阿里国际正式推出 Ovis2.5 —— Ovis2 的继任者,一款在原生分辨率视觉理解和多模态推理能力上实现显著跃升的开源多模态大语言模型(MLLM)。
- GitHub:https://github.com/AIDC-AI/Ovis
- 模型:https://huggingface.co/collections/AIDC-AI/ovis25-689ec1474633b2aab8809335
相比前代,Ovis2.5 不仅提升了对高分辨率图像、复杂图表和文档内容的理解精度,更引入了支持“反思式推理”的可选思考模式,在准确率与延迟之间提供灵活权衡,适用于从科研分析到工业文档处理的多种场景。
该系列包含两个主力模型:
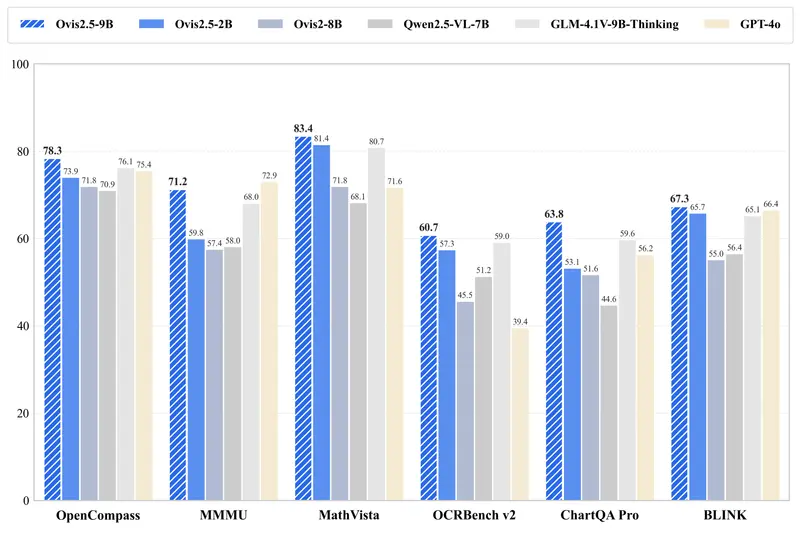
- Ovis2.5-9B:在 OpenCompass 多模态评测中平均得分 78.3,为参数低于 40B 的开源 MLLM 中当前最优表现;
- Ovis2.5-2B:轻量级版本,得分 73.9,延续“小模型,大性能”理念,适合边缘设备与资源受限环境。
核心升级:三大关键技术突破
1. 原生分辨率视觉感知(NaViT 编码器)
传统多模态模型通常将输入图像压缩至固定分辨率(如 384×384),再切分为小块进行处理。这一过程容易导致细节丢失和全局结构破坏,尤其影响图表、表格、工程图等视觉密集型内容的理解。
Ovis2.5 集成 原生分辨率视觉变换器(NaViT),支持:
- 直接处理图像原始分辨率(可变长宽比)
- 无需图像拼接或裁剪
- 保留细微纹理与整体布局
这意味着,无论是百万像素级的医学影像,还是包含复杂坐标轴的折线图,模型都能完整捕捉关键信息,显著提升 OCR 与语义解析的准确性。
2. 深度推理能力:从线性思维链到反思式推理
大多数多模态模型依赖线性思维链(Chain-of-Thought, CoT) 进行推理,即按顺序生成中间步骤。但在面对复杂问题时,这种方式缺乏纠错机制,易产生累积错误。
Ovis2.5 在训练中引入了反思性推理数据,包括:
- 自我检查(Self-Verification)
- 错误识别与修正(Revision)
- 多路径验证
在推理阶段,用户可选择启用“思考模式”——模型会主动验证中间结论、回溯逻辑漏洞,并尝试优化输出。虽然响应时间略有增加,但在数学推导、跨学科问答和复杂决策任务中,准确率显著提升。
此外,系统支持“思考预算”设置,允许用户控制推理深度,实现性能与延迟的精细平衡。
3. 图表与文档理解:行业级 OCR 与结构化解析
Ovis2.5 在以下任务中达到当前开源模型中的领先水平:
| 任务类型 | 数据集 | 表现 |
|---|---|---|
| 图表理解 | ChartQA Pro | 平均得分最高,优于同类模型 |
| STEM 推理 | MathVista | Ovis2.5-9B 得分 83.4,领先开源阵营 |
| 视觉定位 | RefCOCO 系列 | 平均准确率 90.1,精准定位图文对应区域 |
