快手 Keye 团队近日推出了一款全新的多模态大型语言模型(MLLM)——Kwai Keye-VL。该模型拥有 80 亿参数,专注于提升对短视频的理解能力,同时保持强大的通用视觉-语言能力。
- GitHub:https://github.com/Kwai-Keye/Keye
- 模型:https://huggingface.co/Kwai-Keye/Keye-VL-8B-Preview
- Demo:https://huggingface.co/spaces/Kwai-Keye/Keye-VL-8B-Preview
在当前以短视频为主流媒介的数字环境中,用户经常分享包含复杂事件序列、因果关系和整体叙事的视频内容。传统的多模态模型大多仅处理静态图像,而 Kwai Keye-VL 则能够理解这些动态信息,生成相关描述、回答问题并进行推理,标志着视频理解能力的重大突破。
Kwai Keye-VL 模型架构
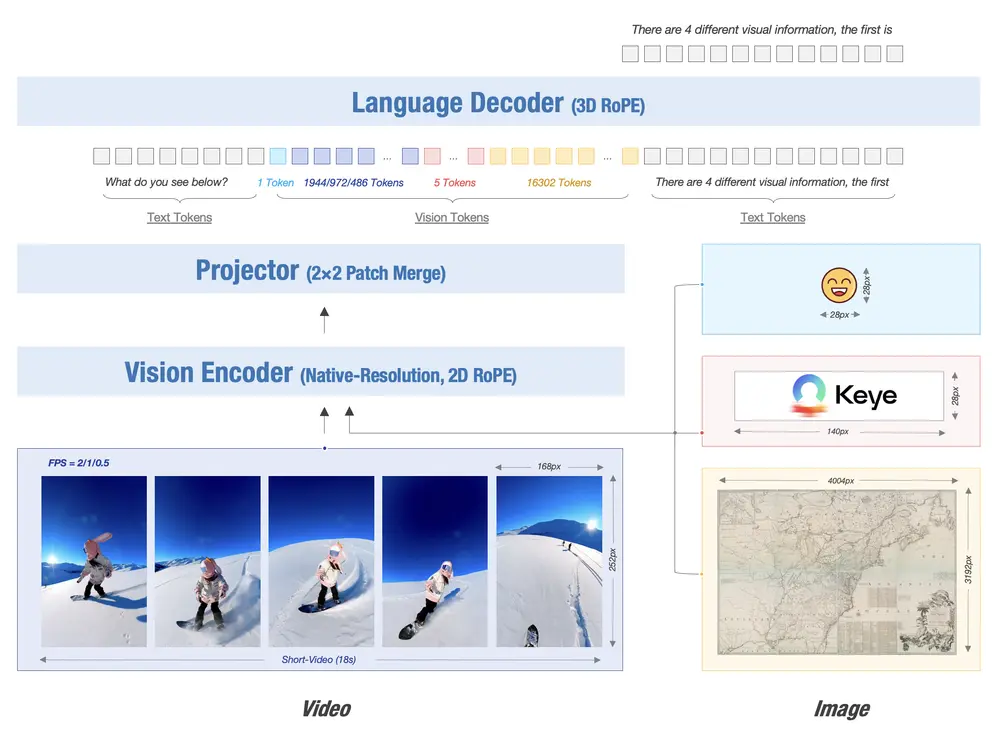
Kwai Keye-VL 基于 Qwen3-8B 语言模型构建,并集成了从开源 SigLIP 初始化的视觉编码器。该模型支持原生动态分辨率,通过将每张图像分割为 14x14 的 patch 序列来保留原始图像的纵横比。
随后,一个简单的 MLP 层用于映射和融合视觉 token。为了统一处理文本、图像和视频信息,Kwai Keye-VL 引入了 3D RoPE 技术,建立位置编码与绝对时间的一一对应,从而实现对视频中时间变化的精确感知。
主要功能
- 短视频理解:理解短视频内容,包括事件序列、因果关系和整体叙事。
- 视觉问答(VQA):回答与视频或图像相关的问题。
- 图像描述生成:为图像生成详细描述。
- 视觉推理:基于视觉信息进行逻辑推理。
- 多模态指令遵循:根据多模态指令执行任务,例如根据视频内容生成代码。
- 自动推理决策:根据任务复杂性自动决定是否启用深度推理模式。
🌟 预训练
预训练数据:海量、高质量、多样化
- 多样性:涵盖图像-文本对、视频、纯文本等多种形式,任务类型包括细粒度描述、OCR、问答、定位等。
- 高质量:使用 CLIP 分数和 VLM 判别器筛选数据,并采用 MinHASH 进行去重,防止数据泄露。
- 自建数据集:专门构建高质量内部数据集,特别是在详细描述和中文 OCR 方面弥补开源数据的不足。
训练过程:四阶段渐进优化
Kwai Keye-VL 采用四阶段渐进式训练策略,逐步提升模型性能:
- 阶段 0(视觉预训练):持续预训练视觉编码器,使其适应内部数据分布并支持动态分辨率。
- 阶段 1(跨模态对齐):冻结骨干模型,仅训练 MLP,以低成本建立稳健的图像-文本对齐。
- 阶段 2(多任务预训练):解锁所有参数,全面提升模型的视觉理解能力。
- 阶段 3(退火训练):使用高质量数据微调,进一步提升模型的细粒度理解能力。
此外,Kwai Keye-VL 还探索了同构异质融合技术,通过对不同数据比例的退火训练模型进行参数平均,减少偏差,同时保留多维能力,增强模型鲁棒性。
🌟 后训练
Kwai Keye-VL 的后训练阶段分为两个阶段共五个步骤,旨在全面提升模型性能,尤其是在复杂任务中的推理能力,这是实现高级认知功能的关键突破。
阶段 I. 无推理训练:增强基础性能
阶段 II.1:监督微调(SFT)
