腾讯优图实验室、南京大学和厦门大学的研究人员推出用于高效多模态语音交互的端到端大型语音模型 VITA-Audio,VITA-Audio 的目标是通过快速生成音频和文本令牌,显著降低流式语音交互中的延迟,从而实现更自然、更实时的人机交互。
| 模型 | 尺寸 | 地址 |
|---|---|---|
| VITA-Audio-Boost | 7B | https://huggingface.co/VITA-MLLM/VITA-Audio-Boost |
| VITA-Audio-Balance | 7B | https://huggingface.co/VITA-MLLM/VITA-Audio-Balance |
| VITA-Audio-Plus-Vanilla | 7B | https://huggingface.co/VITA-MLLM/VITA-Audio-Plus-Vanilla |
例如,在一个语音助手场景中,用户提出一个问题,VITA-Audio 能够在首次模型前向传播时生成音频响应,无需额外的前向传播步骤,从而实现极低延迟的语音交互。
主要功能
VITA-Audio 的主要功能包括:
- 快速音频生成:能够在单次模型前向传播中生成多个音频令牌,显著降低生成首个音频令牌的延迟。
- 多模态交互:支持从文本到语音(TTS)、从语音到文本(ASR)以及口语问答(SQA)等多种任务。
- 高效推理:通过多阶段训练策略,优化模型的推理速度,同时保持高质量的语音合成。
- 实时对话能力:支持实时语音对话,适用于需要低延迟的交互场景。
主要特点
VITA-Audio 的主要特点如下:
- 轻量级多模态令牌预测模块(MCTP):通过轻量级模块高效生成音频令牌,避免了复杂的语义建模。
- 端到端架构:将语音编码器、解码器和大型语言模型(LLM)集成在一个框架中,减少了模块间的延迟和错误累积。
- 零音频令牌延迟:首次在单次前向传播中生成可解码的音频令牌,实现了真正的实时交互。
- 多阶段训练策略:通过四个阶段的训练,逐步优化模型的多模态映射能力,确保高效推理和高质量语音生成。
工作原理
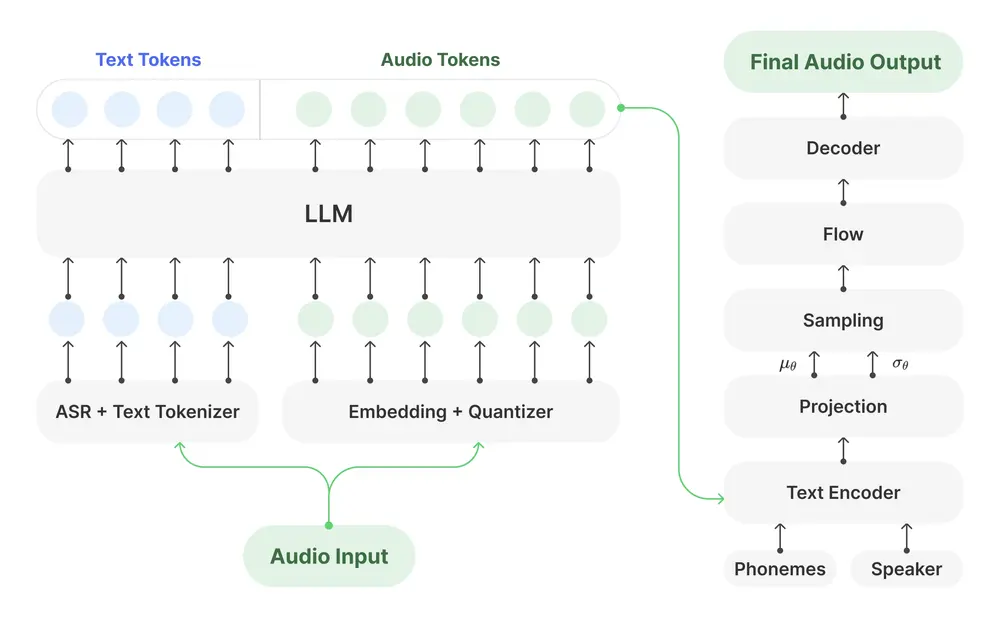
VITA-Audio 的工作原理基于以下几个核心组件:
- 音频编码器和解码器:使用 CosyVoice [20] 作为音频编码器和解码器,将音频信号编码为离散的音频令牌。
- 大型语言模型(LLM):作为模型的核心,处理文本和音频令牌的交互。
- 多模态令牌预测模块(MCTP):通过轻量级模块从 LLM 的隐藏状态和文本嵌入中预测多个音频令牌。这些模块在单次前向传播中生成多个音频令牌,显著减少了推理延迟。
