在播客制作、智能客服和实时对话系统中,自然流畅的多说话人语音合成是一项关键能力。然而,当前主流的对话式TTS(Text-to-Speech)技术普遍存在几个核心问题:
- 需要预先提供完整对话文本,无法支持边输入边生成;
- 所有角色语音混合输出,缺乏清晰的角色区分;
- 说话人切换生硬,语调不连贯,情感表达机械;
- 合成过程不稳定,难以适应长时间、多轮次交互场景。
为解决这些问题,小红书FireRed项目组推出了 FireRedTTS-2 —— 一种专为长篇、多说话人对话设计的流式语音合成系统。它不仅支持实时逐句生成,还能保持上下文感知的韵律控制与稳定的说话人身份切换,已在播客生成和聊天机器人等实际场景中验证其有效性。
- 项目主页:https://fireredteam.github.io/demos/firered_tts_2
- GitHub:https://github.com/FireRedTeam/FireRedTTS2
- 模型:https://huggingface.co/FireRedTeam/FireRedTTS2
- Demo:https://huggingface.co/spaces/FireRedTeam/FireRedTTS2
核心能力概览
| 特性 | 说明 |
|---|---|
| 支持长对话 | 当前支持最长3分钟、4人参与的连续对话语音生成,可通过扩展数据进一步延长 |
| 多语言兼容 | 覆盖中、英、日、韩、法、德、俄等多种语言,支持跨语言对话与代码切换下的零样本语音克隆 |
| 实时低延迟 | 基于12.5Hz流式语音标记器,在L20 GPU上首包延迟低至140ms |
| 稳定高质量 | 在WER/CER、相似度等指标上表现优异,适用于独白与复杂对话场景 |
| 可控音色生成 | 支持随机音色生成,可用于ASR训练或语音交互测试 |
关键技术突破
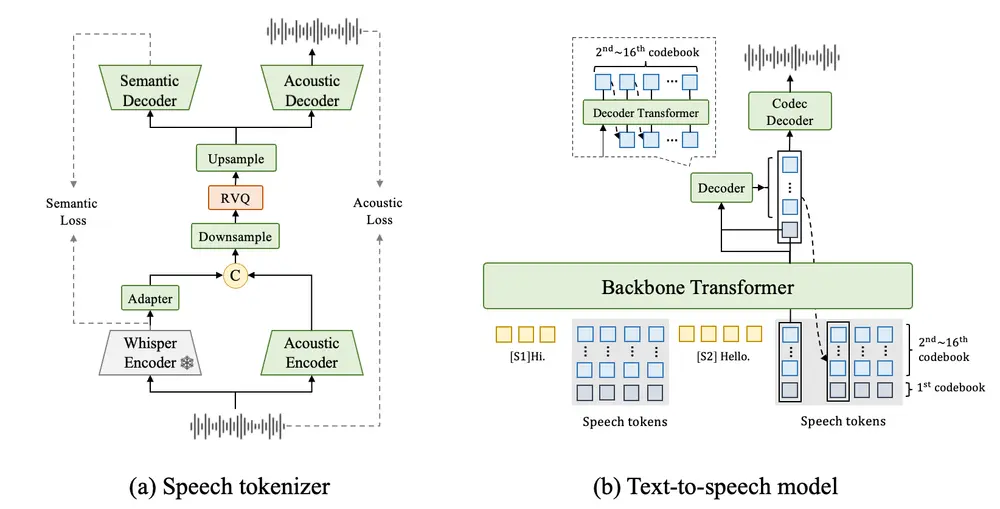
1. 流式语音标记器:提升效率与建模稳定性
FireRedTTS-2引入了新型 12.5Hz流式语音标记器,相较于传统更高频率的标记方案(如50Hz),该设计显著降低了序列长度,从而加快训练和推理速度,同时延长了最大可处理对话长度。
更重要的是,较低采样率有助于捕捉更稳定的语音语义特征,减少噪声干扰,使文本到语音标记的映射更加鲁棒,尤其适用于长上下文建模。
2. 文本-语音交错建模架构
系统采用“文本-语音交错序列”作为输入格式:每段带说话人标签的文本后接对应时间对齐的语音标记,按时间顺序排列。这种结构天然保留了对话的时间动态与角色轮替信息。
在此基础上,FireRedTTS-2使用双变换器架构进行建模:
- 第一层:大型仅解码器变换器
负责从历史上下文中预测当前语音标记,具备强大的上下文理解能力。 - 后续层:轻量级变换器
在已知部分输出的基础上精炼结果,降低计算开销,提升推理效率。
这一分层策略兼顾了建模深度与实时性能,实现了高质量与低延迟的平衡。
应用场景与优势体现
场景一:播客内容自动生成
传统播客制作依赖真人录制,成本高且周期长。FireRedTTS-2可在无需人工配音的情况下,自动生成多人访谈类音频内容。
实验显示,在零样本设置下,FireRedTTS-2在以下方面优于现有系统(MoonCast、ZipVoice-Dialog、MOSS-TTSD):
- 更高的语音清晰度(WER更低)
- 更可靠的说话人轮换识别
- 更自然的语调变化(上下文一致的韵律表现)
听众能清楚分辨不同角色,并感受到符合语境的情绪起伏。
场景二:实时聊天机器人集成
对于需要即时响应的对话系统(如虚拟助手、AI陪聊),FireRedTTS-2支持逐句流式生成,无需等待整个对话结束即可开始发声。
通过微调,模型可根据隐含上下文线索自动调整语气与情感。例如:
- 对方表达惊讶时,回应语气也呈现相应的情绪张力;
- 连续提问时保持适度紧迫感,而非机械重复。
在情感控制任务中,“惊喜”、“疑问”、“高兴”等六类情绪的识别与再现准确率均达到较高水平(其中“惊喜”达83.3%),显著提升了交互的真实感。
实测表现:全面超越现有方案
1. 语音标记器性能(LibriSpeech测试集)
| 指标 | 表现 |
|---|---|
| WER(词错误率) | 最低,优于对比模型 |
| 语音可理解性 | 主观评分领先 |
| 说话人相似度 | 接近真实录音 |
| 音质 MOS | 处于第一梯队 |
2. 语音克隆能力(SeedTTS-eval基准)
在普通话与英语的零样本语音克隆任务中,FireRedTTS-2生成的声音在自然度与身份一致性方面接近人类录音水平,展现出强泛化能力。
3. 播客生成对比(零样本)
相比MoonCast、ZipVoice-Dialog和MOSS-TTSD,FireRedTTS-2在以下维度全面占优:
- 客观清晰度(WER ↓)
- 角色辨识准确率(↑)
- 主观自然度评分(MOS ↑)
特别是在长对话中,未出现明显失真或节奏断裂现象。
未来展望
FireRedTTS-2目前主要服务于小红书内部的播客生成与对话类产品,但其开放架构具备良好的扩展潜力:
- 可通过增加训练数据支持更多说话人(>4人)与更长对话(>5分钟);
- 支持定制化音色入库,满足品牌化语音需求;
- 结合ASR与NLP模块,构建端到端的全自动对话生产流水线。
随着多模态交互需求的增长,能够稳定处理长上下文、支持实时流式输出的TTS系统将成为下一代人机交互的重要基础设施。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...