NuMind 正式推出 NuMarkdown-8B-Thinking —— 据称是首个专为文档理解设计、具备显式推理能力的视觉语言模型(VLM)。该模型专注于将扫描文档或图像中的复杂版式内容,精准转换为结构清晰、语义完整的 Markdown 文件,尤其适用于构建高质量的检索增强生成(RAG)系统。
- GitHub:https://github.com/numindai/NuMarkdown
- 模型:https://huggingface.co/numind/NuMarkdown-8B-Thinking
- Demo:https://huggingface.co/spaces/numind/NuMarkdown-8b-Thinking
- API:https://nuextract.ai
与传统 OCR 模型不同,NuMarkdown-8B-Thinking 不仅“看图识字”,还能在输出前进行内部推理,理解文档的整体布局逻辑。
.webp)
核心机制:引入“思考令牌”实现布局推理
在生成最终 Markdown 结果之前,模型会先生成一组“思考令牌”(reasoning tokens),用于分析文档图像的结构特征,如段落顺序、标题层级、表格边界与跨页合并等复杂情况。
这种分阶段处理方式模拟了人类阅读文档时的思维过程:先理解结构,再组织表达。
- 动态推理深度:根据输入文档的复杂程度,思考令牌的数量可在最终输出长度的 20% 到 500% 之间自适应调整。
- 擅长处理难题:对非标准排版、多栏混合、跨页表格、嵌套单元格等传统 OCR 难以应对的场景表现尤为突出。
技术架构与训练方法
NuMarkdown-8B-Thinking 基于 Qwen 2.5-VL-7B 多模态架构进行深度微调,训练流程分为两个关键阶段:
- 监督微调(SFT)
使用合成生成的三元组数据:原始文档图像 → 推理轨迹 → 目标 Markdown,训练模型建立从视觉输入到结构化输出的映射能力。推理轨迹包含对布局结构的逐步分析过程。 - 强化学习优化(GRPO)
在困难样本上引入基于布局准确性的奖励函数,通过 GRPO(Group Relative Policy Optimization)进一步提升模型在复杂文档上的鲁棒性与一致性。
整个训练过程依赖高质量的合成数据集,确保推理路径可解释、输出结果可验证。
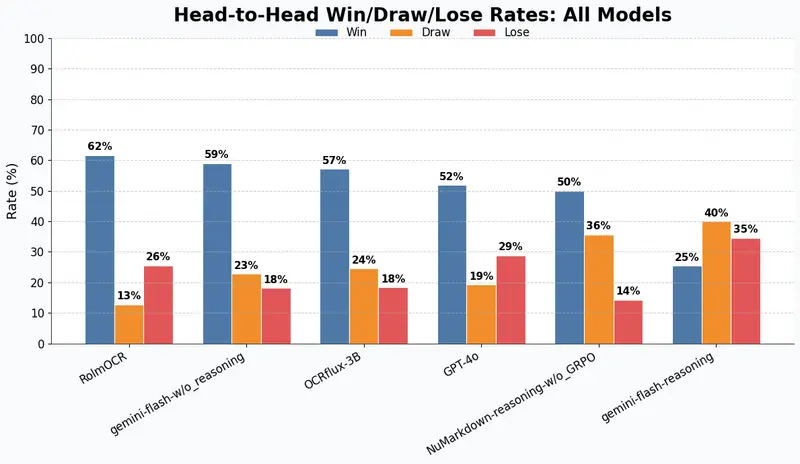
性能对比:超越通用模型,媲美闭源方案
在匿名用户投票评估平台(类似 LLM Arena)中,使用 TrueSkill-2 排名系统(约 500 次对比),NuMarkdown-8B-Thinking 获得如下排名:
| 排名 | 模型名称 | μ | σ | μ − 3σ |
|---|---|---|---|---|
| 🥇 1 | gemini-flash-reasoning | 26.75 | 0.80 | 24.35 |
| 🥈 2 | NuMarkdown-reasoning | 26.10 | 0.79 | 23.72 |
| 🥉 3 | NuMarkdown-w/o_grpo | 25.32 | 0.80 | 22.93 |
| 4 | OCRFlux-3B | 24.63 | 0.80 | 22.22 |
| 5 | gpt-4o | 24.48 | 0.80 | 22.08 |
| 6 | gemini-flash-w/o_reasoning | 24.11 | 0.79 | 21.74 |
| 7 | RolmoOCR | 23.53 | 0.82 | 21.07 |
注:μ 为评分均值,σ 为标准差,μ−3σ 表示保守估计下的最低可信得分。
结果显示,NuMarkdown-8B-Thinking 在复杂文档解析任务中显著优于 GPT-4o 和 OCRFlux 等主流方案,且与 Google 最新的推理优化版 Gemini 模型性能接近。
此外,在图像输入任务中的胜/平/负率统计也表明,启用 GRPO 强化学习后,模型在挑战性样本上的稳定性明显提升。
开源计划与未来方向
NuMind 团队计划推出一个专门针对文档到 Markdown 转换任务的公开评测平台 —— Markdown Arena,功能类似于现有的 LLM Arena,旨在为研究者和开发者提供统一、透明的评估基准。
该平台将支持:
- 多维度评估(结构保真度、语义准确性、表格还原度等)
- 匿名模型对战机制
- 可视化对比工具
此举有望推动文档智能领域的标准化发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...