- 数据组成:包含 500 万多模态数据,基于 TaskGalaxy 框架构建的多样化任务分类系统(7 万个任务)。数据由多模态大模型挑选高难度样本并人工标注,确保质量与挑战性。
阶段 II.2:混合偏好优化(MPO)
- 数据组成:包括开源数据和纯文本偏好数据。使用 SFT 模型的错误案例作为提示,通过 Qwen2.5VL-72B 和 SFT 模型生成偏好数据,并进行人工评分与排序。
阶段 II. 推理训练:复杂认知的核心突破
步骤 II.1:CoT 冷启动
- 目标:冷启动模型的思维链推理能力,使其模仿人类逐步思考的过程。
- 数据组成:结合非推理数据(33 万)、推理数据(23 万)、自动推理数据(2 万)和代理推理数据(10 万),教授模型不同的推理模式。
- 思维数据:聚焦数学、科学、图表、复杂中文和 OCR 等高难度场景,使用多模态大模型构建超过 7 万条复杂思维链数据。
- 纯文本数据:构建代码、数学、科学、指令遵循和通用推理任务的长思维链数据集。
- 自动思维数据:根据提示复杂性自动选择“思考”或“无思考”模式,实现自适应推理切换。
- 图像思维数据:10 万条代理数据,询问 Qwen 2.5 VL-72B 是否需要图像操作(如裁剪、旋转、对比度增强)以提高答案质量,结合外部沙箱代码执行,使模型可通过编写代码操作图像或进行数学计算。
- 训练策略:混合四种模式进行训练,实现多种推理方式的冷启动。
步骤 II.2:CoT 混合强化学习
- 目标:通过思维链强化学习,深度优化模型在多模态感知、推理、纯文本数学、短视频理解和代理任务中的综合能力。
- 数据组成:涵盖多模态感知(复杂文本识别、物体计数)、多模态推理、高难度数学问题、短视频理解及图像思维任务。
- 训练策略:使用 GRPO 算法进行强化学习,奖励信号评估结果正确性和推理过程一致性,实现推理流程与结果同步优化。
步骤 II.3:迭代对齐
- 目标:解决模型输出重复崩溃和逻辑不佳问题,使模型可根据问题复杂性智能选择推理模式,提升最终性能与稳定性。
- 数据组成:通过拒绝微调(RFT)构建偏好数据,结合规则评分(判断重复、指令遵循)和模型评分(认知分数)对响应进行排名,构建高质量偏好数据集。
- 训练策略:通过 MPO 算法使用“好/坏”偏好数据对进行多轮迭代优化,纠正生成缺陷,并使模型能根据问题复杂性自适应选择是否激活深度推理模式。
实验结果
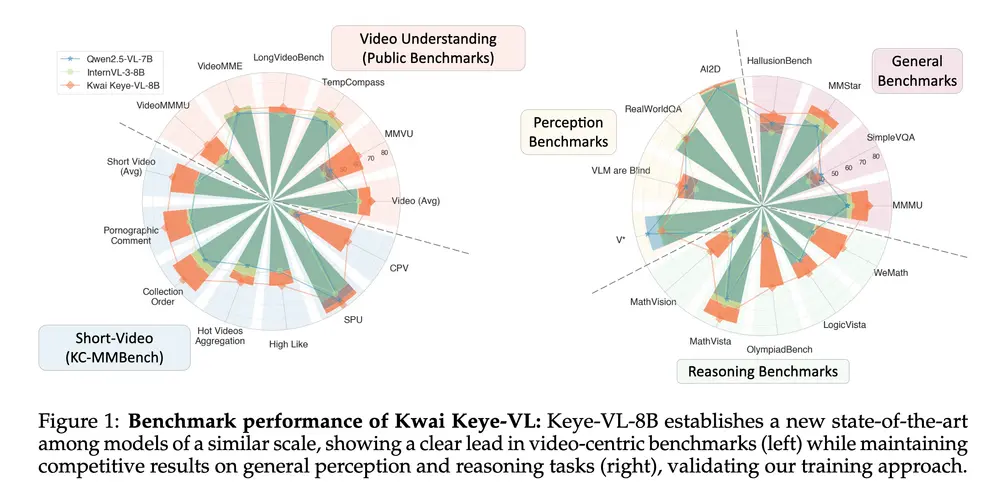
Kwai Keye-VL-8B 凭借其强大的感知能力,在多个权威基准测试中表现优异:
- 在 Video-MME、Video-MMMU、TempCompass、LongVideoBench 和 MMVU 等视频理解评测中,显著优于其他同类模型。
- 在 WeMath、MathVerse 和 LogicVista 等需复杂逻辑推理和数学问题求解的评估集中,展现出卓越的性能曲线,凸显其在逻辑推导和定量问题解决方面的先进能力。
- 在快手自建的 Kuaishou Community Multimodal Benchmark(KC-MMBench)中,表现出显著优势。
- 内部用户体验评估显示,Kwai Keye-VL 在视频与图像任务中提供优于其他类似规模模型的交互体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











