想象一下,你对AI说"生成一首桑巴舞曲",它确实生成了一段不错的音乐。但你现在觉得节奏稍微快了点,或者想把女声换成男声,又或者想加点钢琴伴奏——用传统的文字提示,你只能说"一首快节奏的男性演唱桑巴舞曲带钢琴",结果AI可能完全重新生成了一首新歌,而不是在原来基础上微调。
- 项目主页:https://audio-steering.github.io
- GitHub:https://github.com/luk-st/steer-audio
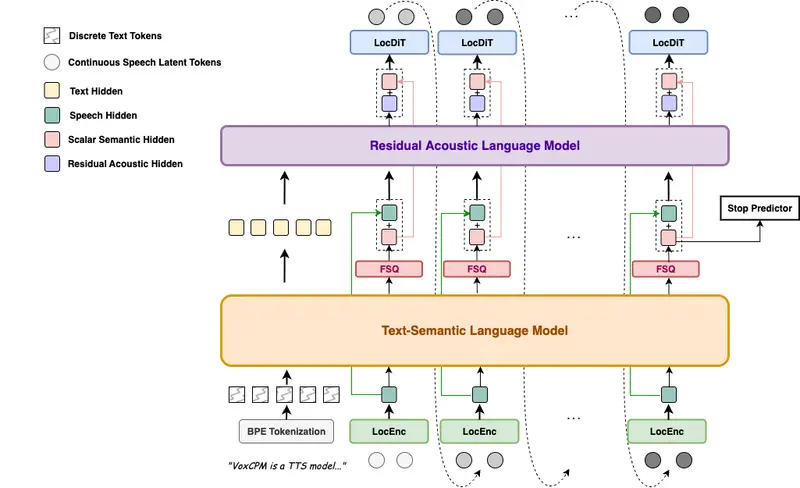
TADA研究的核心问题就是:如何让AI音乐生成模型像调音台一样,可以精准调节各种音乐元素(速度、情绪、乐器、人声等),而不影响其他部分?
解决了什么问题?
目前的AI音乐生成模型(如AudioLDM2、Stable Audio、AceStep等)虽然能生成高质量音乐,但存在几个明显痛点:
- 文字提示太粗糙:你无法精确控制"稍微慢一点"或"稍微欢快一点",只能换一组完全不同的关键词
- 黑盒问题:模型内部如何工作完全不清楚,就像一个神秘的音乐家,你不懂他的创作逻辑
- 牵一发而动全身:想改一个细节(比如把人声从女变男),结果整首歌都变了,旋律、节奏、配器全不一样
TADA要解决的核心问题是:打开AI音乐模型的"黑盒",找到控制各种音乐元素的"开关",让用户可以像调节音响旋钮一样精准控制音乐属性。
研究背景
AI音乐生成技术近年来突飞猛进,从早期的简单旋律生成发展到现在的"文字描述生成完整乐曲"。但这些模型越来越像"黑箱"——输入文字,输出音乐,中间发生了什么没人知道。
华沙理工大学和IDEAS研究所的研究团队从"可解释性AI"的角度切入,试图理解这些模型内部是如何表示"速度""情绪""乐器"等音乐概念的。他们的发现令人惊讶:控制这些音乐概念的,只是模型中极少数的特定层,而不是整个模型。
主要功能
TADA就像一个给AI音乐模型安装的"调音台插件",核心能力包括:
1. 精准调节音乐速度
- 可以让生成的音乐逐渐变快或变慢
- 调节是平滑连续的,不是跳跃式的"快/慢"二选一
- 保持旋律和配器基本不变,只改变速度感
2. 控制人声性别
- 可以把女声变成男声,或反之
- 保持歌词内容、演唱风格、情感表达不变
- 调节程度可控,可以做出"中性嗓音"等中间状态
3. 调整音乐情绪
- 让欢快的音乐变得忧郁,或让悲伤的音乐变得明亮
- 保持原有乐器和节奏型,只改变情绪色彩
- 可以实现" bittersweet(苦乐参半)"等复杂情绪
4. 控制乐器出现与消失
- 让钢琴、小提琴、鼓等乐器逐渐加入或淡出
- 可以"增强"某种乐器,让它在混音中更突出
- 保持其他乐器和整体结构不变
5. 切换音乐风格
- 在爵士、雷鬼、 techno 等风格间平滑过渡
- 保持核心旋律,改变节奏型和音色特征
- 可以创造"融合风格",如爵士味的电子乐
关键特性:所有调节都是"渐进式"的
不同于传统方法只能"要或不要",TADA允许你像调节音量旋钮一样,从0到100%连续调节任何属性。比如速度可以从"很慢"经过"适中"到"很快"的任意点,而不是只有"快/慢"两个选项。
主要特点
相比现有的AI音乐控制方法,TADA有四大核心优势:
特点一:找到"控制中枢"——少数层控制一切
研究团队发现了一个惊人的事实:所有音乐概念(速度、情绪、人声、乐器、风格)都由模型中极少数的特定层控制。
