中国人民大学高岭人工智能学院、百度公司和卡内基梅隆大学的研究人员推出新型段落排序模型 ReasonRank,通过强大的推理能力提升段落排序任务的性能。该模型通过引入推理能力,能够更好地理解查询意图,并在多个段落中进行推理,从而实现更准确的排序。这一研究解决了现有段落排序模型在复杂推理场景中表现不佳的问题。
- GitHub:https://github.com/8421BCD/ReasonRank
- reasonrank-7B:https://huggingface.co/liuwenhan/reasonrank-7B
- reasonrank-32B:https://huggingface.co/liuwenhan/reasonrank-32B
例如,在复杂的问答任务中,用户可能提出一个需要多步推理才能回答的问题,如“为什么头发会变灰或变白,为什么有些人变灰的时间更晚?”ReasonRank 能够通过推理理解问题背后的生物学机制,并从多个段落中找到最相关的答案。
主要功能
- 推理能力增强:ReasonRank 通过推理能力提升段落排序的准确性,能够处理复杂的查询任务。
- 多步推理:支持在测试时进行多步推理,生成更准确的排序结果。
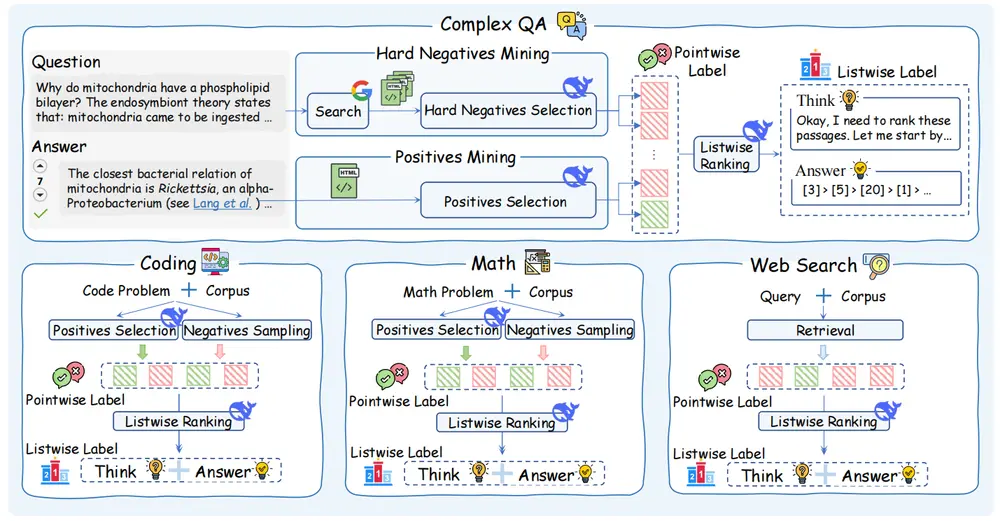
- 自动数据合成:提出了一种自动化推理密集型训练数据合成框架,从多个领域生成高质量的训练数据。
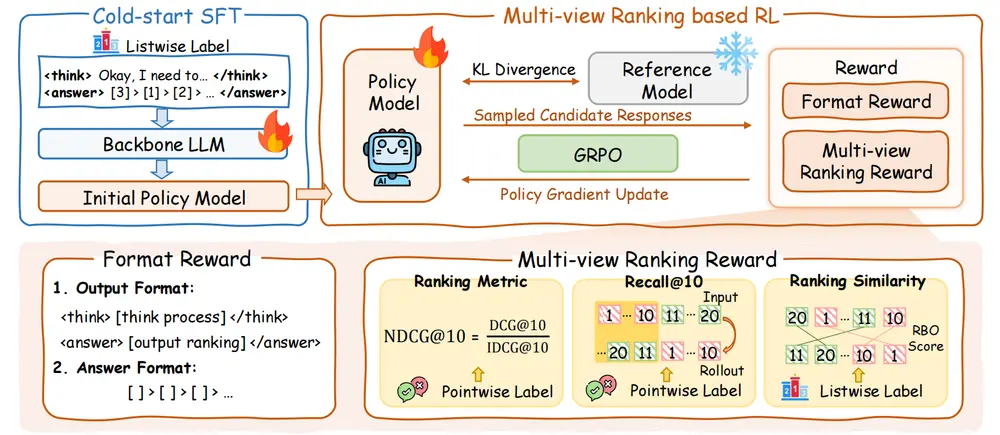
- 两阶段训练:包括冷启动监督微调(SFT)和基于多视图排名奖励的强化学习(RL),进一步提升模型的排序能力。
主要特点
- 推理密集型数据合成:通过自动化框架生成 13K 高质量推理密集型训练数据,涵盖复杂问答、编程、数学和网络搜索等多个领域。
- 两阶段训练框架:
- 冷启动 SFT:帮助模型学习推理模式和黄金排序列表。
- 多视图排名奖励的 RL:通过多视图排名奖励(NDCG@10、Recall@10 和 RBO)进一步优化模型的排序能力。