| 视频理解 | VideoMME / MVBench / MLVU | 多项指标领先 |
特别在表格识别、表单填写、流程图解析等文档理解任务中,Ovis2.5 展现出接近专业工具的结构化提取能力,为金融、教育、政务等领域的自动化处理提供了高性价比解决方案。
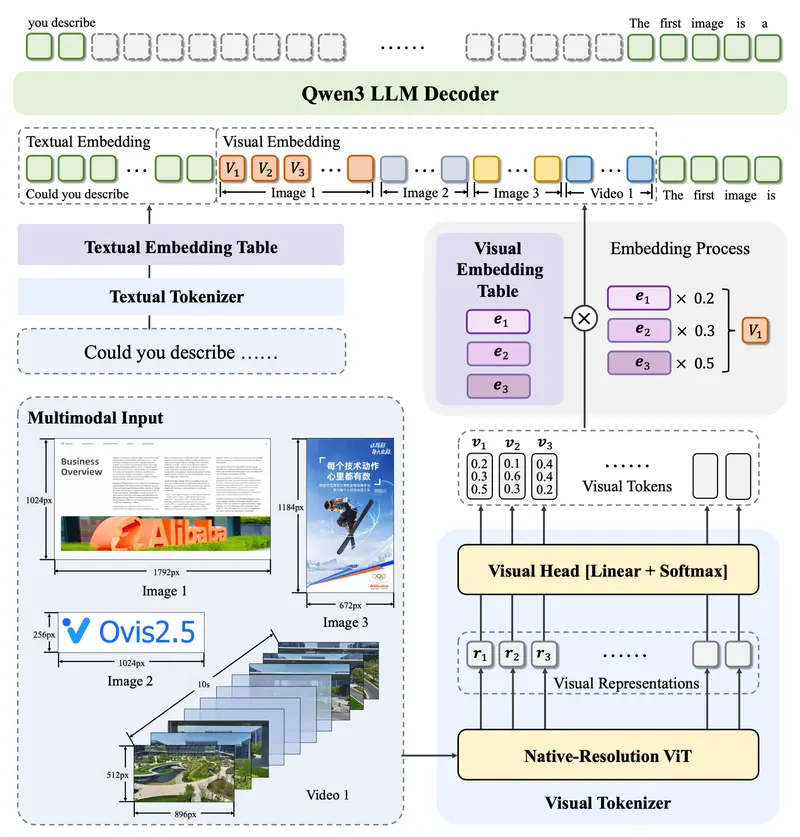
架构设计:高效、可扩展的多模态框架
Ovis2.5 延续模块化架构设计,核心由三部分组成:
- 视觉标记器(Visual Tokenizer, VT)
使用 NaViT 提取图像块特征,并映射到离散的“视觉词汇表”,生成带概率分布的视觉 token。 - 视觉嵌入表(Visual Embedding Table, VET)
类似文本嵌入表,存储每个视觉词汇的向量表示,通过加权求和生成最终视觉嵌入。 - 语言模型主干(LLM Backbone)
接收视觉与文本嵌入,执行跨模态融合与语言生成,支持长上下文与复杂指令理解。
该设计实现了视觉与语言模态的解耦建模,便于后续扩展与轻量化部署。
训练策略:从预训练到强化对齐
阶段一:预训练
- 视觉预训练:在大规模图像-文本对上训练 VT 与 VET;
- 多模态预训练:融合图文数据,建立初步跨模态对齐;
- 指令微调:使用高质量指令数据提升对话与任务理解能力。
阶段二:后训练优化
- 直接偏好优化(DPO):基于人类偏好数据优化输出质量;
- 基于验证的强化学习(RLVR):引入自动验证信号,引导模型自我修正,增强推理鲁棒性。
配合高效的数据打包策略(将多个短样本合并为长序列),训练吞吐量提升显著。
高效训练基础设施
为应对大规模训练挑战,Ovis2.5 采用混合并行框架:
- 数据并行:跨 GPU 分发批量数据
- 张量并行:拆分模型层内计算
- 上下文并行:分割长序列以降低显存占用
该架构有效控制了训练成本,使 9B 级模型可在合理资源下完成迭代。
实测表现:全面领先的多模态能力
在多个权威基准测试中,Ovis2.5 表现出色:
| 类别 | 测试项目 | Ovis2.5 表现 |
|---|---|---|
| 综合能力 | OpenCompass(平均分) | 9B: 78.3|2B: 73.9(同规模SOTA) |
| 数学推理 | MathVista | 83.4(显著优于其他开源模型) |
| 图表理解 | ChartQA Pro | 当前开源最佳 |
| 视觉定位 | RefCOCO / RefCOCO+ / RefCOCOg | 平均 90.1,精准图文对齐 |
| 视频理解 | VideoMME, MVBench, MLVU | 多项第一,支持长视频理解 |
轻量级 Ovis2.5-2B 虽仅 20 亿参数,但在多项任务中接近甚至超越部分 7B~13B 模型,验证了其高效设计。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











