
近年来,语音到语音大语言模型(Speech-to-Speech LLMs, SLLMs)成为多模态 AI 的重要方向——用户说一句话,模型直接以语音回应,无需经过“语音→文本→语音”的中间转换。
但这类模型面临一个根本问题:在追求语音自然性的同时,往往牺牲了知识与推理能力。相比纯文本大模型,它们回答问题更弱、逻辑更模糊。
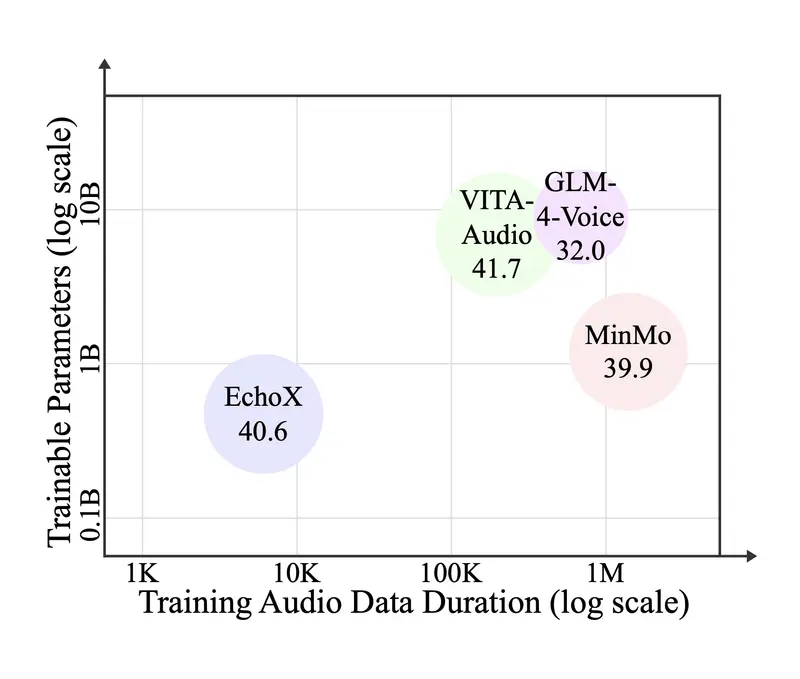
为解决这一挑战,香港中文大学(深圳) 研究团队提出 EchoX ——一种新型语音大语言模型训练框架。它通过“回声式”目标生成机制,在仅使用约 6000 小时训练数据的情况下,就在多个知识问答任务上达到先进水平。
- 项目主页:https://freedomintelligence.github.io/EchoX
- GitHub:https://github.com/FreedomIntelligence/EchoX
- 模型:https://huggingface.co/FreedomIntelligence/EchoX-8B
- Demo:https://huggingface.co/spaces/FreedomIntelligence/EchoX
更重要的是,EchoX 成功保留了底层语言模型的推理能力,真正实现了“能听懂、会思考、可说话”。
问题本质:语音模型为何“听得清却答不准”?
