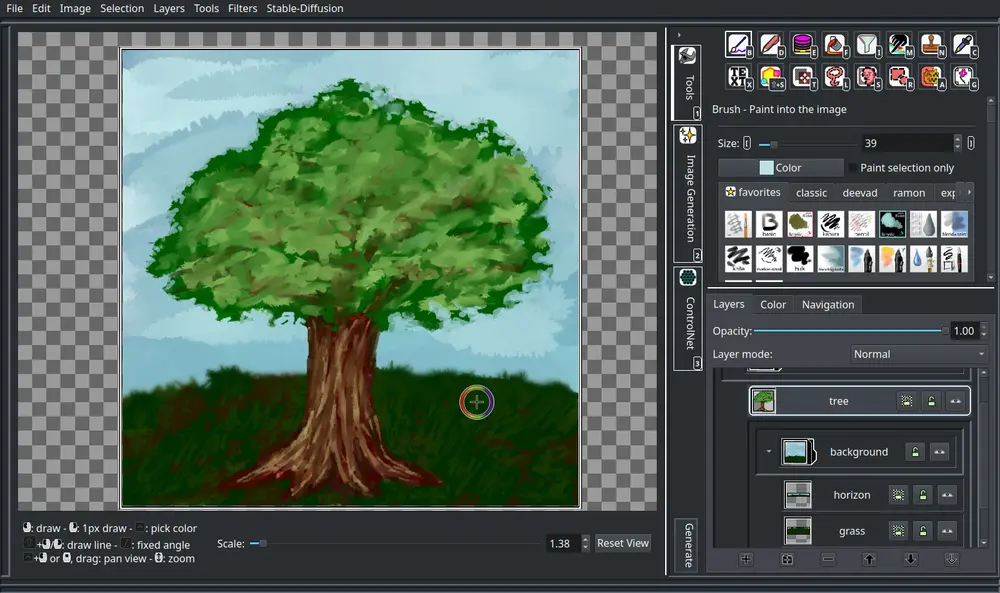
NeuroSandboxWebUI是一个强大且易于使用的界面,支持多种神经网络模型,涵盖文本、语音、图像、视频、3D对象、音乐和音频等多种输入和输出形式。以下是详细的介绍和安装指南。
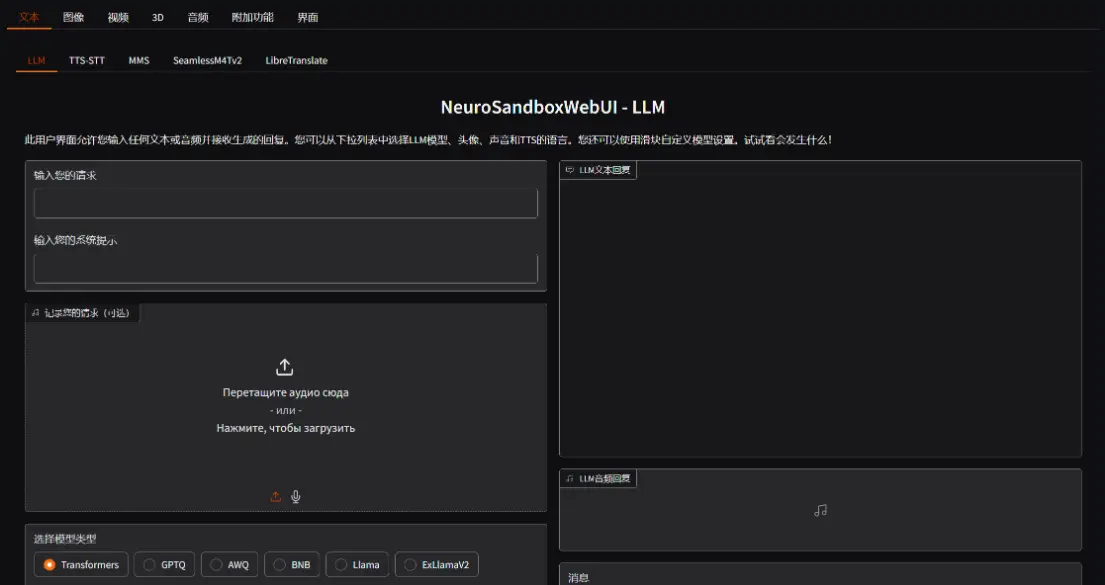
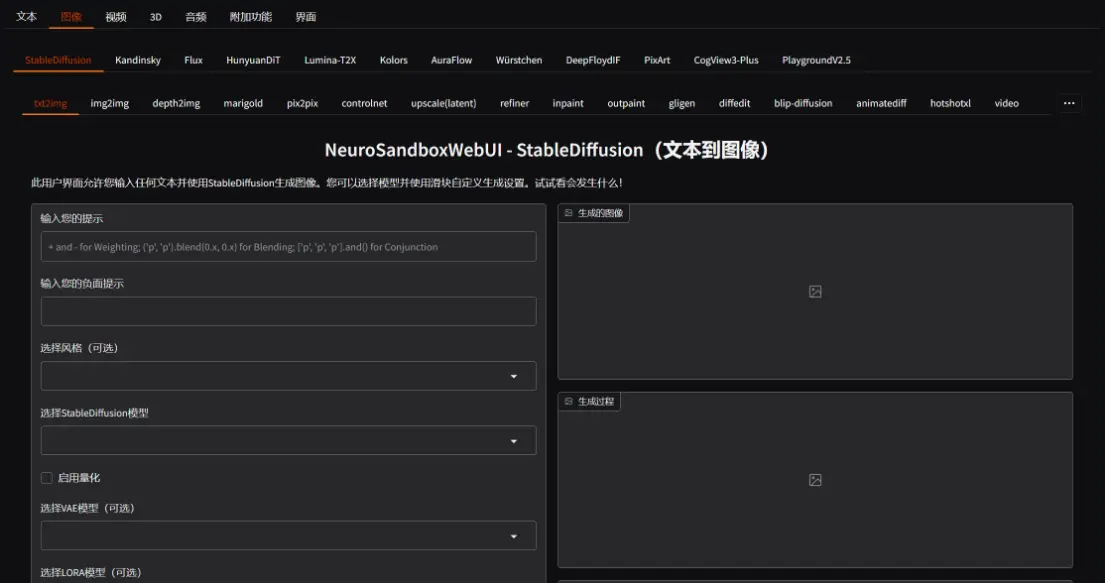
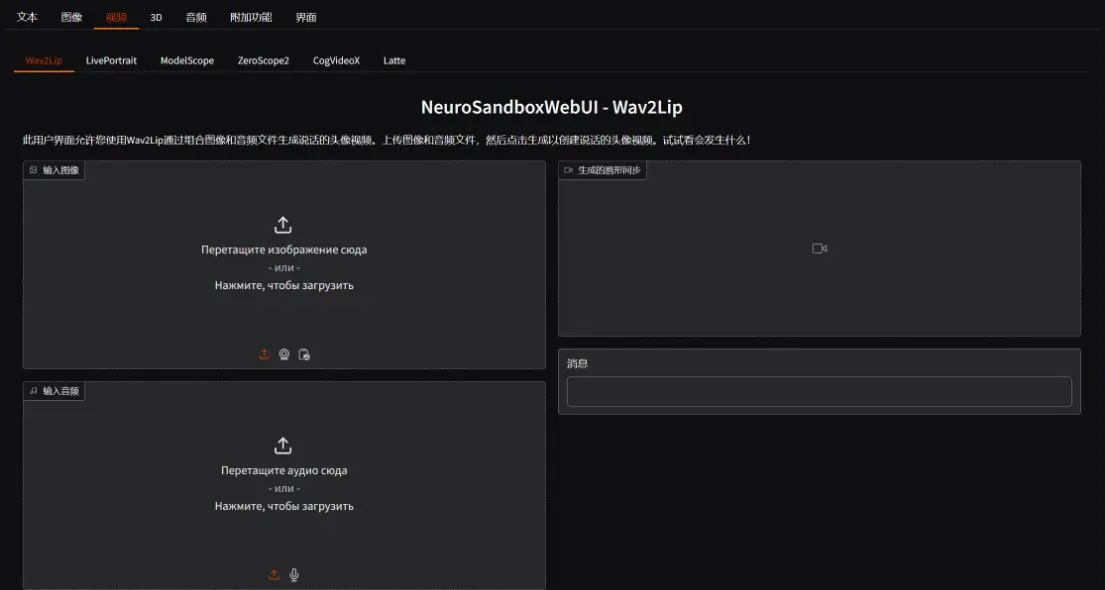
功能概述
文本、语音和图像输入:
与LLM(大型语言模型)进行通信。 使用StableDiffusion、Kandinsky、Flux、HunyuanDiT、Lumina-T2X、Kolors、AuraFlow、Würstchen、DeepFloydIF、PixArt、CogView3-Plus和PlaygroundV2.5生成图像。 使用ModelScope、ZeroScope 2、CogVideoX和Latte生成视频。 使用StableFast3D、Shap-E和Zero123Plus生成3D对象。 使用StableAudioOpen、AudioCraft和AudioLDM 2生成音乐和音频。 使用CoquiTTS、MMS和SunoBark进行文本到语音转换。 