近日,由复旦大学、上海创新创意设计研究院、上海人工智能实验室和上海人工智能科学院组成的研究团队,正式发布了全球首个支持图像与视频理解与生成任务评估的统一奖励模型 —— UNIFIEDREWARD。
- 项目主页:https://codegoat24.github.io/UnifiedReward
- GitHub:https://github.com/CodeGoat24/UnifiedReward
- 模型:https://huggingface.co/collections/CodeGoat24/unifiedreward-models-67c3008148c3a380d15ac63a
该模型突破了传统奖励模型局限于单一模态或任务的限制,实现了对视觉生成与理解任务的统一建模,为视觉模型的偏好对齐提供了更强有力的支持。
🎯 什么是 UNIFIEDREWARD?
UNIFIEDREWARD 是一个面向多模态理解和生成任务的统一奖励模型,具备以下核心能力:
- 支持图像与视频的理解与生成任务;
- 实现跨模态任务的联合学习;
- 提供高质量的奖励信号,用于视觉模型训练中的偏好对齐;
- 支持成对排名(Pairwise Ranking)与逐点评分(Pointwise Scoring)两种模式。
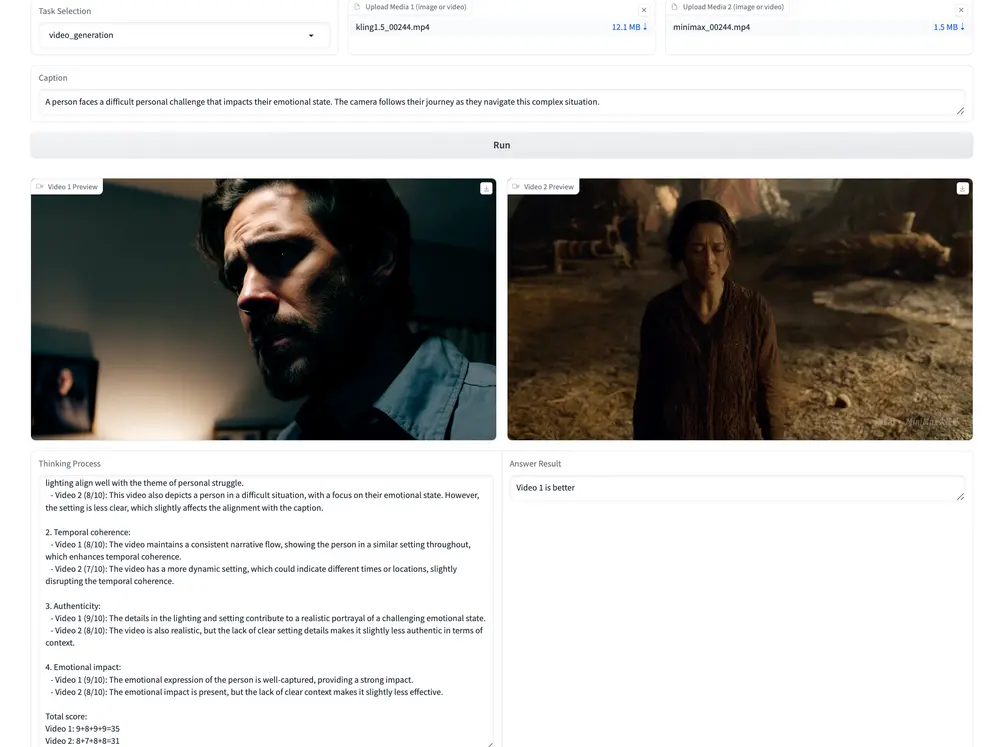
它不仅可用于图像生成质量评估,还可应用于视频理解效果评分,在多个视觉任务中展现出出色的泛化能力。
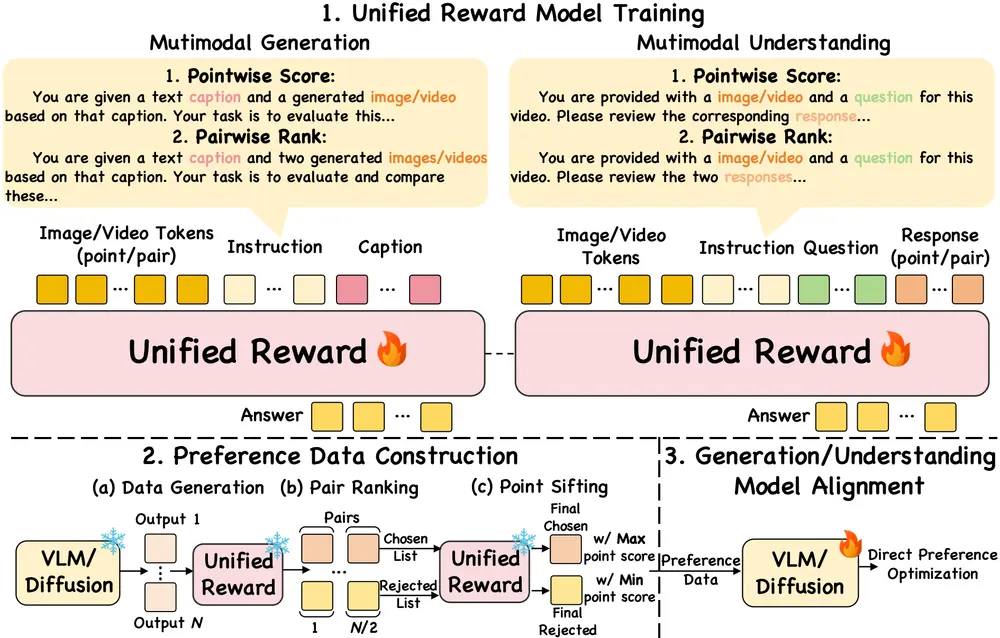
🧠 模型架构与工作原理
📊 数据集构建
研究团队整合了多个主流的人类偏好数据集,构建了一个大规模、统一的多模态偏好数据集,涵盖图像生成、图像理解、视频生成、视频理解等多个方向。
🔧 模型训练
基于上述数据集,研究人员使用预训练的视觉语言模型(VLM)进行微调,最终训练出 UNIFIEDREWARD 模型。
🔄 偏好数据构建与模型对齐
通过 UNIFIEDREWARD 对视觉模型输出进行筛选和排序,可以高效构建偏好数据,并利用 DPO 等算法进一步优化模型输出,使其更符合人类预期。
🧪 测试表现优异
在多个基准测试中,UNIFIEDREWARD 表现出色:
| 任务类型 | 基准测试 | 准确率 |
|---|---|---|
| 图像理解 | VLRewardBench | 66.5%(优于其他基线模型) |
| 视频理解 | ShareGPTVideo | 84.0%(显著优于仅针对视频理解训练的模型) |
| 图像生成 | GenAI-Bench | 超越 VisionReward 等现有方法 |
| 视频生成 | VideoGen-RewardBench | 超越 VideoReward 等现有方法 |
