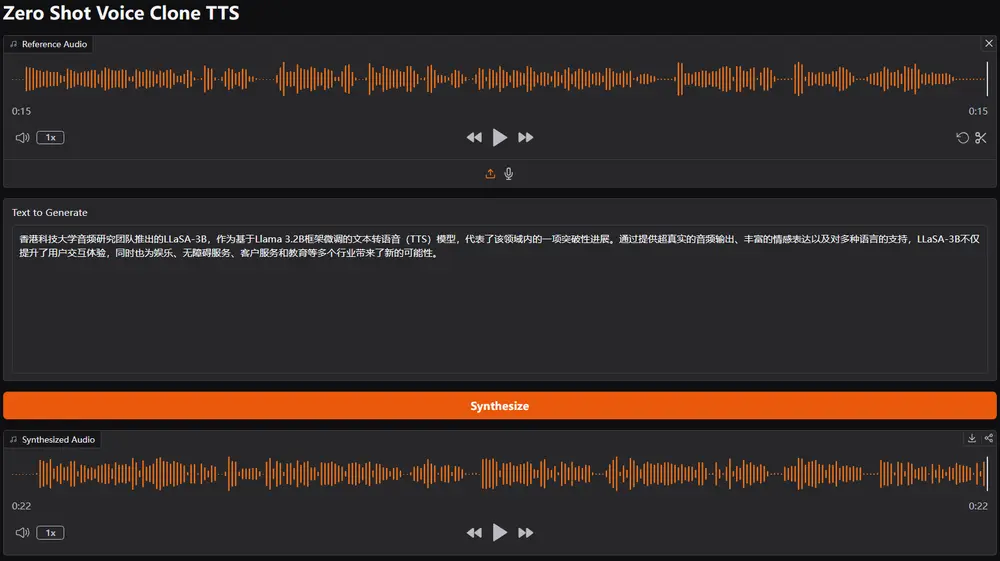
AI 初创公司 NineNineSix 正式开源其新一代文本转语音(TTS)模型 KaniTTS2。该模型专为低延迟、高自然度的实时对话场景设计,支持语音克隆、多语言输出,并提供完整的从零预训练代码框架,允许开发者基于自有数据训练定制化 TTS 模型。
- GitHub:https://github.com/nineninesix-ai/kani-tts-2
- 模型:https://huggingface.co/nineninesix/kani-tts-2-pt
- Demo:https://huggingface.co/spaces/nineninesix/kani-tts-2-pt
核心定位:实时对话优先
与传统 TTS 不同,KaniTTS2 针对交互式 AI 助手、智能客服、语音代理等场景优化,强调:
- 低推理延迟:在 RTX 5090 上实测 RTF(实时因子)约 0.2,即生成 1 秒语音仅需 0.2 秒
- 低显存占用:仅需 3GB GPU 显存,可在消费级显卡上运行
- 高采样质量:22kHz 采样率,平衡音质与效率
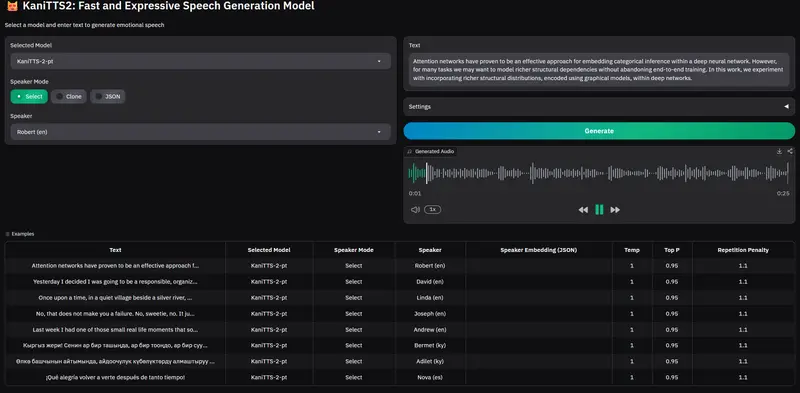
语言与模型能力
- 当前支持语言:英语(含本地口音变体)、西班牙语、吉尔吉斯语
- 语音克隆:支持基于少量样本(few-shot)的说话人音色复现
- 模型规模:4 亿参数,在效果与效率间取得良好平衡
- 训练数据:基于约 1 万小时高质量语音进行预训练
- 训练效率:在 8 张 H100 上仅需 6 小时完成全量训练
未来版本将扩展更多语言,社区可基于开源框架贡献新语种。
开源亮点:完整预训练框架
NineNineSix 最具突破性的贡献是公开了端到端的 TTS 预训练系统,使任何团队都能训练自己的 TTS 模型:
关键技术特性
- LFM2 混合架构:结合 LLM 与 FSQ(Factorized Scalar Quantization)音频编解码器,实现高质量语音生成
- 帧级位置编码(Frame-level Position Encoding):同一音频帧内的 4 个 token 共享位置 ID,减少 RoPE 距离衰减,显著提升长语音连贯性
- FlashAttention-2 优化:训练速度比标准 attention 快 10–20 倍
- FSDP 多 GPU 支持:通过全分片数据并行(Fully Sharded Data Parallel)实现高效分布式训练
- 模块化 OOP 设计:代码结构清晰,易于扩展
- YAML 配置驱动:所有超参、路径、模型结构均通过 YAML 文件管理,无需修改代码
Token 设计
- 文本 token:0–64,399
- 特殊 token:64,400–64,409(如 EOS、SOS)
- 音频 token:64,410–80,537(FSQ 编码后的声学单元)
- 总词汇量:80,538
该设计将文本与音频统一到同一 token 空间,简化训练流程。
应用场景
- AI 智能体语音输出(如 OpenClaw、TinyClaw 的语音前端)
- 多语言客服机器人
- 个性化语音助手(结合语音克隆)
- 教育/无障碍工具(实时朗读、发音辅助)
- 游戏 NPC 对话生成
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











