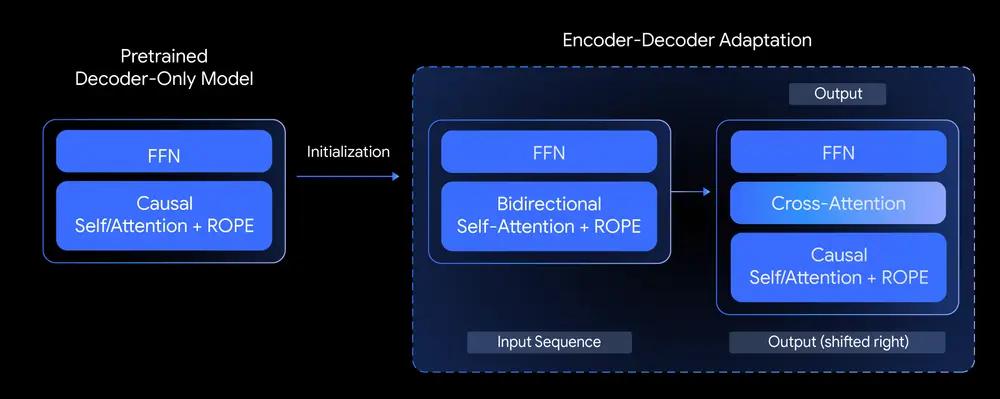
这种方法的优势在于:
- ✅ 节省训练成本:无需从头训练大规模模型;
- ✅ 保持知识连续性:复用已有解码器的知识库;
- ✅ 高度灵活:支持不同规模组合,例如 9B 编码器 + 2B 解码器。
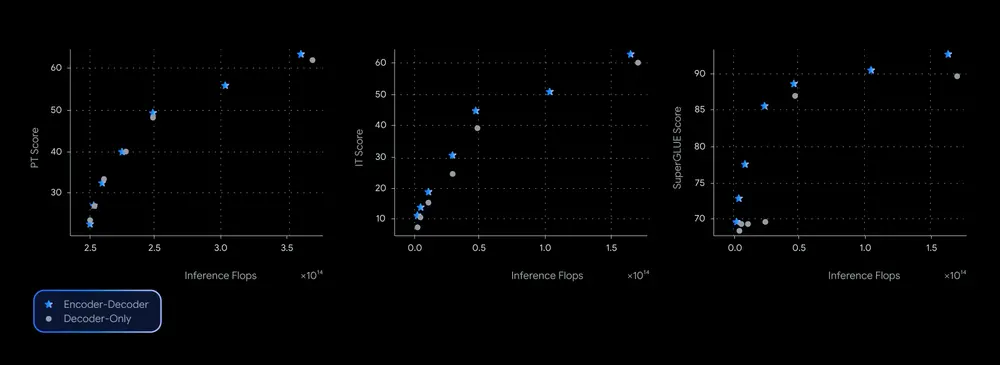
性能表现:质量与效率的帕累托前沿
在多个基准测试中(如 SuperGLUE、GSM8K 和 DROP),T5Gemma 表现出色,几乎主导了质量-效率权衡的帕累托前沿。具体表现为:
📊 GSM8K 数学推理任务:
| 模型 | 准确率 | 推理延迟 |
|---|---|---|
| Gemma 2 9B | 64.2% | 高 |
| T5Gemma 9B-9B | 73.4% | 相似 |
| T5Gemma 9B-2B | 70.7% | 近似于 Gemma 2 2B |
这表明:
- 在相似延迟下,T5Gemma 提供更高准确率;
- 非平衡架构(9B-2B)可显著提升小模型性能;
- 对于需要深入理解的任务(如摘要、翻译),编码器部分的作用尤为突出。
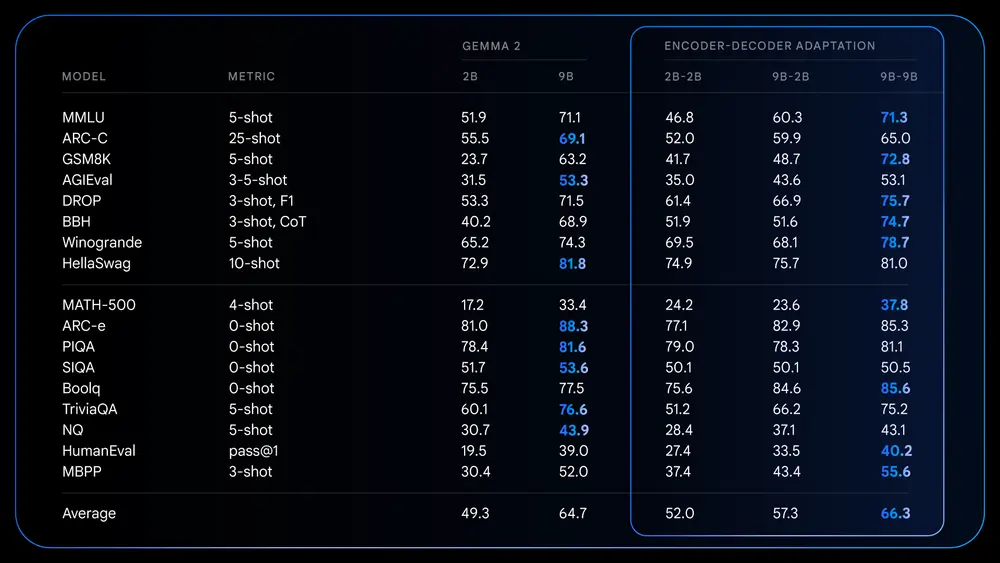
模型配置多样性
T5Gemma 提供多种变体,以满足不同场景需求:
| 类型 | 描述 |
|---|---|
| 模型规模 | 小型、基础、大型、超大型(T5 风格),以及 Gemma 2 2B 和 9B |
| 训练阶段 | 预训练模型、指令微调模型(IT 版本) |
| 非平衡架构 | 如 9B 编码器 + 2B 解码器,兼顾性能与效率 |
| 训练目标 | 支持 PrefixLM 和 UL2,分别侧重生成能力和表示学习 |
微调能力释放:更强的泛化与响应性
T5Gemma 不仅在预训练阶段表现出色,在指令微调后也展现出更强的能力提升。
| 模型 | MMLU 分数 | GSM8K 分数 |
|---|---|---|
| Gemma 2 2B IT | 51.3 | 58.0% |
| T5Gemma 2B-2B IT | 63.1 | 70.7% |
这说明:
- 适配后的架构为微调提供了更优起点;
- 指令响应更精准,最终模型更具实用性;
- 更适用于需要多步推理、复杂理解和任务分解的应用场景。
开源发布与资源支持
为推动社区研究和应用落地,谷歌正式发布了多个 T5Gemma 模型检查点,包括:
- 多种规模的 T5 规模模型(small, base, large, xlarge)
- 基于 Gemma 2 的适配模型(2B 和 9B)
- 中间规模模型(介于 T5 large 和 xlarge 之间)
- 支持 UL2 和 PrefixLM 训练目标
- 包含非平衡架构(如 9B-2B)
这些模型已在 Hugging Face 和 Kaggle 上开放下载。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