- 在AudioLDM2模型中,只有4层(总共64层)控制所有音乐概念
- 在AceStep模型中,只有2层(总共24层)是"语义瓶颈"
- 在Stable Audio Open模型中,也是只有2层起关键作用
这就像发现,一台复杂的音响设备,其实所有音色调节都只通过几个核心旋钮完成,而不是每个功能都要调一堆参数。
特点二:精准定位——只调该调的,不动其他的
传统方法如果要改变音乐属性,往往会影响整个生成过程,导致音质下降或 unintended changes。TADA的方法只修改那些"功能层",其他层完全不动。
结果是:你想改速度,旋律真的不变;你想换人声,伴奏真的不变。
特点三:两种控制方式,灵活可选
TADA提供了两种"调音"工具:
- 对比激活加法(CAA):像调节均衡器,通过对比"快vs慢""男vs女"的样本,找到控制方向
- 稀疏自动编码器(SAE):像打开调音台的内部电路,找到代表特定音乐概念的"特征开关"
两种方法各有优势,可以针对不同场景选择使用。
特点四:保持音质——调节不等于劣化
很多AI编辑工具在修改内容时会导致音质下降。TADA的实验表明,由于其精准定位的特性,在调节音乐属性的同时,可以保持甚至提升音质指标。
工作原理
用大白话讲,TADA是怎么找到这些"音乐控制开关"的?
可以把TADA的工作流程想象成一个"神经科学家研究大脑"的过程——通过精巧的实验,定位哪个脑区控制哪种功能。
第一步:构建"对照实验"(激活修补)
研究团队设计了一套巧妙的实验方法:
- 准备一对"对照提示":比如"女声演唱的歌曲"vs"男声演唱的歌曲",其他描述完全相同
- 第一次运行:用"女声"提示生成音乐,记录模型每一层的"工作状态"(激活值)
- 第二次运行:用"男声"提示生成,但在某一特定层,强行替换为第一次记录的"女声"状态
- 观察结果:如果替换后,生成的音乐变成了女声,说明这一层控制人声性别
通过在不同层重复这个实验,研究团队定位出了控制各种音乐概念的"功能层"。
第二步:找到"控制方向"(对比激活加法)
一旦定位了功能层,下一步是找到"怎么调":
- 收集多组对比样本:比如100组"快歌vs慢歌"的生成结果
- 计算差异向量:对每组样本,计算功能层的激活值差异,得到"速度控制方向"
- 归一化处理:把这个方向标准化,得到一个"单位调节量"
使用时,如果你想让音乐变快,就在功能层的激活值上,加上这个"速度方向"乘以你想要的强度。强度可以是正的(加快)或负的(减慢),大小任意调节。
第三步:训练"特征探测器"(稀疏自动编码器)
为了更精细地控制,TADA还在功能层训练了一个"稀疏自动编码器"——这就像一个"概念翻译器":
- 编码:把功能层的复杂激活模式,压缩成少数几个"特征开关"(大部分为0,只有少数激活)
- 解码:把这些特征开关还原回激活模式
- 识别概念:通过对比实验,识别哪些开关对应"钢琴""女声""快节奏"等概念
使用时,你只需要打开或关闭特定的特征开关,就能精准控制对应的音乐元素。
关键技术:只在功能层操作
TADA的核心创新在于精准定位。研究发现:
- 如果对所有层都进行调节,效果很差,音质明显下降
- 如果避开功能层、只调其他层,几乎无法控制音乐属性
- 只对功能层进行调节,既能精准控制属性,又能保持音质
