MiniCPM-o 2.6 是面壁智能推出的 MiniCPM-o 系列中最新且功能最强大的模型。该模型基于 SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和 Qwen2.5-7B 构建,采用端到端设计,总参数量为 8B。相比 MiniCPM-V 2.6,MiniCPM-o 2.6 在性能上有显著提升,并引入了实时语音对话和多模态直播的新功能。
- GitHub:https://github.com/OpenBMB/MiniCPM-o
- 模型:https://huggingface.co/openbmb/MiniCPM-o-2_6
- GGUF版本:https://huggingface.co/openbmb/MiniCPM-o-2_6-gguf
- Demo:https://minicpm-omni-webdemo-us.modelbest.cn
主要亮点功能:
- 领先的视觉能力:在OpenCompass基准测试中取得了70.2分的平均成绩,在单图像理解任务方面超越了GPT-4o-202405、Gemini 1.5 Pro和Claude 3.5 Sonnet等知名模型。同时,在处理多图像和视频理解任务时也表现出了优越性。
- 顶尖的语音能力:支持中英双语实时语音对话,并允许用户根据需要调整语音风格。它在ASR(自动语音识别)和STT(语音转文字)翻译等任务中的表现超过了GPT-4o-realtime,同时还支持情感控制、速度调节、风格选择及角色扮演等功能。
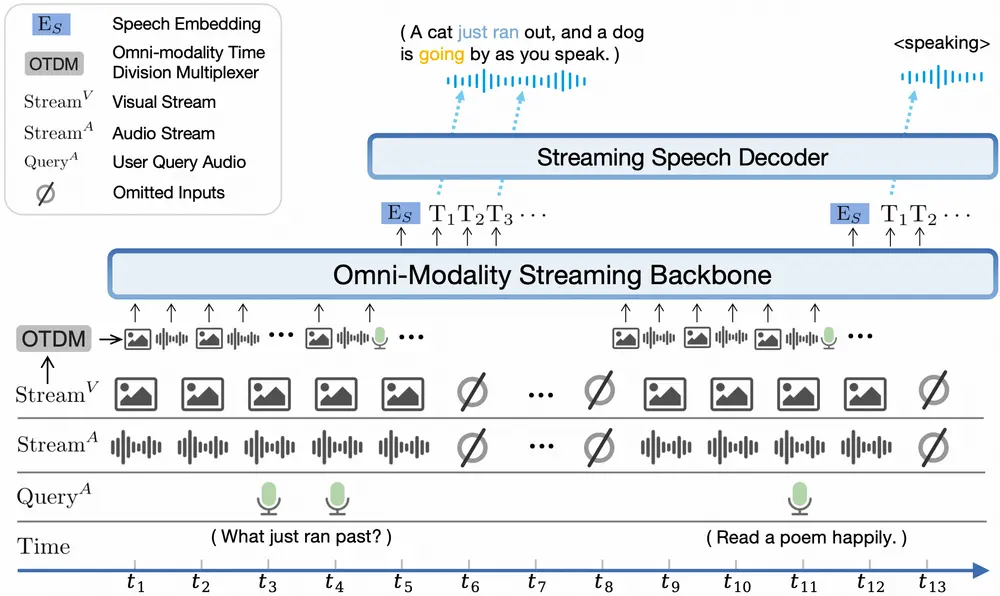
- 强大的多模态直播能力:新增独立于用户查询接受连续视频和音频流的功能,并支持实时语音交互。在StreamingBench测试平台上,其性能优于GPT-4o-realtime和Claude 3.5 Sonnet,特别擅长实时视频理解和全源(视频和音频)理解。
- 卓越的OCR能力和更多特性:继承并优化了MiniCPM-V系列的OCR技术,在处理高分辨率图像时表现出色。支持超过30种语言的多语言能力,并且基于RLAIF-V和VisCPM技术,确保了行为的可信赖性。
- 高效的运行效率:通过减少每个视觉token编码的像素数量来提高推理速度、降低首token延迟、节省内存使用和能耗,使得该模型可以在iPad等移动设备上流畅运行多模态直播。
- 易于使用的部署选项:提供多种部署方式,包括llama.cpp支持本地CPU推理、提供int4和GGUF格式量化模型、vLLM支持高效推理、LLaMA-Factory用于微调新领域任务以及Gradio快速搭建本地WebUI演示等。
模型架构创新:
- 端到端全模态架构:实现了不同模态间编码器/解码器的无缝连接与训练。
- 全模态直播机制:采用在线版本的模态编码器/解码器,并设计了时分复用(TDM)机制以处理流式输入输出。
- 灵活的语音建模设计:允许在推理阶段动态配置语音特征,如声音风格等,增强了用户体验的个性化程度。
总之,MiniCPM-o 2.6代表了当前多模态大模型技术的一个重要进展,特别是在移动设备上的应用前景广阔。无论是对于开发者还是普通用户来说,这款模型都提供了前所未有的便捷性和功能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











