天工AI(Skywork AI)推出一个用于多模态理解和推理任务的多模态奖励模型Skywork-VL Reward,此模型是基于Qwen2.5-VL-7B-Instruct训练,Skywork-VL Reward 的目标是为视觉语言模型(VLMs)提供奖励信号,以更好地对齐人类偏好。通过构建大规模的多模态偏好数据集,并结合先进的训练方法,Skywork-VL Reward 能够评估标准 VLM 和高级 VLM 推理器的输出。
例如,在处理一个包含图像和文本提示的任务时,Skywork-VL Reward 可以评估不同 VLM 生成的回答,并为更符合人类偏好的回答分配更高的奖励分数。假设任务是根据图像内容回答问题,模型需要判断哪个回答更准确、更合理。Skywork-VL Reward 通过其训练的数据和架构,能够识别出更高质量的回答,并为其分配更高的奖励值。
主要功能
Skywork-VL Reward 的主要功能包括:
- 多模态偏好评估:能够对视觉语言模型生成的回答进行评估,判断其是否符合人类偏好。
- 支持多种任务:适用于从简单的图像描述到复杂的推理任务,覆盖广泛的多模态场景。
- 奖励信号生成:为多模态任务生成可靠的奖励信号,支持强化学习和模型优化。
- 提升推理能力:通过生成高质量的偏好数据,支持混合偏好优化(MPO),从而显著提升模型的多模态推理能力。
主要特点
Skywork-VL Reward 的主要特点如下:
- 大规模偏好数据集:通过整合多个开源数据集和内部标注数据,构建了一个包含多种任务和场景的偏好数据集。
- 双阶段训练范式:结合纯文本和多模态数据进行训练,增强模型在不同场景下的泛化能力。
- 基于 Qwen2.5-VL-7B-Instruct 的架构:利用强大的预训练 VLM 架构,并添加奖励头以输出标量奖励分数。
- 高效的奖励信号:通过成对偏好数据训练,能够有效区分高质量回答和低质量回答。
工作原理
Skywork-VL Reward 的工作原理基于以下几个核心组件:
- 数据集构建:
- 开源数据:整合了多个开源偏好数据集,如 LLaVA-Critic-113k、Skywork-Reward-Preference-80K-v0.2 和 RLAIF-V-Dataset。
- 内部数据:添加了约 50,000 个复杂推理任务的偏好比较数据,涵盖数学、物理、生物和化学等领域。
- 数据筛选:通过去重、相似性过滤和偏好过滤,确保数据的高质量和一致性。
- 模型架构:
- 基于 Qwen2.5-VL-7B-Instruct 架构,包含视觉编码器、视觉语言适配器和语言模型解码器。
- 替换原始的语言模型头,添加一个奖励头,输出标量奖励分数。
- 训练方法:
- 使用成对偏好损失函数进行训练,最大化偏好回答和非偏好回答之间的奖励差异。
- 采用双阶段训练策略,先在多模态数据上训练,再加入纯文本数据进行微调。
测试结果
Skywork-VL Reward 在多个基准测试中表现出色:
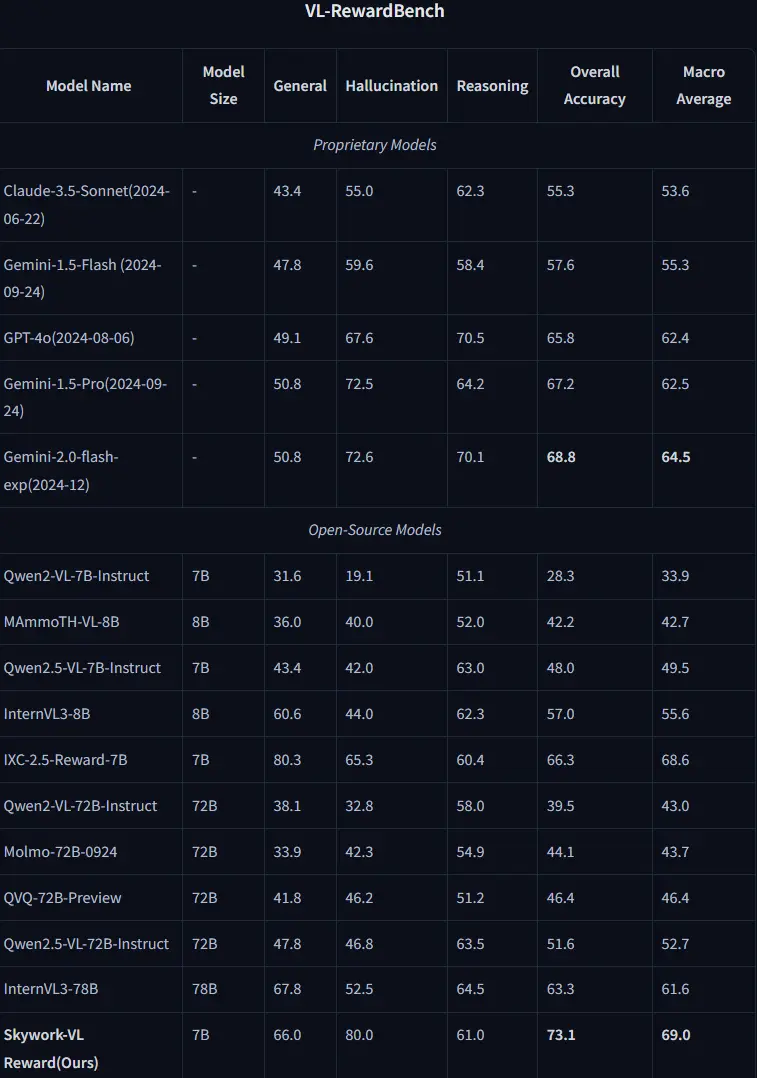
- VL-RewardBench:
- 在多模态任务中,Skywork-VL Reward 的整体准确率达到 73.1%,显著优于其他开源和专有模型。
- 在推理任务中,Skywork-VL Reward 的推理分数达到 61.0%,与参数量更大的 InternVL3-78B 相当。
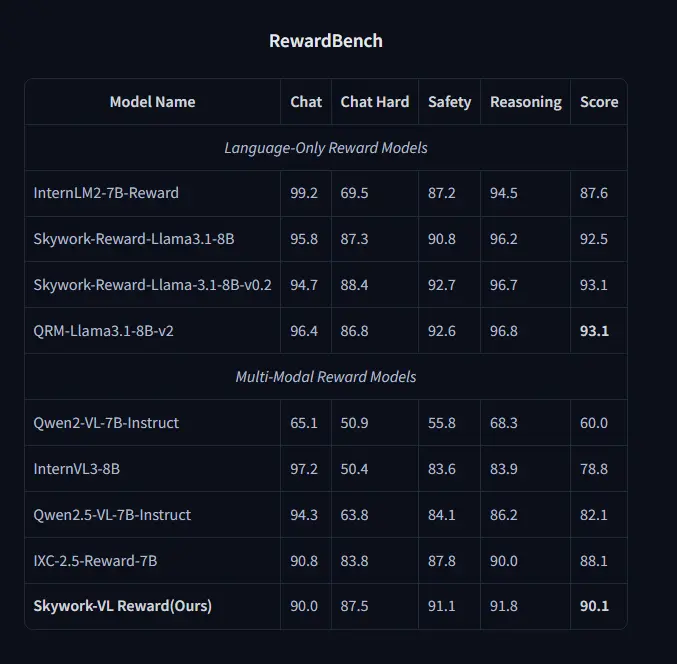
- RewardBench:
- 在纯文本任务中,Skywork-VL Reward 的平均分数达到 90.1%,在开源多模态奖励模型中表现最佳。
- 在 Chat Hard、Safety 和 Reasoning 等任务中,Skywork-VL Reward 的表现优于其他多模态模型。
- 混合偏好优化(MPO):
- 使用 Skywork-VL Reward 生成的偏好数据进行 MPO 训练,显著提升了模型在 MathVista 基准测试中的表现,从 69.2% 提升到 73.5%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...