这验证了"语义瓶颈"的存在——模型把音乐概念的理解和表达,集中在极少数特定层处理。
测试结果
TADA在严格的实验验证中表现优异,以下是关键发现:
测试一:定位实验——找到功能层
研究团队测试了三种主流AI音乐生成模型:
- AudioLDM2(U-Net架构):功能层位于解码器的第44、45、50、51层(仅4层)
- AceStep(Transformer架构):功能层是第6、7层(仅2层)
- Stable Audio Open(Transformer架构):功能层是第11、12层(仅2层)
关键发现:无论模型架构如何不同,音乐概念的控制都集中在极少数层,而且不同概念(速度、情绪、乐器等)共享同一组功能层。
测试二:控制效果对比
研究团队对比了四种调节策略:
- 不调节:原始生成结果(基准线)
- 全层调节:对所有层进行激活 steering
- 非功能层调节:避开功能层,只调其他层
- 功能层调节:只调节定位出的功能层(TADA方法)
- SAE调节:用稀疏自动编码器在功能层调节
关键结果:
- 非功能层调节:几乎无法控制音乐属性(比如想调速度,速度没变),证明功能层的必要性
- 全层调节:虽然能控制属性,但音质明显下降,且 unintended changes 多
- 功能层调节(TADA):控制效果强,音质保持好,各项指标最优
- SAE调节:控制效果与功能层调节相当,但更具可解释性(知道调的是哪个"开关")
具体指标(以AceStep模型为例):
钢琴控制:
- 功能层调节:成功添加钢琴,保持其他属性,音质评分6.64(接近原始6.79)
- 全层调节:钢琴控制效果差,音质评分6.61
人声性别控制:
- 功能层调节:成功切换男女声,音质评分6.67
- 非功能层调节:几乎无法控制,音质评分6.50
速度控制:
- 功能层调节:速度调节范围大(0.143),平滑度好(0.003),音质评分6.59
- 全层调节:速度调节范围小(0.164),音质评分6.52
情绪控制:
- SAE调节:情绪调节效果最佳(0.132),音质评分6.67
- 功能层调节:情绪调节效果次之(0.136),音质评分6.64
测试三:平滑度与音质
TADA的方法在"平滑度"指标上表现优异——这意味着调节过程是连续、可预测的,不会出现突然的跳跃或断裂。
在音质评估(内容享受度、有用性、制作复杂度、制作质量)上,TADA的方法最接近甚至有时超过原始生成结果,证明精准控制不等于牺牲质量。
关键结论
- 功能层确实存在:极少数层控制所有音乐语义概念,不同模型架构都有类似现象
- 精准定位带来精准控制:只在功能层操作,既能有效控制属性,又能保持音质
- 稀疏自动编码器有效:SAE方法不仅效果相当,还提供了可解释的"特征开关"
- 控制与质量可以兼得:TADA打破了"要控制就要牺牲质量"的 trade-off
更广阔的愿景
TADA的研究方法(激活修补、功能层定位、稀疏自动编码器)不仅适用于音乐,也可以扩展到:
- 语音合成:精准控制语调、情感、口音
- 音效设计:控制环境声的空间感、材质感
- 多模态创作:统一调节视频、音频、图像的语义属性
当AI创作工具从"黑箱"变成"透明调音台",创意工作者将真正掌握AI的力量,而不是被AI的随机性所困扰。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











