Cosmos-Predict2 是由英伟达推出的新一代物理世界基础模型,专为物理 AI 场景下的高质量视觉生成与预测任务设计。该模型具备高度的物理准确性、环境交互能力以及细节还原度,能够真实模拟复杂的动态场景与物理现象。
它支持多种生成方式,包括文本到图像(Text-to-Image)和视频到世界(Video-to-World),可广泛应用于工业仿真、自动驾驶、城市规划、科学研究等多个领域,是连接智能视觉与现实世界的重要工具。
- 模型:https://huggingface.co/Comfy-Org/Cosmos_Predict2_repackaged
- 模型:https://www.modelscope.cn/models/Comfy-Org/Cosmos_Predict2_repackaged (国内用户请从此链接下载)
- GGUF版模型:https://huggingface.co/city96/Cosmos-Predict2-14B-Text2Image-gguf
- GGUF版模型:https://www.modelscope.cn/models/city96/Cosmos-Predict2-14B-Text2Image-gguf
本文将详细介绍如何在 ComfyUI 中配置并运行 Cosmos-Predict2 的文生图与视频生成工作流。此模型有2B和14B两个的版本,14B对于显存的要求更大,如果你显存不足,请使用GGUF版本模型。
一、文生图(Text-to-Image)工作流
1. 硬件要求
对于 2B 版本模型,在实际运行时需要约 10GB 显存。
2. 下载资源
模型文件
- Diffusion Model:
cosmos_predict2_2B_t2i.safetensors - Text Encoder:
oldt5_xxl_fp8_e4m3fn_scaled.safetensors - VAE:
wan_2.1_vae.safetensors
其他权重文件请前往 Cosmos_Predict2_repackaged 页面下载。
工作流文件
请从官方的工作流加载对应的工作流 .json 文件。
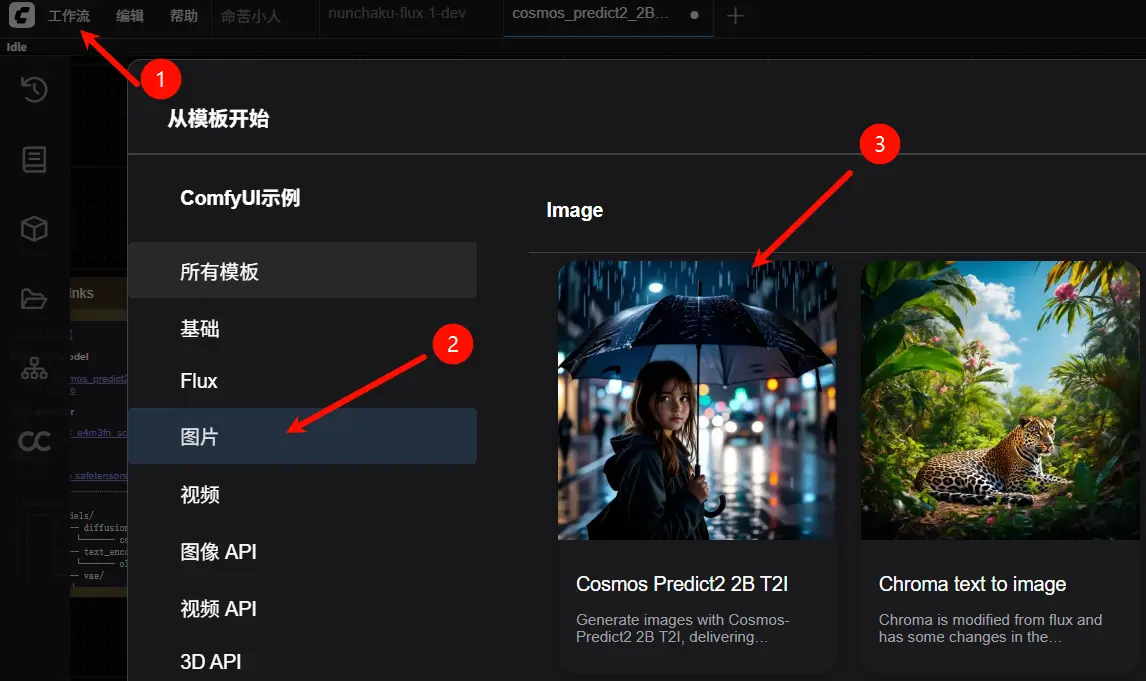
3. 安装步骤
将上述模型文件分别放置于 ComfyUI 的以下目录:
- Diffusion Model:
models/diffusion_models/ - Text Encoder:
models/clip/ - VAE:
models/vae/
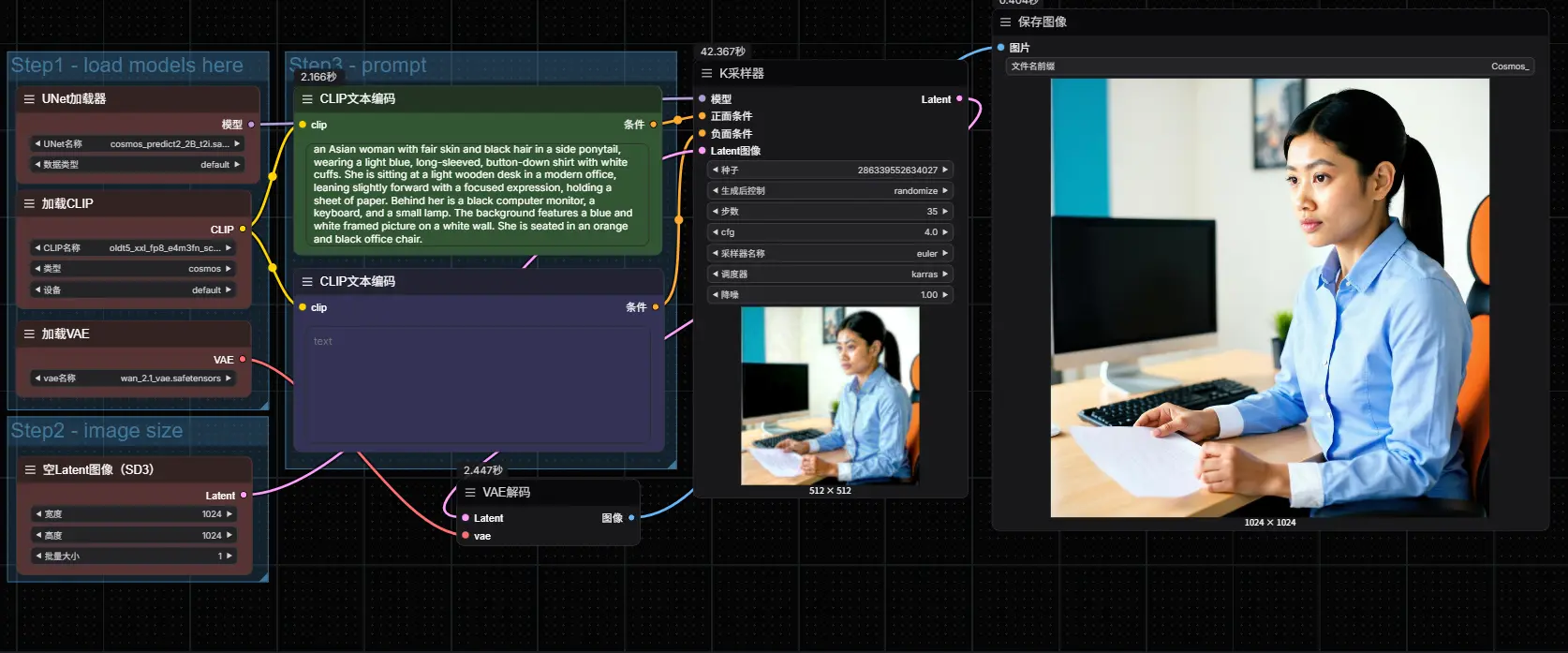
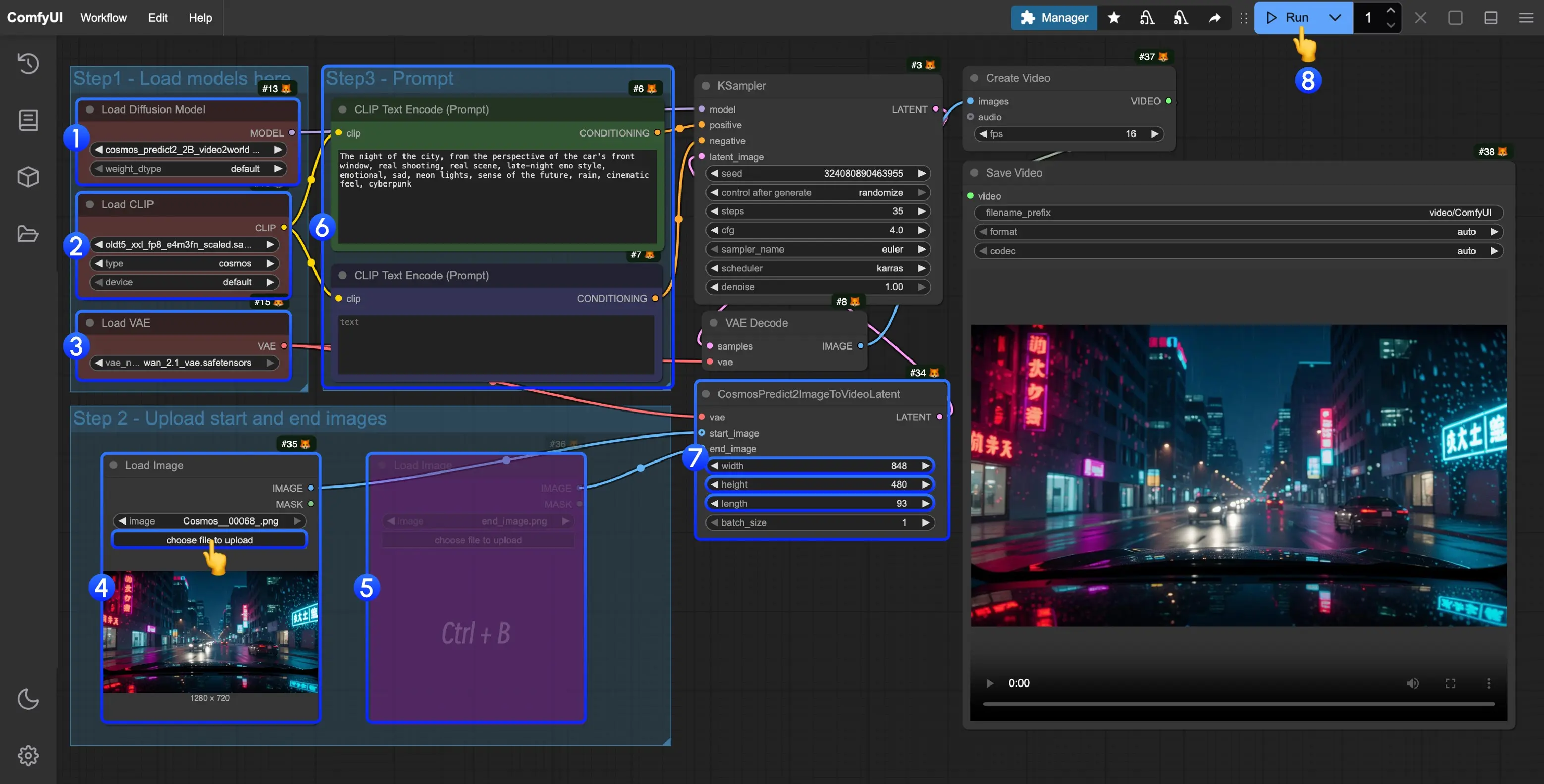
4. 执行流程
按照以下顺序确认节点设置:
- Load Diffusion Model 节点加载
cosmos_predict2_2B_t2i.safetensors - Load CLIP 节点加载
