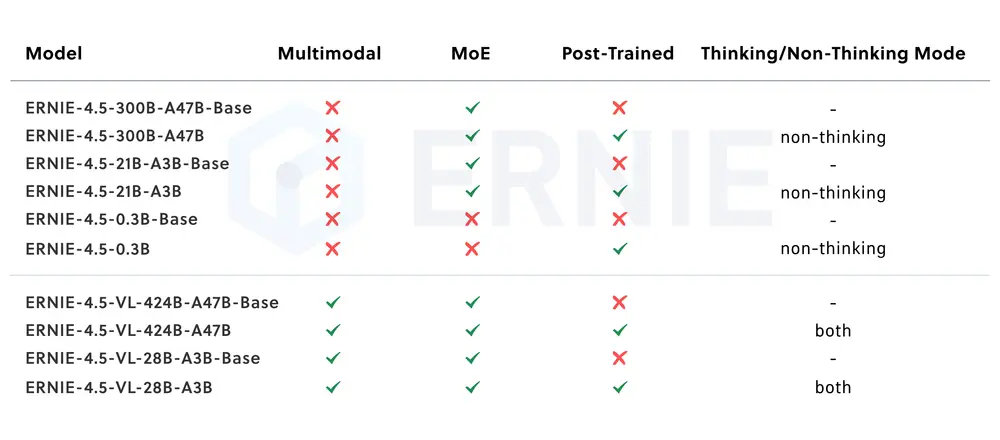
由清华大学交叉信息研究院、蚂蚁研究院、强化学习实验室与华盛顿大学的研究团队联合推出 ASearcher —— 一个面向大规模在线强化学习(Reinforcement Learning, RL)的开源搜索代理框架。
- GitHub:https://github.com/inclusionAI/ASearcher
- 模型:https://huggingface.co/collections/inclusionAI/asearcher-6891d8acad5ebc3a1e1fb2d1
该项目致力于提升搜索智能的自主决策能力,目标是让代理在复杂网络环境中实现接近专家水平的问题解决能力。所有组件完全开源,包括模型权重、训练方法、数据合成流程以及定制化开发指南,开发者可基于其架构低成本构建高性能搜索代理。
什么是 ASearcher?
ASearcher 是一个专为长时域、高复杂度网络搜索任务设计的强化学习代理系统。它不依赖外部大模型辅助决策,而是通过端到端的 RL 训练,自主完成从问题理解、工具调用到信息整合的全过程。
该框架的核心优势在于:
- 支持超长交互轨迹(超过 40 轮工具调用)
- 实现高效异步训练,最大化 GPU 利用率
- 提供完整的数据生成与训练闭环
- 所有模型和数据均已公开,便于复现与二次开发
项目代码、模型权重及数据集已发布于 Hugging Face,供研究者和开发者自由使用。
核心亮点
🔁 自主数据合成:构建高质量训练样本
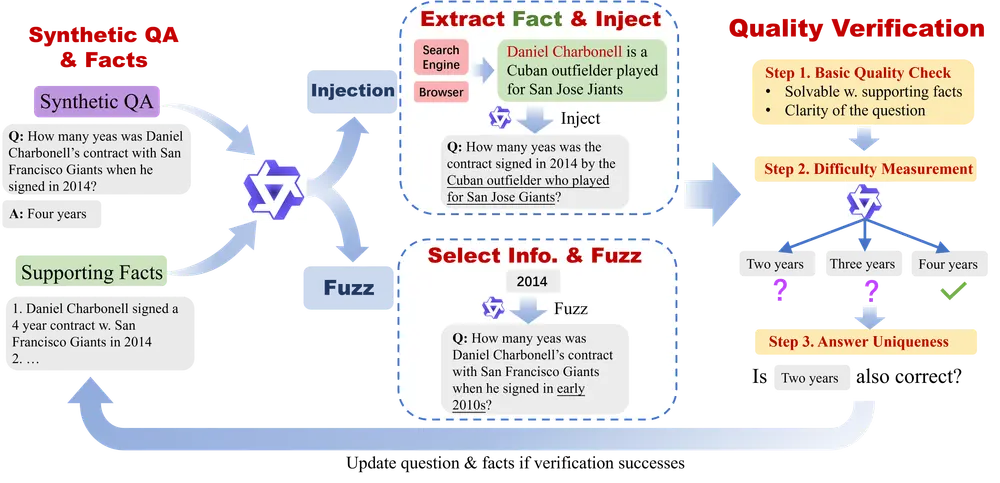
训练高性能搜索代理的一大挑战是缺乏足够多样且真实的训练数据。为此,团队设计了一个基于提示工程的 LLM 数据合成代理,能够自动生成具有挑战性的问答对(QA pairs)。
整个生成过程包含两个关键策略:
- 模糊化(Fuzzing)
对原始问题中的关键信息进行扰动或删除,增加不确定性。例如,“2023年诺贝尔物理学奖得主是谁?”可能被模糊为“去年某位科学家因量子技术获奖,他是谁?” - 上下文注入(Context Injection)
利用搜索引擎等工具检索相关事实,并将其嵌入问题背景中,提升问题复杂度和时效性。
每一对生成的 QA 都需经过三重验证机制:
- 质量检查:确保语言流畅、逻辑合理、时间准确;
- 难度验证:使用轻量级推理模型(LRM)尝试回答,若轻易答出则视为太简单;
- 答案唯一性验证:确认错误答案不具备合理性,防止歧义。
这一流程保障了训练数据的真实性与挑战性,有效支撑后续强化学习。
⚡ 完全异步 RL 架构:突破训练效率瓶颈
传统批处理式 RL 框架在面对搜索任务时存在明显短板:不同任务所需交互轮次差异巨大,短则几轮,长则数十轮。在同步训练中,整个批次必须等待最长轨迹完成,造成 GPU 大量空闲。
