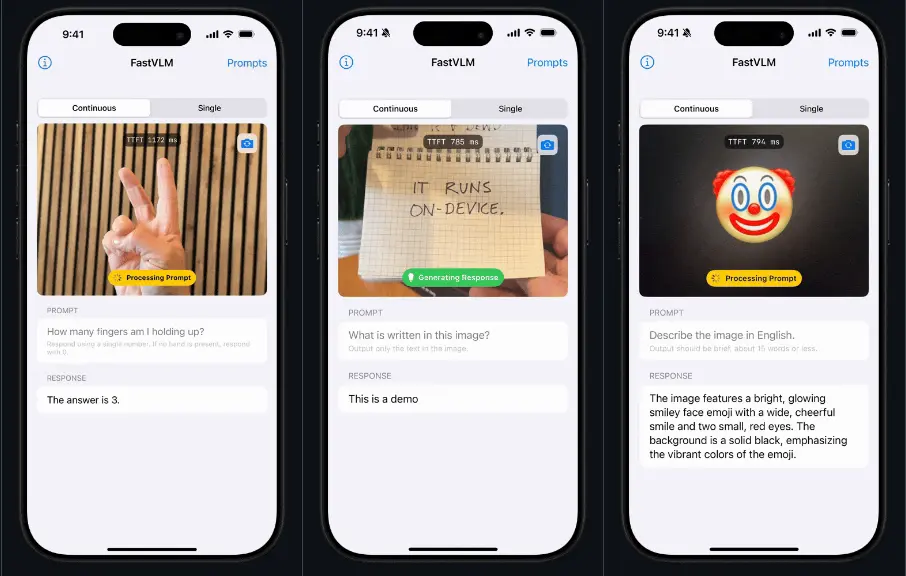
苹果推出一种高效视觉语言模型FastVLM,旨在通过优化视觉编码器(Vision Encoder)来提高模型在处理高分辨率图像任务时的效率和性能。FastVLM的核心是其创新的视觉编码器 FastViTHD,它能够在保持高分辨率输入的同时显著减少视觉令牌(Visual Tokens)的数量和编码时间。模型目前分 FastVLM-0.5B,FastVLM-1.5B,FastVLM-7B 三个版本,此模型可以在 ANE 上运行 (Apple 芯片内置的神经网络计算单元, 可以理解为 Apple 版本的 NPU)。
例如,在处理复杂的图文理解任务时,如识别图表中的数据或文档中的文字内容,传统的视觉语言模型(如基于ViT的模型)可能会因为高分辨率图像导致的大量视觉令牌和高延迟而表现不佳。而FastVLM通过其高效的视觉编码器,能够快速处理高分辨率图像,同时减少视觉令牌的数量,从而显著提高模型的响应速度和性能。
主要功能
FastVLM的主要功能包括:
- 高效的视觉编码:通过FastViTHD编码器,FastVLM能够高效处理高分辨率图像,减少视觉令牌数量,从而降低整体延迟。
- 多任务适应性:FastVLM可以在多种视觉语言任务中表现出色,如视觉问答(VQA)、图文理解、文档理解等。
- 可扩展性:FastVLM支持不同分辨率的输入,并且可以通过调整训练数据量和模型大小来进一步优化性能。
主要特点
FastVLM的主要特点如下:
- 创新的视觉编码器:FastViTHD结合了卷积和变换器(Transformer)的优点,能够在高分辨率下高效生成视觉令牌。
- 显著的性能提升:在保持高分辨率输入的同时,FastVLM在多个基准测试中表现出色,与现有方法相比,时间延迟大幅降低。
- 灵活性和可扩展性:FastVLM可以通过调整输入分辨率和训练数据量来适应不同的任务需求,同时保持高效的性能。
工作原理
FastVLM的工作原理主要基于以下几个方面:
- 视觉编码器优化:FastViTHD通过引入多尺度特征提取和高效的卷积层,减少了视觉令牌的数量,同时保持了图像的高分辨率输入。这种设计使得模型在处理高分辨率图像时能够显著降低编码延迟。
- 动态分辨率调整:FastVLM支持动态调整输入分辨率,可以根据任务需求选择最优的分辨率,从而在不同场景下实现最佳的性能和效率平衡。
- 视觉语言融合:FastVLM将视觉编码器生成的视觉令牌与语言模型(LLM)相结合,通过投影层(Projection Layer)将视觉信息传递给语言模型,从而实现视觉和语言的融合理解。
测试结果
根据论文中的测试结果:
- 时间延迟显著降低:在LLaVA-1.5设置下,FastVLM的时间延迟比之前的最佳方法快了3.2倍,同时在多个基准测试中保持了类似的性能。
- 性能提升:与LLaVa-OneVision相比,FastVLM在相同的0.5B语言模型下,性能相当,但时间延迟快了85倍,视觉编码器的大小也小了3.4倍。
- 数据扩展性:随着训练数据量的增加,FastVLM的性能进一步提升,表明其在大规模数据训练下具有良好的扩展性。
应用场景
FastVLM适用于多种视觉语言任务,包括但不限于:
- 视觉问答(VQA):快速准确地回答与图像内容相关的问题。
- 图文理解:理解图像中的文字内容,如图表、文档等。
- 多模态内容生成:生成与图像相关的文本描述或对话内容。
- 文档理解:解析文档中的图像和文字信息,提取关键内容。
- 移动设备上的实时视觉语言应用:由于其高效的性能,FastVLM特别适合在资源受限的移动设备上部署。
FastVLM通过其高效的视觉编码器和灵活的设计,为视觉语言任务提供了一种高性能、低延迟的解决方案,具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