传统文本大模型(如 Llama、ChatGLM)依赖语义对齐进行训练:
“Hello” 和 “Hi” 虽然字面不同,但语义相近,模型可以自动关联。
而当前主流 SLLM 的训练方式是:
将语音编码(如 EnCodec tokens)作为目标序列,强制模型从输入语音预测这些离散语音标记。
这带来两个问题:
- 过度关注声学细节:模型被迫学习如何复现特定音色、语调、停顿,导致注意力偏离语义;
- 缺乏语义抽象能力:同样的意思,不同发音方式会产生完全不同的语音 token 序列,破坏语义一致性。
结果就是:模型能流畅复读,却难以准确回答“太阳为什么是圆的?”这样的问题。
这就是所谓的 声学-语义差距(acoustic-semantic gap)。
核心方案:Echo 训练——让语音目标“从语义中生长出来”
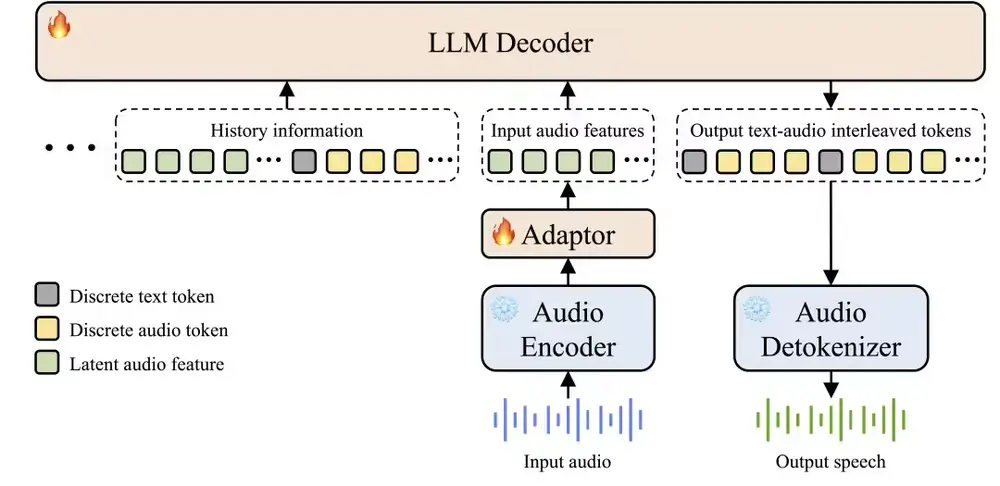
EchoX 的关键创新在于:不再依赖原始语音标注作为训练目标,而是动态生成语义一致的语音表示。
具体来说,采用三阶段协同训练流程:
第一阶段:语音 → 文本(S2T)
使用预训练的语音理解模块(如 SoundWave),将输入语音转为文本表示。
目的:提取语义内容,剥离声学噪声。
第二阶段:文本 → 语音编码(T2C)
训练一个文本到语音编码的映射模型,将语义文本转化为高质量的语音 token 序列。
这个模型知道:“Hello” 和 “Hi” 应该对应相似的语音模式。
第三阶段:回声训练(Echo Training)
这是 EchoX 的核心:
- 将第一阶段的语义输出送入第二阶段模型;
- 动态生成一组语义对齐、声学合理的语音 token 作为训练目标;
- 最终 SLLM 学习从语音输入直接生成这些“语义驱动”的语音标记。
🔄 类比“回声”:你说一句,系统理解后“用自己的声音”重新表达出来,而不是机械模仿。
这种方式让模型既能保持语音生成质量,又不丢失语义抽象与推理能力。
关键技术支撑
✅ 单元语言(Unit Language):压缩语音序列,提升效率
语音 token 序列通常远长于文本(一段话可能对应上千个语音单元)。EchoX 引入“单元语言”概念,将连续语音切分为类词级别的语义单元,显著缩短序列长度,降低生成难度。
✅ 流式生成机制:支持实时交互
针对长语音生成延迟高的问题,EchoX 设计了基于语义余弦相似度的触发机制:
- 实时监测语义缓存;
- 当语义片段趋于完整时,立即启动语音生成;
- 实现低延迟、高连贯性的流式对话体验。
实验结果:小数据,大效果
尽管只使用了约 6000 小时的训练数据(远少于同类模型动辄百万小时的规模),EchoX 在多项任务中表现优异:
| 模型 | Llama Questions 准确率 |
|---|---|
| EchoX-3B | 73.0% |
| EchoX-8B | 77.3% |
在 WebQuestions、TriviaQA 等知识问答基准上,性能接近甚至超过更大规模的模型。
此外:
- 语音到文本任务:准确率与专用 S2T 模型相当;
- 流式生成:延迟降低 40% 以上,人工评估显示自然度和帮助性得分高;
- 用户满意度:在响应相关性、语音自然性和整体体验方面均获积极反馈。
消融实验证明,回声训练策略、单元语言设计和流式机制均对最终性能有显著贡献。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











