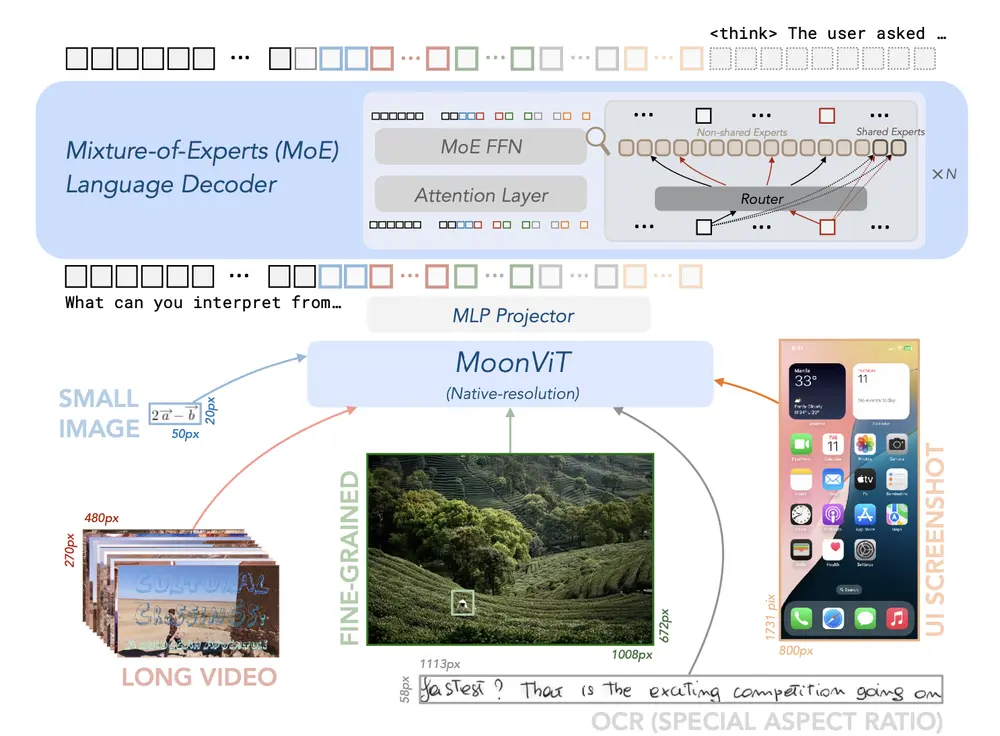
在物理AI(Physical AI)系统的开发中,模拟真实世界的动态变化至关重要。为此,英伟达推出了 Cosmos-Predict2,作为其 Cosmos 世界模型 的最新演进版本,专为生成具有物理感知能力的图像与视频而设计,助力机器人、自动驾驶车辆等领域的智能系统训练与测试。
什么是 Cosmos-Predict2?
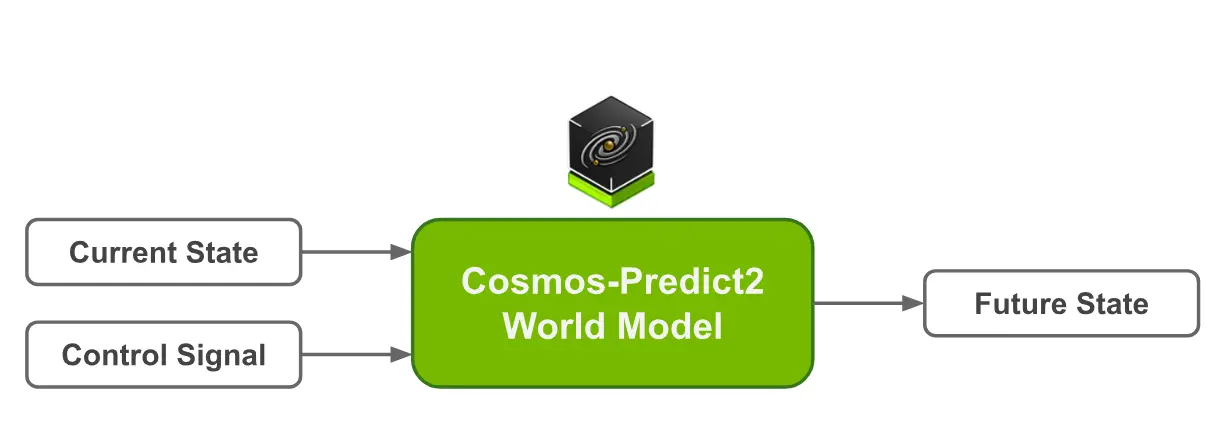
Cosmos-Predict2 是一组基于扩散机制的世界基础模型(World Models),能够根据文本描述或输入图像/视频,预测并生成未来世界状态的高质量图像与视频。它不仅支持多种任务类型,还提供了灵活的分辨率与帧率选项,适用于不同硬件平台和应用场景。
- 项目主页:https://research.nvidia.com/labs/dir/cosmos-predict2
- GitHub:https://github.com/nvidia-cosmos/cosmos-predict2
- 模型:https://huggingface.co/collections/nvidia/cosmos-predict2-68028efc052239369a0f2959
模型组成
目前,Cosmos-Predict2 包含以下四种模型:
- Cosmos-Predict2-2B-Text2Image
根据文本生成单张图像,适合快速原型验证。 - Cosmos-Predict2-14B-Text2Image
更大参数量版本,生成质量更高,适合高保真场景。 - Cosmos-Predict2-2B-Video2World
接收初始帧与文本提示,生成后续时间一致的视频序列,适用于低延迟应用。 - Cosmos-Predict2-14B-Video2World
高性能版本,具备更强的时间一致性与细节还原能力,适合复杂场景建模。
所有模型均在 英伟达开放模型许可协议 下发布,包含代码、权重与基准测试工具(PBench),支持商业用途。
技术亮点
架构优化,性能提升
Cosmos-Predict2 在架构层面进行了多项优化,显著提升了推理速度、可扩展性以及对不同用例的支持能力:
- 分辨率支持:704p(接近720p)和480p,后者更适合对速度要求更高的场景。
- 帧率支持:当前提供10fps和16fps,未来将支持24fps,满足自动驾驶等领域的模拟需求。
- 多平台适配:在 NVIDIA GB200 NVL72、DGX B200 和 RTX PRO 6000 等设备上运行流畅。
