
将自然语言数学语句自动转化为形式化代码(如 Lean 4)是计算数学中的核心挑战之一。尽管已有许多自动化工具尝试解决这一问题,但其准确性仍面临瓶颈,尤其是在需要深入理解语义的复杂场景中。
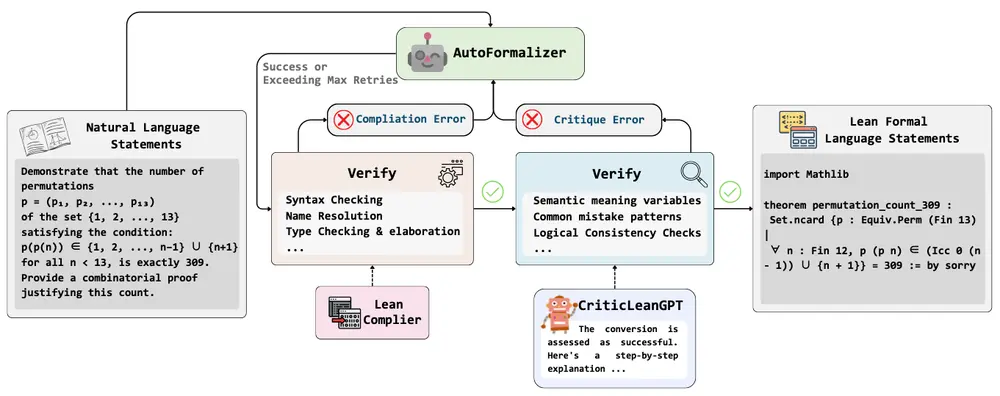
为此,字节跳动 Seed 项目组与南京大学联合提出了一种全新的解决方案——CriticLean 框架,首次系统性地引入“批判”机制,即在生成后阶段评估形式化结果是否准确反映原始数学意图。这一关键环节被证明对提高形式化的准确性和鲁棒性具有重要意义。
- GitHub:https://github.com/multimodal-art-projection/CriticLean
- 模型:https://huggingface.co/m-a-p/CriticLeanGPT-Qwen3-8B-RL
研究动机与挑战
现有自动形式化模型往往侧重于“生成”,而忽略了“验证”环节。然而,在面对复杂的数学语句时,仅靠生成器难以确保输出与原意一致。例如:
- 定义错误:变量使用不当或条件缺失
- 逻辑偏差:推理路径不完整或误用前提
- 形式表达不符:语法正确但语义不等价
因此,本文强调一个尚未被充分探索的环节:批判(Critic)阶段,即通过模型或系统对生成的结果进行语义一致性评估,从而筛选出更可靠的定理声明。
CriticLean 框架概述
CriticLean 的核心是一个基于强化学习训练的模型 CriticLeanGPT,专门用于判断自然语言数学语句与其对应的 Lean 4 表达之间的语义一致性。
该框架采用迭代优化流程,结合两个关键组件:
- Lean 编译器反馈:检查语法合法性;
- CriticLeanGPT 批判反馈:评估语义一致性;
通过不断修正和重生成,最终获得高质量的形式化结果。
数据集构建与模型训练
CriticLeanInstruct 数据集
为了支持模型训练,研究团队构建了多个数据子集,包括:
| 文件名 | 描述 |
|---|---|
CriticLean_12K | 所有批判 Lean 数据 |
CriticLean_4K | 种子数据,CriticLean_12K 子集,用于 RL 训练 |
CriticLean_Mix_48K | 混合数据,包含 CriticLean_12K + OpenR1-Math 18k + OpenThoughts 代码 18k |
CriticLean_Mix_16K | 小型混合数据集,含 CriticLean_4K + 数学与代码各 6k |
模型变体训练配置
基于上述数据集,研究人员训练了多个模型变体,部分代表性配置如下:
| 基础模型 | 是否 SFT | SFT 数据 | 是否 RL | RL 数据 | 模型名称 |
|---|---|---|---|---|---|
| Qwen2.5-Instruct | 是 | CriticLean_4K | 否 | - | Qwen2.5-Instruct-SFT (Critic Only) |
| Qwen2.5-Instruct | 是 | CriticLean_Mix_48K | 是 | CriticLean_4K | Qwen2.5-Instruct-SFT-RL |
| Qwen3 | 否 | - | 是 | CriticLean_4K | Qwen3-RL |
CriticLeanBench:首个面向语义一致性的形式化评估基准
为了评估批判模型的效果,研究团队推出了 CriticLeanBench,这是一个专为测试自然语言到 Lean 4 转换过程中语义一致性设计的综合基准。
特点
- 双重焦点:兼顾批判能力和 Lean 4 验证机制;
- 多样化覆盖:涵盖多个数学领域(代数、分析、集合论等);
- 结构化错误样本:模拟真实世界中常见的形式化错误;
- 人工验证:所有条目均经过专家审核,确保质量。
数据统计
| 类别 | 数量 |
|---|---|
| 总样本数 | 500 对 |
| 正确样本 | 250 对 |
| 错误样本 | 250 对 |
| 平均输入长度 | ~700 token |
每个条目包含:
- 自然语言数学语句
- 对应的 Lean 4 代码
- 是否语义正确的标签
- 错误注释(适用于错误样本)
推荐评估指标
- 准确率(ACC)
- 真阳性率(TPR)
- 假阳性率(FPR)
- 真阴性率(TNR)
- 假阴性率(FNR)
实验结果显示,CriticLeanGPT 在多项指标上超越了当前最先进的开源与闭源模型。
FineLeanCorpus:最大规模的已验证 Lean 4 数据集
基于 CriticLean 框架,研究团队进一步构建了 FineLeanCorpus,这是目前最大的高质量自然语言数学语句与 Lean 4 代码配对数据集。
核心特点
| 属性 | 内容 |
|---|---|
| 规模 | 285,957 条目 |
| 准确率 | 79.19%(手动抽样验证) |
| 多样性 | 覆盖多个数学领域与难度级别 |
| 验证方式 | Lean 编译器语法验证 + CriticLeanGPT 语义验证 |
该数据集不仅可用于训练形式化模型,还可作为评估、调试与改进自动定理证明系统的宝贵资源。
🔚 总结与展望
本研究通过引入批判机制,显著提升了自动形式化过程的可靠性。CriticLean 框架与相关数据集(CriticLeanBench 和 FineLeanCorpus)共同构成了一个完整的闭环系统,推动了自动定理证明领域的进步。
未来的研究方向包括:
- 扩展至更多形式化语言(如 Coq、Isabelle)
- 引入多轮交互式修正机制
- 结合大模型的自我反思与增强学习机制
如果你是 AI 数学、定理证明、形式化验证等领域的研究者或开发者,CriticLean 提供了一个值得深入探索的新范式。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