此外,在 Janus-Pro 的强化学习实验中,使用 UNIFIEDREWARD 进行评估的模型表现也明显优于 ImageReward 和原始 HPS 分数。
| 方法 | HPS | ImageReward | UnifiedReward |
|---|---|---|---|
| Janus-Pro + DPO | 77.3 | 77.7 | 80.0 |
| Janus-Pro + GRPO | 79.2 | 79.3 | 81.0 |
| Janus-Pro + Best-of-4 | 82.1 | 82.4 | 84.5 |
🔥 最新更新:UnifiedReward-qwen 系列上线!
团队近期推出了基于 Qwen2.5-VL-Instruct 构建的增强版模型:
UnifiedReward-qwen-[3b/7b/32b]
这一系列模型在图像与视频任务中表现出更强的能力,适用于更广泛的视觉生成评估任务。
同时,团队还发布了:
- vLLM 推理代码(位于
vllm_qwen目录) - SGLang 推理代码(位于
sglang_llava目录)
并推出首个支持链式推理(Chain-of-Thought, CoT)的多模态奖励模型:
UnifiedReward-Think-7b
📊 应用案例展示
腾讯 Hunyuan 团队已采用 UnifiedReward-qwen-7b,对多个文本到图像(T2I)模型进行评估,基于来自 400 个提示的数据集进行打分,结果如下:
| 模型 | 对齐性 | 一致性 | 风格 |
|---|---|---|---|
| Flux-pro-ultra | 3.6453 | 3.8193 | 3.4971 |
| Imagen-4.0 | 3.6792 | 3.8049 | 3.4756 |
| Recraft-v3 | 3.6611 | 3.8409 | 3.5158 |
| OpenAI-GPT-image-1 | 3.6890 | 3.8448 | 3.4960 |
| Imagen-3.0 | 3.6733 | 3.8027 | 3.4674 |
| Seedream-3.0 | 3.6927 | 3.8218 | 3.4887 |
🚀 主要功能与特点
✅ 功能亮点
- 多模态任务评估:支持图像与视频的理解与生成任务;
- 偏好对齐优化:通过奖励信号提升视觉模型输出质量;
- 联合学习机制:实现多种视觉任务之间的知识迁移与协同优化。
🌟 模型优势
- 统一性:首个能同时处理图像与视频任务的奖励模型;
- 适应性:通过联合学习增强模型对不同任务的泛化能力;
- 高效性:基于少量人工标注即可训练高质量奖励模型,减少标注成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











