
在语音合成领域,大多数主流 TTS(Text-to-Speech)模型依赖于将语音信号离散化为“音素”或“语音标记”——这一过程虽然便于建模,但也带来了固有局限:
声音细节丢失、韵律不自然、跨说话人迁移困难。
- GitHub:https://github.com/OpenBMB/VoxCPM/
- Hugging Face:https://huggingface.co/openbmb/VoxCPM-0.5B
- 魔塔:https://modelscope.cn/models/OpenBMB/VoxCPM-0.5B
- Demo:https://huggingface.co/spaces/openbmb/VoxCPM-Demo
为突破这些瓶颈,面壁智能发布 VoxCPM,它采用了一种全新的路径:完全绕过分词器(Tokenizer),直接在连续空间中生成语音。
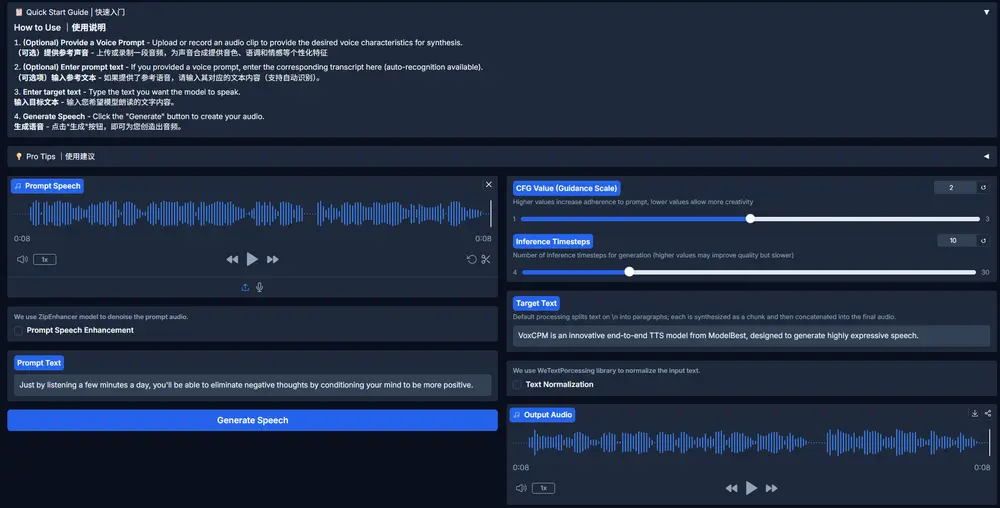
基于 MiniCPM-4 架构,VoxCPM 提出了一种端到端扩散自回归框架,在无需显式声学单元分割的前提下,实现了高保真、富有表现力且支持零样本克隆的语音合成。
核心理念:从“离散标记”到“连续建模”
传统 TTS 系统通常遵循三阶段流程:
- 文本 → 语言特征(如音素)
- 语言特征 → 声学特征(梅尔谱图等)
- 声学特征 → 波形
其中第二步往往依赖离散表示,导致语音的细微变化(如语气起伏、情感色彩)难以完整保留。
VoxCPM 的创新在于:
跳过语音离散化环节,让模型在连续语义-声学空间中学习映射关系。
其架构融合了以下关键技术:
✅ 端到端扩散自回归生成
结合扩散模型的高质量生成能力与自回归模型的时间一致性控制,实现稳定流畅的语音输出。
✅ 层次化语言建模
通过深层语义理解模块捕捉上下文信息,使模型能根据句子意图自动调整语调、节奏和重音分布。
✅ FSQ(Finite Scalar Quantization)约束
在隐空间中引入量化先验,实现隐式语义-声学解耦——即让语言内容与声音特征在内部表示层面分离,从而提升可控性和泛化能力。

关键能力
1. 上下文感知的富有表现力语音生成
VoxCPM 能够理解输入文本的情感倾向和语用背景,并据此生成匹配的说话风格。
例如:
- 输入一句疑问句:“你真的这么认为?” → 模型自动提升尾音;
- 输入命令式语句:“立刻执行!” → 语速加快,力度增强;
- 描述悲伤场景时,语调低沉、节奏放缓。
这种动态适应能力得益于其训练所使用的 180万小时双语语料库,覆盖广泛场景与表达方式,显著提升了生成语音的自然度与表现力。
2. 高保真零样本声音克隆
仅需一段几秒钟的参考音频,VoxCPM 即可完成零样本声音克隆(Zero-shot Voice Cloning),不仅还原音色,还能捕捉以下细节:
- 口音特征(如英式发音中的卷舌)
- 情感基调(温暖、严肃、兴奋)
- 语流节奏与停顿习惯
- 个性化语速变化模式
由于整个过程不依赖预定义身份嵌入或微调,响应速度快,适合实时交互场景。
更重要的是,生成结果在听感上更接近真实录音,而非“模仿秀”,减少了传统克隆技术常见的机械感和失真问题。
3. 高效流式合成,支持实时应用
尽管模型复杂度较高,VoxCPM 在消费级硬件上仍具备出色的推理效率:
| 设备 | 实时因子 (RTF) |
|---|---|
| NVIDIA RTX 4090 | 低至 0.17 |
这意味着生成 1 秒语音仅需约 170 毫秒计算时间,支持流式输出,可用于:
- 实时对话系统
- 游戏 NPC 对话
- 视频配音自动化
- 虚拟主播驱动
技术意义:重新思考语音合成的范式
VoxCPM 的出现,标志着语音合成正从“基于规则+离散建模”的旧范式,向“端到端+连续空间建模”的新方向演进。
它的优势不仅体现在质量提升,更在于:
- 减少人工设计组件(如音素词典、对齐模型);
- 提升跨语言、跨风格迁移能力;
- 支持更高自由度的声音编辑与控制。
对于需要高度自然语音的应用场景——如无障碍阅读、虚拟角色配音、个性化助手——这类系统正变得不可或缺。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











