西北工业大学、Soul AI 实验室与上海交通大学联合推出 SoulX-Podcast —— 一个专为长篇、多轮次、多说话者对话场景设计的语音合成系统。它不仅能生成高质量的播客风格对话语音,也在传统单说话者语音合成任务中表现优异。
- 项目主页:https://soul-ailab.github.io/soulx-podcast
- GitHub:https://github.com/Soul-AILab/SoulX-Podcast
- 模型:https://huggingface.co/collections/Soul-AILab/soulx-podcast
与主流语音合成系统聚焦于单人独白不同,SoulX-Podcast 的核心目标是模拟真实播客中的自然对话:多人交替发言、语调随语境变化、夹杂笑声或叹息等副语言特征,并支持多种语言与方言。
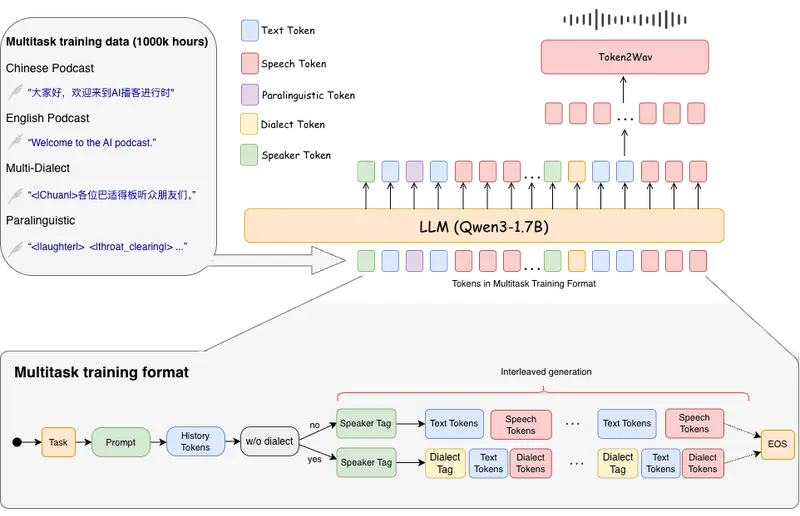
核心能力
- 多说话者对话生成
支持生成连贯的多轮次对话,每位说话者拥有稳定的声音特征,对话节奏自然,适用于播客、有声剧等场景。 - 多方言与多语言支持
除普通话和英语外,还支持四川话、河南话和粤语。系统可在无目标方言语音样本的情况下,通过文本提示生成对应方言语音(零样本跨方言克隆)。 - 副语言控制
可精确控制笑声、叹气、清嗓等非语言发声事件,显著提升语音的真实感和表现力。 - 零样本语音合成
无需目标说话者的语音样本,仅凭文本即可生成具有个性特征的高质量语音。
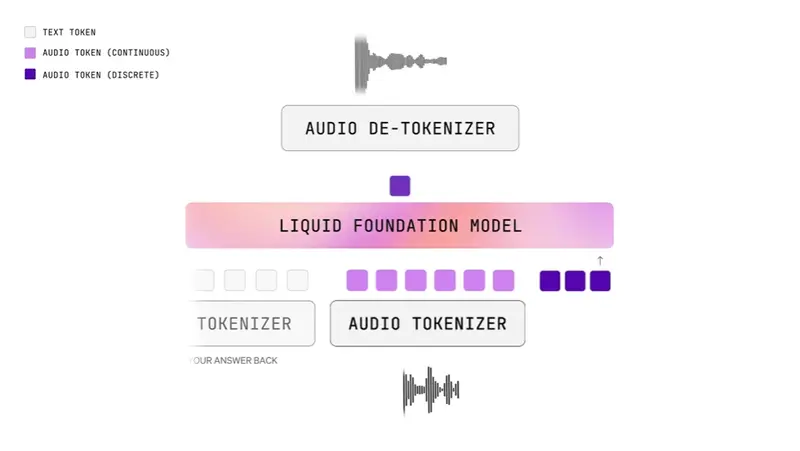
技术实现
SoulX-Podcast 采用两阶段生成架构:
- 文本 → 语义标记:基于预训练大语言模型(LLM),将输入文本(含说话人标识、副语言指令等)转化为语义标记序列。
- 语义标记 → 语音波形:通过流匹配(flow matching)将语义标记映射为声学特征,再由声码器合成最终音频。
为建模长对话的上下文依赖,系统引入上下文正则化机制:在训练中逐步丢弃历史语音标记,迫使模型更多依赖语义连贯性而非记忆冗余信息,从而提升长篇生成的稳定性。
训练流程分三步:
- 首先在大规模独白与对话数据上预训练 LLM;
- 然后在多说话者对话数据上微调;
- 最后针对方言数据进行专项优化。
输入采用文本-语音交错序列格式,即每位说话者的文本后紧跟其对应的语音标记,按时间顺序拼接,便于模型理解对话结构。
实测表现
- 独白合成:在中文零样本克隆任务中,字符错误率(CER)低至 1.10%;英文词错误率(WER)为 1.91%,接近当前最优水平,同时说话者相似度评分领先。
- 多说话者播客:在中英文多轮对话测试中,WER/CER 均优于现有 SOTA 模型,说话者一致性(cpSIM)显著更高。
- 副语言控制:笑声生成准确率达 1.00,叹气与清嗓分别为 0.85 和 0.80。
- 方言生成:四川话、河南话、粤语的语音质量与说话人一致性与普通话、英语相当,验证了跨方言泛化能力。
应用场景
- 播客自动化制作:快速生成多角色、多方言的播客内容,降低制作门槛。
- 智能语音交互:为语音助手赋予更自然的对话能力和方言支持。
- 有声读物与多媒体配音:生成带情感和角色区分的语音,提升听觉体验。
- 语言学习工具:提供包含真实副语言和方言变体的语音样本,辅助发音与语感训练。
- 内容创作辅助:为视频、动画、游戏等提供低成本、高可控性的对话语音生成方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...