实时文本转语音(TTS)技术在智能助手、实时播报、大模型交互等场景中有着极高的需求,但传统模型往往面临“延迟高”“长文本生成不稳定”“流式输入支持差”等痛点。
微软推出了一款轻量级实时TTS模型——VibeVoice-Realtime,其以300毫秒级的首次可听延迟、流式文本输入支持和稳定的长语音生成能力,为实时语音交互场景提供了新的解决方案。
- 项目主页:https://microsoft.github.io/VibeVoice
- GitHub:https://github.com/microsoft/VibeVoice/blob/main/docs/vibevoice-realtime-0.5b.md
- 模型:https://huggingface.co/microsoft/VibeVoice-Realtime-0.5B
该模型可广泛应用于实时TTS服务搭建、实时数据流播报,尤其能与大语言模型(LLM)深度适配:在LLM生成完整答案前,从第一个令牌开始就能发声,大幅提升交互流畅度。其轻量化设计(5亿参数)也降低了部署门槛,让开发者能快速集成到各类应用中。

核心技术:交错窗口化设计,平衡延迟与生成质量
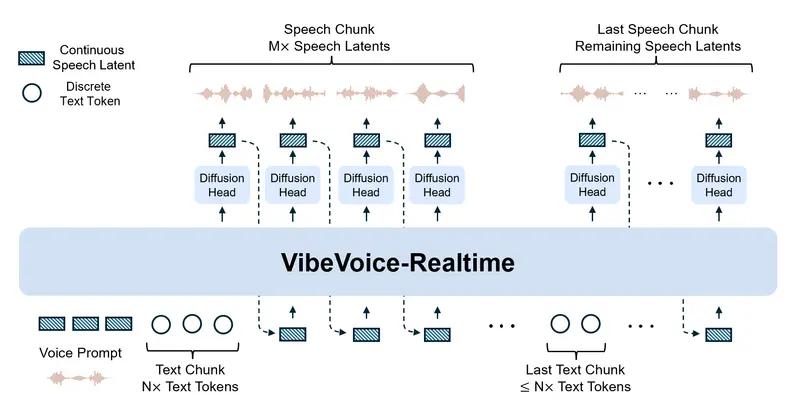
VibeVoice-Realtime的核心优势源于其创新的技术架构,尤其是“交错窗口化设计”和高效的分词器方案,既保证了低延迟,又兼顾了长文本生成的稳定性:
- 交错窗口化设计:模型采用“增量编码+并行生成”的双轨机制——在持续接收并编码输入文本片段(流式输入)的同时,基于已有的上下文信息,并行进行扩散模型驱动的声学潜在表示生成。这种设计避免了传统流式TTS“等待完整文本片段”的延迟问题,实现了“边输入边生成”。
- 高效声学分词器:与多说话人长语音变体不同,该流式模型移除了语义分词器,仅依赖声学分词器工作。更关键的是,该分词器采用超低帧率(7.5 Hz)运行,在保证语音质量的前提下,大幅降低了计算开销,为300毫秒低延迟提供了技术支撑。
关键特性与参数:轻量化、低延迟、强适配
VibeVoice-Realtime的特性的围绕“实时性”和“实用性”展开,参数设计兼顾了性能与部署成本:
| 特性维度 | 具体参数/说明 | 核心价值 |
|---|---|---|
| 参数量 | 5亿 | 轻量化设计,便于快速部署到各类设备(含边缘设备) |
| 首次可听延迟 | 约300毫秒(取决于硬件) | 接近人类对话反应速度,提升实时交互体验 |
| 流式文本输入 | 支持持续输入文本片段,无需等待完整文本,适配实时数据流场景 | |
| 稳定的长语音生成 | 避免长文本生成时的音质衰减、断句混乱等问题 | |
| 单一说话人 | 聚焦实时场景,简化模型架构以降低延迟(多说话人需用其他变体) | |
| 仅支持英语 | 适配英语实时交互场景,其他语言暂不推荐 |
性能实测:在长文本与短句场景均表现优异
微软公布的测试数据显示,VibeVoice-Realtime在两大权威基准测试(LibriSpeech test-clean、SEED test-en)中,均展现出与主流TTS模型相当甚至更优的性能,尤其在说话人相似度指标上表现突出:
1. LibriSpeech test-clean(零样本TTS)
| 模型 | WER(词错误率)↓ | 说话人相似度 ↑ |
|---|---|---|
| VALL-E 2 | 2.40% | 0.643 |
| Voicebox | 1.90% | 0.662 |
| MELLE | 2.10% | 0.625 |
| VibeVoice-Realtime-0.5B | 2.00% | 0.695 |
| 注:WER越低表示语音识别准确率越高,说话人相似度越高表示合成语音越自然。 |
2. SEED test-en(零样本TTS)
| 模型 | WER(词错误率)↓ | 说话人相似度 ↑ |
|---|---|---|
| MaskGCT | 2.62% | 0.714 |
| Seed-TTS | 2.25% | 0.762 |
| FireRedTTS | 3.82% | 0.460 |
| SparkTTS | 1.98% | 0.584 |
| CosyVoice2 | 2.57% | 0.652 |
| VibeVoice-Realtime-0.5B | 2.05% | 0.633 |
从数据来看,VibeVoice-Realtime在WER指标上处于行业前列,说话人相似度更是在LibriSpeech测试中超越了VALL-E 2、Voicebox等知名模型,说明其合成语音的自然度和辨识度表现出色。同时,该模型更侧重于长语音生成,解决了传统流式TTS长文本生成不稳定的痛点。
应用场景:实时交互场景的理想选择
基于“低延迟、流式输入、长文本稳定生成”的核心特性,VibeVoice-Realtime可适配以下三类核心场景:
- 实时TTS服务搭建:如智能客服、语音助手等场景,用户输入文本后可即时听到回应,无需等待完整文本处理,提升交互流畅度。
- 实时数据流播报:如金融行情、体育赛事比分、新闻快讯等实时更新的内容,可通过流式输入持续生成语音,实现“边更新边播报”。
- LLM实时语音交互:与大语言模型集成后,LLM无需生成完整答案即可从第一个令牌开始发声,缩短用户等待时间,让AI对话更接近人类交流节奏。
待办事项:未来功能扩展方向
目前VibeVoice-Realtime仍处于持续优化阶段,微软公布的待办事项包括:
- 扩展可用说话人/音色库,满足更多个性化语音需求;
- 完善流式文本输入功能,支持在音频生成过程中持续输入新令牌;
- 将模型集成至HuggingFace官方transformers库,降低开发者集成门槛。
风险与限制:使用前需注意这些问题
尽管性能优异,VibeVoice-Realtime仍存在一些限制,使用时需格外注意:
- 深度伪造与虚假信息风险:高质量合成语音可能被滥用于冒充、欺诈等场景。用户需确保文本来源可靠,遵守相关法律法规,分享AI生成内容时建议披露其AI属性。
- 语言与内容限制:仅支持英语输入,非英语文本可能导致异常输出;不支持朗读代码、数学公式、特殊符号,极短输入(3个词及以下)可能影响生成稳定性,需提前预处理文本。
- 使用范围限制:目前仅适用于研究和开发目的,不建议未经进一步测试就用于商业或现实世界应用。
- 模型偏见继承:继承了基础模型(Qwen2.5 0.5B)可能存在的偏见、错误或遗漏,生成内容可能存在不准确或有偏见的情况。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...