使用OpenAI-Whisper和MMS进行语音到文本转换。 使用Wav2Lip进行唇形同步。 使用LivePortrait为图像添加动画。 使用Roop进行换脸。 使用Rembg移除背景。 使用CodeFormer修复面部。 使用PixelOE进行图像像素化。 使用DDColor为图像上色。 使用LibreTranslate和SeamlessM4Tv2进行文本翻译。 使用Demucs和UVR进行音频文件分离。 使用RVC进行语音转换。
其他功能:
查看输出目录中的文件。 下载LLM和StableDiffusion模型。 在界面内更改应用程序设置。 检查系统传感器。
安装指南
1、安装必需依赖:
Python(3.10.11) Git CUDA(12.4)和cuDNN(9.1)(仅GPU版本) FFMPEG C++编译器(Visual Studio、Visual Studio Code和CMake)
2、克隆仓库:
git clone https://github.com/Dartvauder/NeuroSandboxWebUI.git
3、运行安装脚本:
导航到克隆的目录。 运行 Install.bat,选择您的版本并等待安装完成。
4、启动应用程序:
运行 Start.bat。跟随终端中的链接完成初始设置。 应用程序启动后,您就可以开始生成内容了。
5、获取更新:
运行 Update.bat获取最新更新。
6、使用虚拟环境:
运行 Venv.bat通过终端使用虚拟环境。
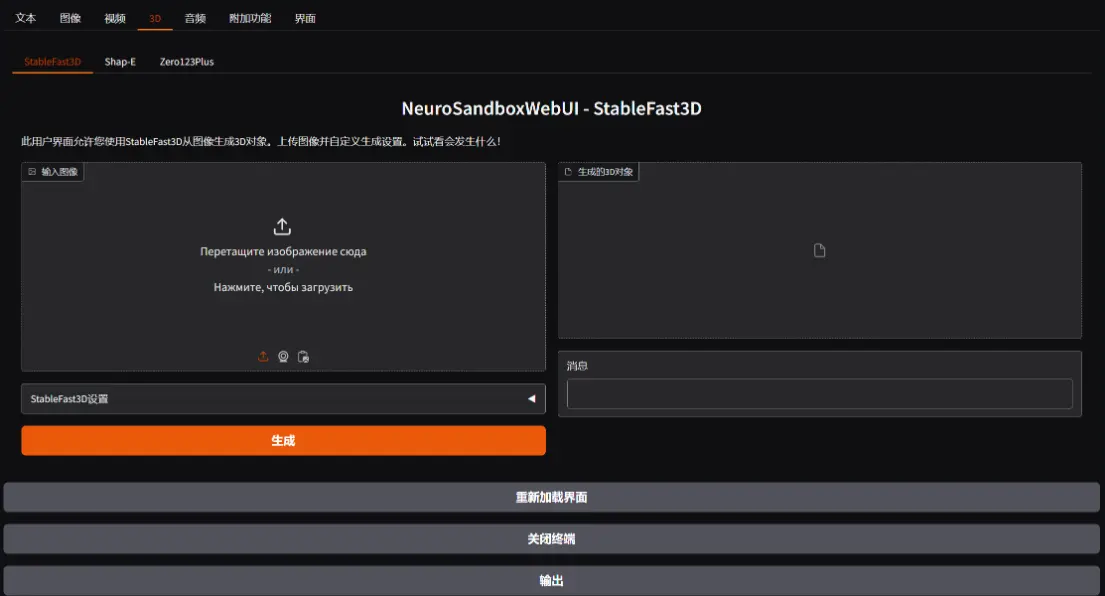
最低系统要求
系统:Windows, Linux或MacOS GPU:6GB+ 或 CPU:8核3.6GHz RAM:16GB+ 磁盘空间:20GB+ 互联网连接:需要互联网连接以下载模型和进行安装
其他功能
多模态支持:支持Moondream 2, LLaVA-NeXT-Video, Qwen2-Audio等多模态模型。 PDF解析:使用OpenParse解析PDF文件。 TTS和STT:支持CoquiTTS和Whisper模型。 LORA和网络搜索:支持LORA和使用DuckDuckGo进行网络搜索。 元数据信息查看器:用于生成图像、视频和音频的元数据信息查看器。 界面内的模型设置:在界面内调整模型设置。 在线和离线Wiki:提供在线和离线文档。 图库:查看输出目录中的文件。 模型下载器:下载所需的模型。 应用程序设置:调整应用程序设置。 系统传感器查看:查看系统传感器状态。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











