
长期以来,语音对话 AI 面临一个根本性矛盾:
- 传统级联系统(ASR → LLM → TTS)允许你自定义角色和声音,但对话僵硬、延迟高、无法被打断;
- 全双工模型(如 Moshi)实现了自然的话轮转换、打断和附和,却将你锁定在单一固定人设中。
英伟达最新发布的 PersonaPlex 正是为打破这一权衡而生——它首次在保持全双工自然对话能力的同时,支持任意角色设定与声音选择。
你可以让 AI 扮演一位冷静的客服代表、热情的餐厅服务员、睿智的教师,甚至一个奇幻世界的精灵,而它依然能像真人一样被打断、会“嗯哼”附和、快速接话。
核心定位:实时语音到语音的双流对话模型
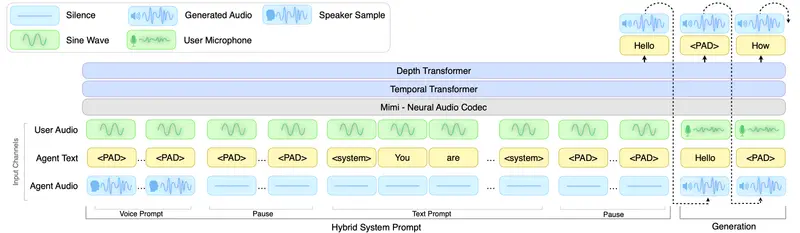
PersonaPlex是一款端到端的实时语音对话模型,核心能力是同步执行流式语音理解与语音生成。
它直接处理经神经编解码器编码的连续音频,以自回归方式同时预测文本标记与音频标记,生成语音响应。用户输入的音频会被增量编码并输入模型,与此同时,模型同步生成输出语音,这一设计直接实现了高度拟人化的对话动态。
在对话启动前,PersonaPlex仅需两个提示即可完成“人设塑造”:
- 语音提示:由一系列音频标记构成,用于定义目标声音特征、说话风格与韵律;
- 文本提示:通过自然语言描述角色属性、背景信息与场景上下文。
两者结合,共同锚定模型的对话身份,并在整个交互过程中,持续指导模型的语言逻辑与声学表现。目前,该模型已具备商业部署能力。
核心功能:全双工交互带来的自然对话体验
全双工是PersonaPlex的核心特性——模型能够同时“听”和“说”。这一源于Moshi的能力,不仅让模型学会“说什么”,更掌握了“怎么说”:包括何时停顿、何时打断对方、何时用“嗯哼”“哦”等语气词附和。
相较于传统级联系统,PersonaPlex的优势十分显著:
- 低延迟交互:摒弃了独立的语音识别、语言生成、语音合成模型串联架构,用单一模型实现端到端处理,消除了级联链路的延迟;
- 动态交互能力:模型在用户说话过程中实时更新内部状态,即时流式返回响应,支持打断、插话、重叠发言等真实对话场景;
- 拟人化表达:非语言层面的互动(如附和、停顿、语气变化),为对话增添了情绪线索,让用户能像与真人交流一样,解读模型的意图与理解程度。
技术架构:基于Moshi的70亿参数双流模型
PersonaPlex基于Kyutai的Moshi架构打造,内置70亿参数,整体架构分为三大核心模块,且全程支持24kHz音频采样率:
- Mimi语音编码器:由卷积神经网络(ConvNet)+Transformer构成,负责将输入音频转换为机器可识别的标记;
- 时间与深度变换器:作为核心处理单元,负责解析对话上下文,支撑全双工交互的动态逻辑;
- Mimi语音解码器:由Transformer+ConvNet构成,将模型生成的标记还原为自然语音输出。
其中,底层语言模型采用Helium,为系统提供了强大的语义理解能力与分布外场景泛化能力;而双流配置则是实现“边听边说”的关键,确保听与说两个动作同步进行,复刻真实对话的节奏。
训练数据:真实对话+合成对话的混合训练方案
PersonaPlex的训练面临两大核心挑战:一是缺乏涵盖丰富非语言行为(打断、附和、停顿)的对话数据;二是全双工行为的监督训练,需要分离多说话者的音频数据。
为解决这些问题,英伟达采用了真实对话+合成对话的混合训练策略,具体分为两部分:
1. 基于Fisher语料库的真实对话训练