ASearcher 引入完全异步的强化学习架构,将轨迹收集与模型更新彻底解耦:
- 轨迹生成在多个分布式环境中并行执行;
- 模型训练独立进行,随时吸收新数据;
- 无需等待批次完成,显著提升 GPU 利用率。
这种设计使得系统可以支持极长时域的搜索行为。实验显示,ASearcher-Web-QwQ 在单次任务中最多调用工具 40 轮以上,累计生成 token 数超过 15万,远超同类系统。
🌐 长时域搜索能力:真正“会查资料”的代理
搜索代理的关键能力不是一次点击,而是持续探索、验证、修正路径。ASearcher 通过强化学习训练,使代理具备以下能力:
- 多轮次迭代查询,逐步缩小答案范围;
- 根据反馈调整关键词和检索策略;
- 综合多个网页片段形成最终结论。
这使其在处理模糊、多跳、时效性强的问题时表现尤为突出。
性能表现:多项基准领先
研究团队在三个主流搜索代理评测基准上进行了系统评估:GAIA、xBench-DeepSearch 和 Frames。这些基准强调真实网络交互能力,测试代理是否能通过主动搜索获取超出其内部知识的信息。
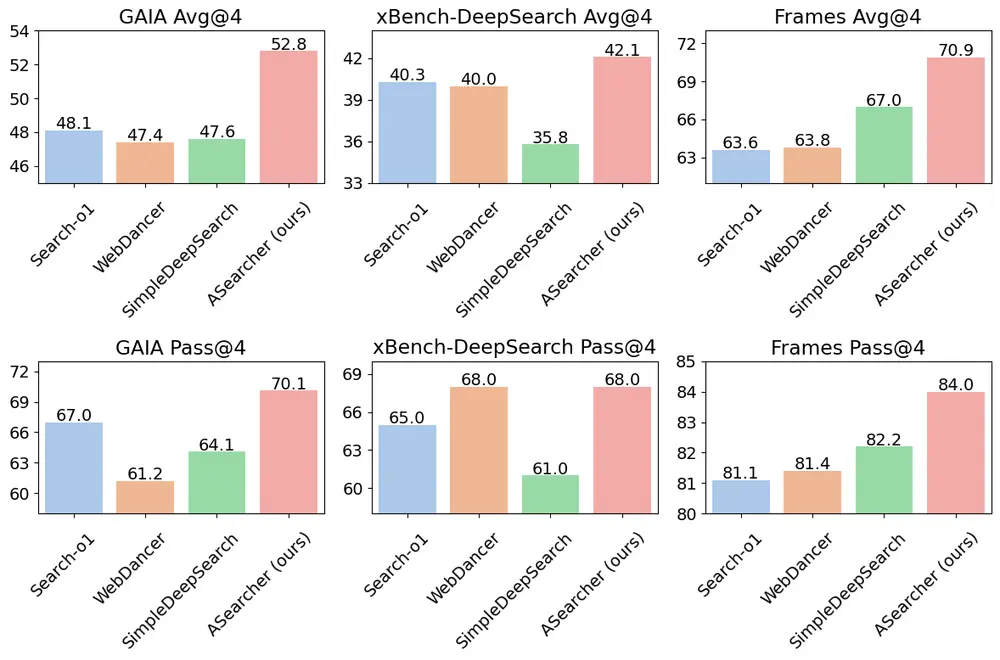
主要结果如下:
| 基准 | Avg@4 分数 | Pass@4 分数 |
|---|---|---|
| GAIA | 52.8(+9.1↑) | 70.1 |
| xBench-DeepSearch | 42.1(+13.4↑) | 68.0 |
| Frames | 70.9(+12.0↑) | 84.0 |
注:↑ 表示相比监督微调阶段的提升幅度
- 在 GAIA 和 xBench-DeepSearch 上,ASearcher-Web-QwQ 取得当前开源代理中的最高 Avg@4 成绩;
- 在通过率(Pass@4)方面也全面领先,尤其在 xBench 上相比基线提升达 17.0 个百分点;
- 所有性能提升均来自纯强化学习训练,未引入额外推理模型或人工标注。
这表明,强化学习本身显著增强了代理的搜索策略优化能力。
开源承诺:全栈开放,助力社区发展
ASearcher 的核心理念是“可复现、可扩展、可定制”。为此,团队公开了全部关键组件:
✅ 模型权重(基于 QwQ 架构微调)
✅ 数据合成代理的提示模板与运行逻辑
✅ 强化学习训练细节(奖励函数、策略网络结构、超参设置)
✅ 分布式训练与异步采样实现方案
✅ 定制代理开发指南(从环境搭建到部署)
研究人员可直接复现实验,企业开发者也可基于此构建垂直领域的搜索助手,如金融信息检索、法律条文查询等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