- 高效推理:尽管 ReasonRank 引入了推理能力,但其推理效率比传统的点式重排序器更高。
工作原理
- 推理密集型数据合成:
- 从多个领域(如复杂问答、编程、数学和网络搜索)收集用户查询。
- 使用强大的推理模型 DeepSeek-R1 自动生成高质量的训练标签,包括推理链和黄金排序列表。
- 设计自一致性数据过滤机制,确保数据质量。
- 两阶段训练框架:
- 冷启动 SFT:使用推理链和黄金排序列表对模型进行监督微调,帮助模型学习推理模式。
- 多视图排名奖励的 RL:通过多视图排名奖励(NDCG@10、Recall@10 和 RBO)进一步优化模型的排序能力。
- 推理过程:
- 在推理时,ReasonRank 会生成推理链,解释为什么某些段落更相关,然后输出排序结果。
测试结果
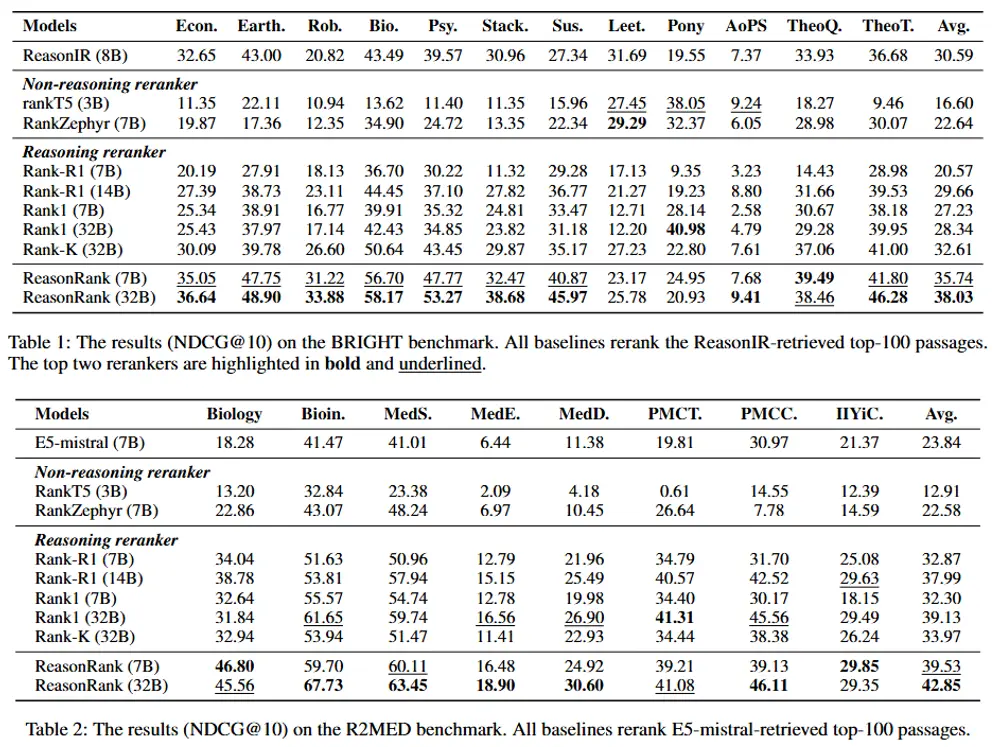
- BRIGHT 基准测试:
- ReasonRank (7B) 和 ReasonRank (32B) 在 BRIGHT 基准测试中显著优于所有基线模型。
- ReasonRank (32B) 的平均 NDCG@10 分数为 38.03,比之前的最佳模型 Rank-K (32B) 高出约 5 个点。
- ReasonRank (7B) 的平均 NDCG@10 分数为 35.74,甚至超过了 32B 规模的基线模型。
- R2MED 基准测试:
- ReasonRank (32B) 在 R2MED 基准测试中也表现出色,平均 NDCG@10 分数为 42.85,比 Rank1 (32B) 高出约 4 个点。
- BEIR 基准测试:
- ReasonRank (32B) 在 BEIR 基准测试中也表现出色,平均 NDCG@10 分数为 55.44,优于所有基线模型。
- 效率分析:
- ReasonRank (7B) 的推理延迟比 Rank1 (7B) 快 2-2.7 倍,显示出更高的效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