为让模型学习自然的附和、情感反应与对话节奏,PersonaPlex在Fisher英语语料库的7303段真实无脚本对话(总计1217小时)上进行训练。
研发团队使用GPT-OSS-120B为这些对话进行后向注释,生成不同详细程度的文本提示,平衡模型的泛化能力与指令遵循能力。例如:
- 基础提示:“你喜欢好好聊天”;
- 场景提示:“你喜欢好好聊天,关于在家吃饭还是外出就餐进行一次随意讨论”;
- 深度人设提示:“你喜欢好好聊天,进行一次关于职业变动和家园感的反思性对话。你在加利福尼亚生活了21年,将旧金山视为家。你是一名教师,经常旅行,不喜欢开会”。
2. 面向助手与客服角色的合成对话训练
为覆盖更广泛的任务场景,PersonaPlex补充训练了两类合成对话数据:
- 39322段助手角色对话(410小时);
- 105410段客服角色对话(1840小时)。
这些对话文本由Qwen3-32B与GPT-OSS-120B生成,语音则通过Chatterbox TTS合成。针对不同场景,研发团队设计了差异化的文本提示:
- 助手场景:采用固定提示“你是一位智慧且友好的老师。以清晰且引人入胜的方式回答问题或提供建议”;
- 客服场景:提示包含完整的角色信息,如组织名称、姓名、产品价格、服务规则等,确保模型能精准完成任务。
混合训练的优势在于:真实对话赋予模型自然的交互模式,合成对话则强化了模型的任务遵循能力,两者结合实现了“自然对话+精准服务”的双重目标。
核心发现:从训练中提炼的三大关键结论
英伟达在PersonaPlex的训练实验中,得出了三个具有指导性的结论:
- 预训练基础赋能高效专业化:基于Moshi的预训练权重,仅需不到5000小时的定向数据微调,就能让模型具备任务遵循能力。预训练模型的通用对话技能被完整保留,同时新增了提示引导的行为控制能力;
- 语音自然度与任务遵循度解耦:合成数据能提供丰富的人设与场景,但合成音频缺乏真实对话的行为多样性;Fisher语料库的真实对话虽场景有限,却包含了TTS难以模拟的自然语音模式。混合训练让模型同时具备了真实语音交互风格与精准的任务执行能力;
- 超越训练领域的涌现泛化能力:实验表明,PersonaPlex能处理训练数据中未覆盖的场景(如反应堆物理相关的技术危机管理),不仅能理解专业词汇,还能匹配相应的情感紧迫性。这种泛化能力,源于预训练Moshi所使用的Helium语言模型的广泛语料积累。
评估体系:双基准测试验证模型性能
PersonaPlex的性能通过两套基准测试验证,全面覆盖对话自然度与任务完成度:
- FullDuplexBench:成熟的对话AI基准,主要评估话轮转换、用户打断、停顿处理等对话动态指标,同时使用GPT-4o作为评判员,打分评估响应内容质量;
- ServiceDuplexBench:英伟达基于FullDuplexBench扩展的基准,新增了各类客服角色与场景,专门用于验证模型在实际服务场景中的任务遵循能力。
测试结果显示,PersonaPlex在对话动态、响应延迟、任务完成度等维度,均优于现有开源与商业对话AI系统。
可用性与开源信息
- 代码与模型权重:代码基于MIT许可证开源,模型权重遵循英伟达开放模型许可证发布;
- 基础模型授权:底层Moshi模型由Kyutai提供,遵循CC-BY-4.0许可证;
- 基准测试发布:ServiceDuplexBench基准测试将在近期正式发布。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