例如,在 GB200 平台上,2B 版本可在5秒内完成图像预览,14B 版本则在保持高质量的同时实现高效输出。
应用场景与后训练指南
Cosmos-Predict2 不仅是一个开箱即用的模型,也支持开发者根据特定领域进行后训练(Post-training),以适应机器人、自动驾驶、工业自动化等实际应用。
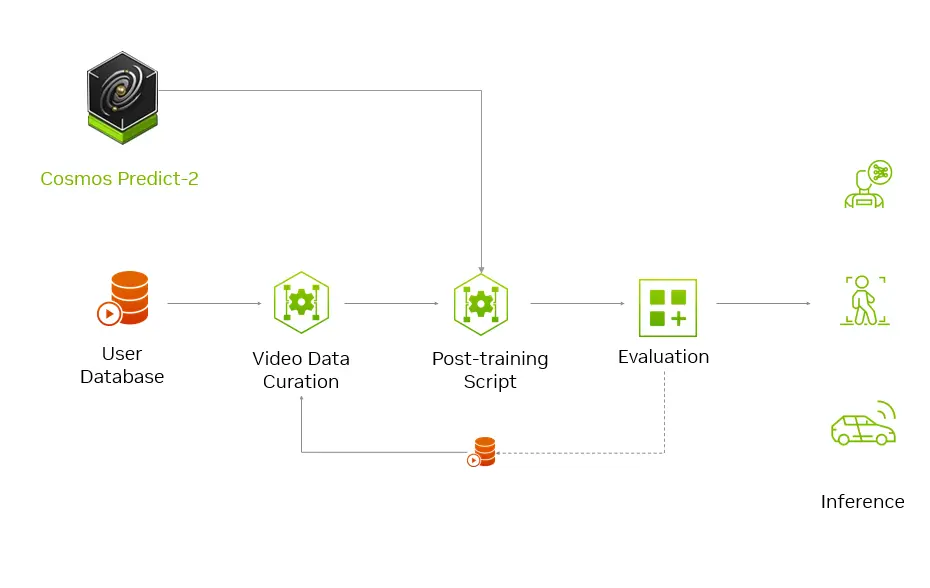
示例任务:机器人拾取苹果
开发者可以使用 Cosmos-Predict2 来生成用于训练机器人的合成数据。例如:
- 输入提示:“在低光下拾取瘀伤的苹果”
- 使用初始图像引导生成“梦境”视频
- 利用生成数据训练机械臂抓取动作
后训练流程简要如下:
- 准备数据
- 收集约100小时的操作视频
- 使用工具分割片段,并确保涵盖目标物体、光照条件等关键因素
- 可配合视觉语言模型(如 Cosmos Reason)生成字幕标签
- 后训练模型
- 使用 GitHub 上的脚本对 Cosmos-Predict2 进行微调
- 聚焦于特定任务(如抓取、避障)
- 生成合成场景
- 输入文本或图像,生成定制化的视频内容
- 用于模拟罕见事件、极端环境等训练样本
- 验证物理准确性
- 使用 Cosmos Reason 模型进行评估:
- 是否正确抓取?
- 关节角度是否合理?
- 是否存在碰撞或运动伪影?
- 使用 Cosmos Reason 模型进行评估:
该流程支持持续迭代优化,从而不断提升合成数据质量与下游模型表现。
行业应用一览
| 领域 | 典型操作 | 应用示例 |
|---|---|---|
| 机器人 | 指令控制、物体操作 | 调整手臂力度以拾取不同硬度的水果 |
| 自动驾驶 | 多视角生成、边缘案例模拟 | 模拟雨天高速行驶,同步激光雷达与摄像头数据 |
| 工业 | 动作条件工作流程 | 传送带机器人预测性维护 |
| 视觉 | 相机姿态控制 | 从单图生成3D一致性视频 |
生态整合:Cosmos 家族协同工作
Cosmos-Predict2 并非孤立存在,而是与一系列世界基础模型协同构建完整的物理AI开发闭环:
- Cosmos Reason:时空感知推理模型,用于解释视觉输入、执行链式推理、验证生成内容。
- Cosmos Transfer:增强合成数据多样性,支持光照、材质、环境等维度调整,提升泛化能力。
通过这一生态体系,开发者可以实现:
- 后训练 → 生成 → 验证 → 优化 的完整循环
- 快速迭代模型,加速特定领域应用落地
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