- 四阶段训练策略:
- 第一阶段:音频-文本对齐,通过大规模语音预训练扩展 LLM 的音频建模能力。
- 第二阶段:训练单个 MCTP 模块,基于 LLM 的输出预测下一个音频令牌。
- 第三阶段:扩展到多个 MCTP 模块,逐步增加每次前向传播中生成的音频令牌数量。
- 第四阶段:通过语音问答数据进行监督微调,优化模型的语音对话能力。
测试结果
VITA-Audio 在多个基准测试中表现出色:
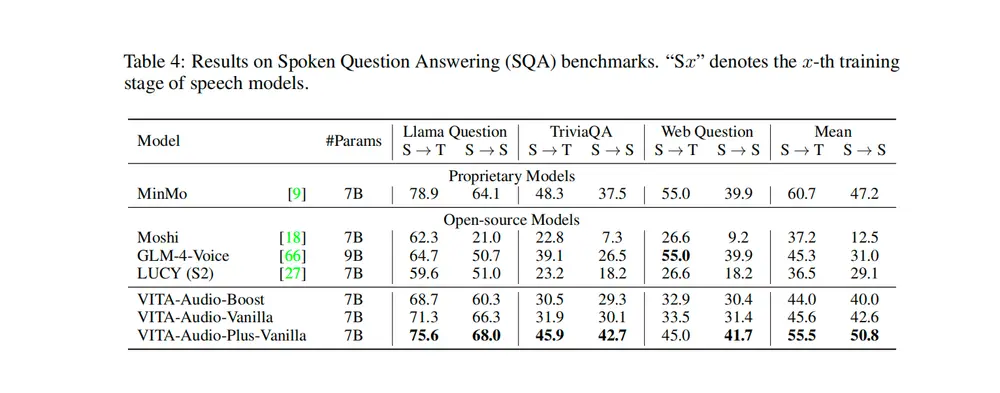
- 口语问答(SQA):
- 在 Web-Questions、Llama-Question 和 TriviaQA 数据集上,VITA-Audio 的 S→S(语音到语音)性能显著优于其他开源模型,平均性能提升超过 10%。
- 与 S→T(文本到文本)任务相比,VITA-Audio 的性能下降仅为 9%,显示出高质量的文本和语音对齐。
- 文本到语音(TTS):
- 在 Seed-TTS 和 LibriTTS 数据集上,VITA-Audio 的性能优于其他开源模型,特别是在 Seed-TTS 数据集上,字符错误率(CER)和词错误率(WER)均显著降低。
- 自动语音识别(ASR):
- 在 LibriSpeech 和 AISHELL 数据集上,VITA-Audio 的性能与现有模型相当,尽管其主要优化目标是语音生成,但 ASR 能力并未显著下降。
- 推理速度:
- VITA-Audio 的 Turbo 模式在 7B 参数规模下实现了约 5 倍的推理加速,显著提高了音频生成速度。
- 在 72B 参数规模下,VITA-Audio 的 Turbo 模式实现了约 6.5 倍的加速,生成速度足以支持实时人机交互。
应用场景
VITA-Audio 的应用场景非常广泛,包括但不限于:
- 智能语音助手:在需要低延迟交互的场景中,如智能音箱、车载语音助手等,VITA-Audio 能够提供快速、高质量的语音响应。
- 实时语音对话系统:在客服、会议等场景中,VITA-Audio 的实时对话能力能够显著提升用户体验。
- 语音合成和语音识别:在需要高质量语音合成和识别的应用中,如语音播报、语音转写等,VITA-Audio 能够提供高效、准确的解决方案。
- 教育和培训:在语言学习、语音训练等教育场景中,VITA-Audio 能够提供实时反馈和指导。
通过其高效的数据处理、高质量的生成结果和灵活的控制能力,VITA-Audio 为语音交互领域提供了一个强大的工具,能够显著提升生产效率和用户体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...