
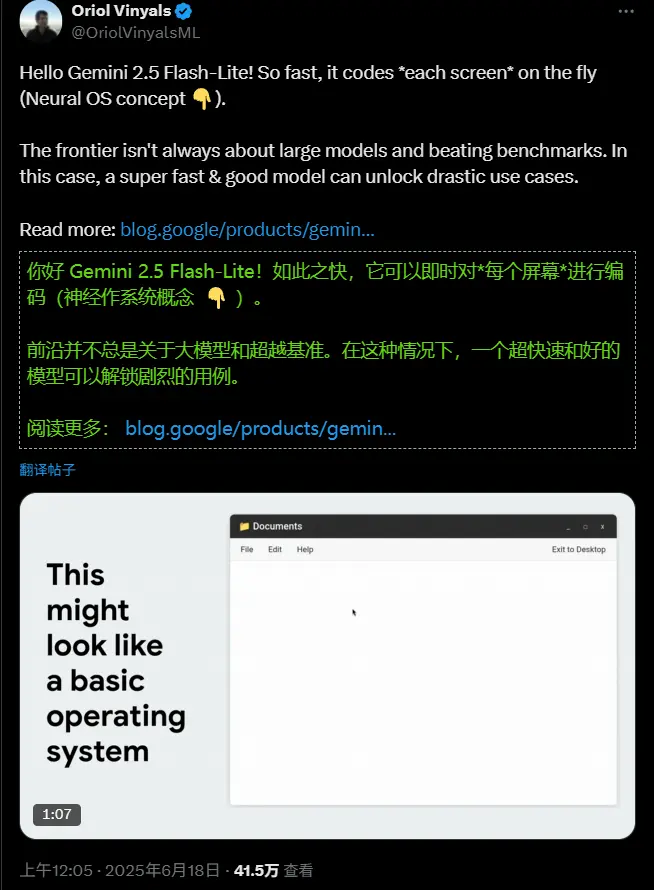
在传统图形用户界面(GUI)中,按钮、菜单和窗口都是预先编码的静态元素。但设想一种系统——每次点击后,整个界面由 AI 实时生成,根据上下文动态演化。这不是科幻,而是谷歌最新探索的方向。
谷歌近日公开一个研究原型项目,展示了一种基于大型语言模型的“生成式操作系统”概念。该原型已在 Google AI Studio 上线演示应用,旨在探索未来人机交互的新范式。
核心目标是:让计算机不再只是执行命令,而是持续理解意图并实时构建响应式界面。
技术基础:Gemini 2.5 Flash-Lite 驱动即时响应
该原型采用 Gemini 2.5 Flash-Lite 模型作为引擎。这款轻量级模型具备极低延迟特性,能够在数百毫秒内完成推理,是实现“感觉即时”的关键。
与传统 UI 不同,这里的每一屏内容都由模型按需生成。用户并非在一个固定文件系统中导航,而是在与一个不断被构建和重构的环境互动。
如何控制生成?双层提示架构
为了确保生成结果既灵活又可控,团队设计了两部分输入结构:
1. UI 宪法(UI Constitution)
这是一个固定的系统级提示,定义全局规则,例如:
- 操作系统的整体视觉风格;
- 主屏幕布局格式;
- 特定组件(如地图、时间线)的嵌入逻辑。
它相当于“宪法”,保证跨会话的一致性。
2. UI 交互(UI Interaction)
以 JSON 格式记录用户的最近操作,如“点击‘保存笔记’图标”。这个动态输入作为查询,触发模型生成下一个界面。
通过将“宪法”与“事件”结合,模型能在遵循设计规范的同时,对用户行为做出个性化响应。
上下文感知:交互历史追踪
单次点击只能提供有限信息,但连续操作构成了任务流。为此,原型引入了 N 步交互追踪机制,保留最近的操作序列作为上下文。
这意味着:
- 在计算器中输入数字时,若前序操作来自购物车页面,可能优先显示折扣计算;
- 若来自旅行应用,则自动关联汇率换算。
通过调节追踪长度,可在上下文相关性与界面稳定性之间取得平衡。
流式渲染:让用户“看见”生成过程**
等待完整 HTML 输出再渲染会导致明显延迟。为此,团队采用流式传输 + 渐进渲染策略:
- Gemini 分块输出 HTML 片段;
- 前端持续接收并追加至 React 状态;
- 浏览器原生解析器即时解析有效标签,逐步呈现内容。
对用户而言,界面仿佛从空白中“生长”出来,显著提升响应感和参与度。
引入状态性:构建生成式 UI 图**
默认情况下,每次访问同一路径都会重新生成界面,导致非确定性体验(例如两次打开“文档夹”看到不同内容)。这虽具创造性,但不符合用户对稳定性的预期。
为此,原型支持构建 UI 图(UI Graph):
- 已生成的界面缓存在内存中;
- 再次访问时直接复用,无需重复调用模型;
- 新操作则扩展图谱,实现渐进式记忆。
这种方式在保留生成自由度的同时,提供了类似传统 GUI 的状态一致性,且避免了降低采样温度带来的质量下降问题。
潜在应用场景
尽管目前仅为实验性质,这一框架为未来产品带来多种可能性:
- 上下文智能面板:当检测到用户频繁比价航班时,自动弹出浮动控件,集成价格对比、预订直达等动态按钮,减少跳转步骤。
- 现有应用中的“生成模式”:在 Google Calendar 中启用后,移动会议邀请时,系统可自动生成包含“可用时间段推荐”的交互屏,参与者空闲时间以可点击按钮形式呈现,替代传统表单。
- 混合式 UI 架构:静态功能区 + 动态生成模块共存,兼顾稳定性与灵活性,适用于复杂工作流场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