oldt5_xxl_fp8_e4m3fn_scaled.safetensors - Load VAE 节点加载
wan_2.1_vae.safetensors - 使用 EmptySD3LatentImage 设置输出图像尺寸
- 在 ClipTextEncode 节点中输入或修改提示词(Prompt)
- 点击 Run 或使用快捷键
Ctrl/Cmd + Enter开始生成 - 生成完成后,图片会自动保存至
ComfyUI/output/目录,也可通过 Save Image 节点调整输出路径或预览结果
二、视频生成(Video-to-World)工作流
1. 硬件要求
在测试过程中,2B 版本大约占用 16GB 显存。
2. 下载资源
模型文件
- Diffusion Model:
cosmos_predict2_2B_video2world_480p_16fps.safetensors - Text Encoder:
oldt5_xxl_fp8_e4m3fn_scaled.safetensors - VAE:
wan_2.1_vae.safetensors
同样建议访问 Cosmos_Predict2_repackaged 获取完整模型包。
3. 安装步骤
与文生图一致,将模型文件放入对应的 ComfyUI 子目录中。
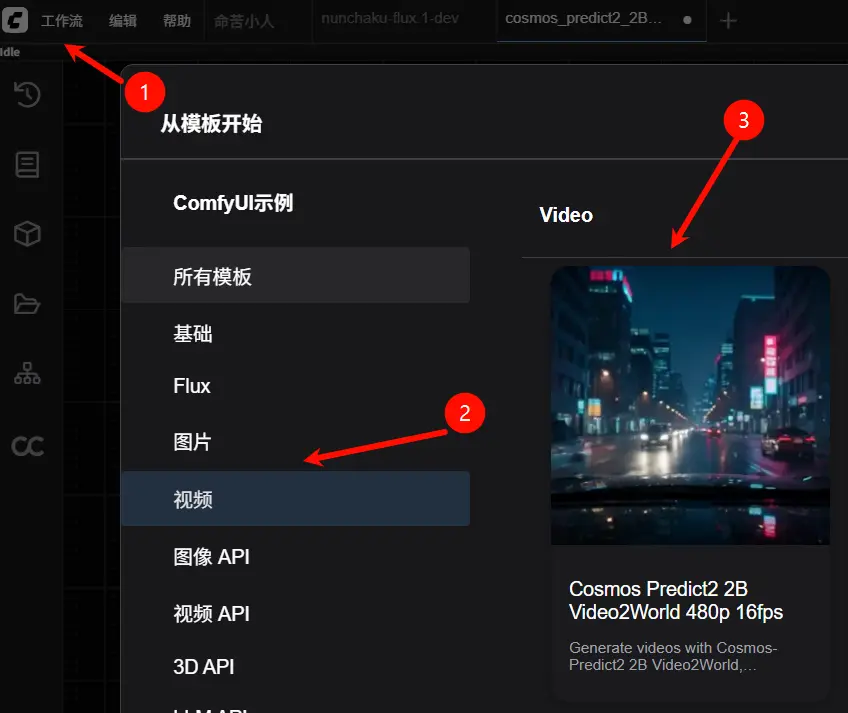
4. 执行流程
按序检查以下节点设置:
- Load Diffusion Model 加载
cosmos_predict2_2B_video2world_480p_16fps.safetensors - Load CLIP 加载
oldt5_xxl_fp8_e4m3fn_scaled.safetensors - Load VAE 加载
wan_2.1_vae.safetensors - 使用 Load Image 节点上传输入图像作为视频起始帧
- (可选)按下快捷键
Ctrl/Cmd + B启用尾帧输入控制 - (可选)可在 ClipTextEncode 中修改提示词
- (可选)调整 CosmosPredict2ImageToVideoLatent 中的分辨率与帧数参数
- 点击 Run 或使用快捷键执行生成
- 视频结果默认保存在
ComfyUI/output/,可通过 Save Video 节点进行预览或路径更改
三、常见问题排查
如果你在加载工作流文件时遇到节点缺失问题,请检查以下几点:
- 是否使用的是 ComfyUI 的最新开发版(Nightly)?
- 若使用稳定版(Release)或桌面版(Desktop),可能未包含部分新功能。
- 检查启动日志,确认是否出现节点导入失败的情况。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











