尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放研究进一步阻碍了视频 LMMs 的发展。
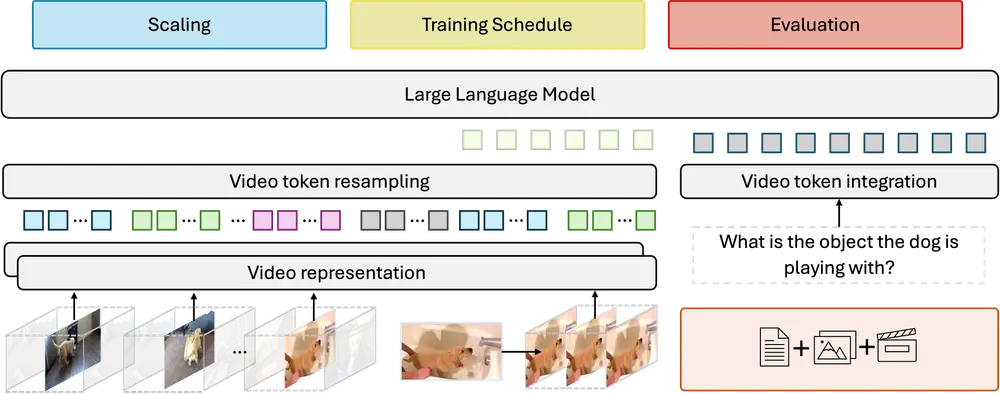
为了应对这一挑战,Meta 和斯坦福大学的研究人员进行了一项全面的研究,旨在揭示有效驱动 LMMs 视频理解的关键因素。通过这项研究,他们不仅批判性地审视了高计算需求的主要贡献者,还探索了视频 LMMs 的多个视频特定方面,包括视频采样、架构、数据组成、训练计划等。
关键发现
- 规模一致性:研究发现,规模一致性是关键。即,在较小模型和数据集上做出的设计和训练决策能够在达到临界规模后有效地转移到更大模型上。这一发现意味着研究人员可以在较小的实验环境中测试和验证假设,从而显著降低开发成本和时间。
- fps 采样优于均匀帧采样:在视频处理中,fps 采样(即基于帧率的采样)远优于传统的均匀帧采样。fps 采样能够更好地捕捉视频中的动态信息,确保模型在处理连续帧时不会遗漏重要的时间依赖性特征。这对于理解长视频尤其重要,因为均匀帧采样可能会忽略快速变化的场景或动作。
- 视觉编码器的选择:研究确定了哪些视觉编码器最适合视频表示。不同的编码器在处理静态图像和动态视频时的表现差异显著,选择合适的编码器可以显著提升模型的性能。例如,某些编码器在处理长时间依赖性方面表现更好,而另一些则在捕捉短时间内的细节变化上更具优势。
- 数据组成的重要性:数据集的组成对模型性能有重要影响。研究表明,包含多样化的视频内容(如不同长度、分辨率、主题等)的数据集能够更好地训练出泛化能力强的模型。此外,数据集的标注质量也至关重要,高质量的标注可以提高模型的理解能力。
- 训练计划的优化:优化训练计划可以显著提升模型的收敛速度和最终性能。研究发现,适当的预训练策略、学习率调度以及正则化技术能够帮助模型更有效地学习视频中的复杂模式。
Apollo:卓越的视频 LMMs 系列
基于上述发现,Meta 和斯坦福大学的研究人员引入了 Apollo,这是一系列在不同模型规模上表现卓越的 LMMs。Apollo 系列模型特别擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力。
- Apollo-3B:在 LongVideoBench 上以 55.1 的分数超越了大多数现有的 7B 模型。LongVideoBench 是一个专门用于评估模型处理长视频能力的基准,Apollo-3B 的表现证明了其在处理长时间依赖性方面的强大能力。
Apollo-7B:在与其他 7B LMMs 的比较中表现出色,特别是在 MLVU(Multimodal Language and Video Understanding)和 Video-MME(Video Multi-Modal Evaluation)两个基准上分别达到了 70.9 和 63.3 的分数,均处于领先地位。MLVU 和 Video-MME 分别评估了模型在多模态理解和视频生成任务中的表现,Apollo-7B 的优异成绩表明它在这些任务上具有强大的竞争力。
例如,在视频采样方面,研究表明以帧率(fps)进行采样比均匀采样更有效。通过在训练中使用fps采样,Apollo模型能够更好地捕捉视频中的动态信息,从而提高理解能力。
- 项目主页:https://apollo-lmms.github.io
- GitHub:https://github.com/Apollo-LMMs/Apollo
- 模型:https://huggingface.co/Apollo-LMMs
- Demo:https://huggingface.co/spaces/Apollo-LMMs/Apollo-3B
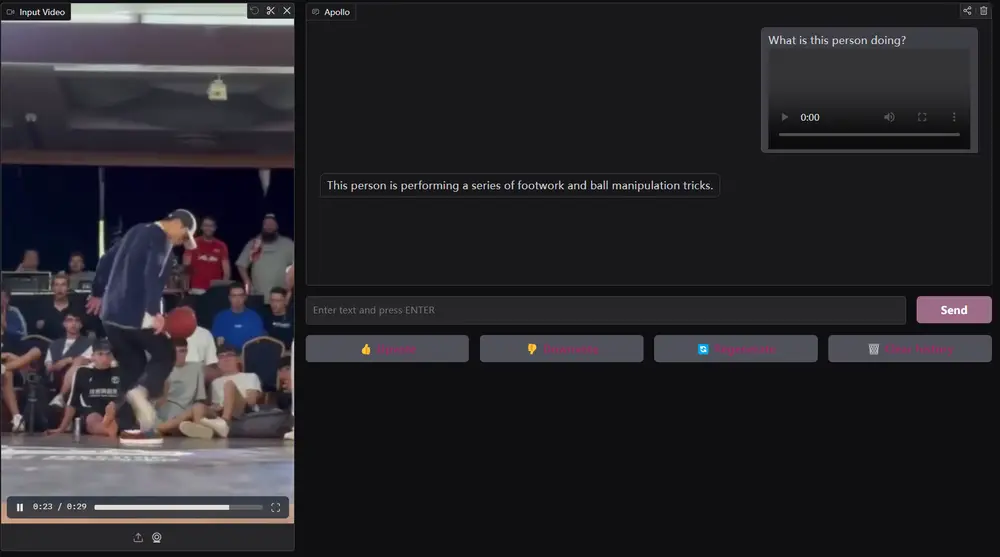
主要功能
- 视频理解:Apollo能够处理长达数小时的视频,进行复杂的理解和分析。
- 多模态融合:结合文本、图像和视频数据,提升模型的综合理解能力。
- 高效评估:引入ApolloBench基准,显著提高评估效率,同时保持高质量的评估结果。
主要特点
- Scaling Consistency:设计决策在小型模型和大型模型之间的有效转移,降低了计算成本。
- 视频特定设计:针对视频的采样、编码和训练策略进行了深入探索,提供了实用的设计指南。
- 状态-of-the-art性能:在多个视频理解基准上,Apollo模型表现优异,尤其是在7B参数模型中超越了许多30B参数的模型。
工作原理
Apollo模型通过以下几个步骤进行工作:
- 视频采样:使用fps采样策略,从视频中提取关键帧。
- 编码:应用多种视觉编码器(如InternVideo2和SigLIP)对视频帧进行编码,提取特征。
- 特征融合:将视频特征与文本特征进行融合,形成统一的表示。
- 训练与评估:通过多阶段训练策略,优化模型性能,并利用ApolloBench进行高效评估。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...