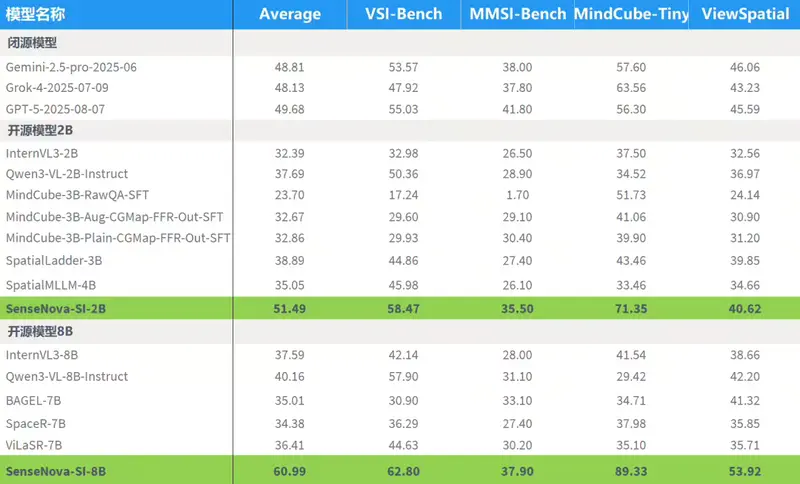
腾讯正式推出 混元Large-Vision —— 一款面向复杂任务的旗舰级多模态大模型。该模型在文档理解、数学推理、视频分析和三维空间感知等高难度场景中表现突出,同时具备卓越的多语言支持能力,在LMArena Vision等权威评测中跻身前列。
作为混元系列的最新成员,Large-Vision 不仅是一次性能升级,更是对“多模态理解”边界的系统性拓展。

核心定位:不只是“看懂图像”,而是“理解世界”
当前多模态模型普遍面临三大挑战:
- 输入受限:多数模型需将图像压缩至固定分辨率,损失细节
- 推理薄弱:在数学、逻辑、空间分析等复杂任务上依赖外部工具
- 多语言失衡:非英语语种理解能力明显弱于英语
混元Large-Vision 的目标是突破这些瓶颈,打造一个真正具备跨模态、跨语言、跨任务理解能力的通用视觉理解引擎。
模型概览
| 模块 | 规格 |
|---|---|
| 视觉编码器(Hunyuan ViT) | 1B 参数,支持原生分辨率输入 |
| 语言模型 | 389B 总参数,52B 激活参数(MoE 架构) |
| 训练数据 | 超 400B tokens 高质量多模态指令数据 |
| 训练框架 | 腾讯 Angel-PTM 大规模训练平台 |
在 LMArena Vision(去除风格控制赛道)评测中,混元Large-Vision 以 1233 分位列全球第六、国内模型第一,与 GPT-4.5、Claude-3.5 Sonnet 等国际顶尖模型处于同一梯队。
三大核心优势
1. 能力多样:专为复杂任务优化
混元Large-Vision 并非通用型“通才”,而是针对以下高价值场景进行了专项强化:
- 文档与图表理解:精准解析PDF、报表、流程图中的结构化信息
- 数学与科学推理:支持公式识别、几何题求解、物理场景推演
- 视频时序理解:捕捉动作序列、事件因果与长程依赖
- 三维空间分析:从单图或多视图推断物体空间关系
在 OpenCompass 多模态评测集 上,模型取得 79.5 的平均分,在视觉推理、OCR、视频问答等子项中均处于领先水平。

2. 输入灵活:支持任意分辨率图像与视频
传统多模态模型通常将输入图像缩放至固定尺寸(如 384×384),导致高分辨率图像中的关键细节丢失。
混元Large-Vision 采用 原生分辨率输入机制,其视觉编码器可直接处理:
- 超大尺寸图片(如扫描文档、设计图纸)
- 多视图拼接图像
- 变长视频序列
这一设计显著提升了在文档分析、医学影像、工程制图等专业场景下的实用性。
3. 多语言支持:平衡的全球化体验
模型在训练中注入了大量非英语多模态数据,并通过强化学习优化小语种推理能力,在 LMArena Vision 的多语言测试中表现优异。
它不仅能理解中文、英文,还对日文、韩文、西班牙语、法语、阿拉伯语等多种语言具备稳定支持,确保全球用户获得一致的交互体验。
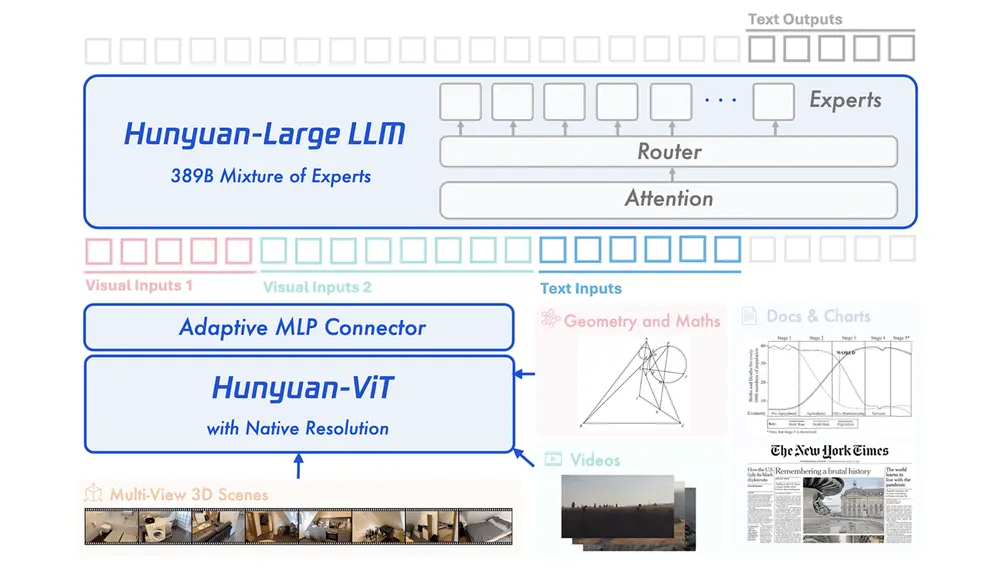
模型架构:三大模块协同工作
混元Large-Vision 由三个核心组件构成,形成高效的信息流动链条:
① 1B 参数混元ViT视觉编码器
专为多模态任务设计,支持原生分辨率输入,无需预裁剪或缩放。
先通过图文对比学习建立基础视觉感知能力,再结合小规模语言模型进行跨模态对齐训练,累计训练超过 1T tokens。
✅ 在内部视觉实体识别测试集(覆盖2000+类别)中,展现出更强的概念覆盖能力。
② 自适应下采样MLP连接器
由于原生分辨率输入导致视觉特征长度不一,传统连接器难以处理。
为此,团队设计了自适应下采样机制,动态压缩视觉特征,高效对接大语言模型,兼顾精度与计算效率。
③ 389B参数MoE语言模型
采用混合专家(Mixture-of-Experts)架构,激活参数仅52B,兼顾性能与推理成本。
具备强大的多语言理解和复杂推理能力,是整个系统的大脑。
关键训练技术
1. 高质量多模态指令数据合成管线
原始图文数据噪声大、图文相关性低。为此,团队构建了一套自动化数据清洗与增强流程:
- 利用预训练多模态模型重写低质描述
- 使用规则与模型联合过滤图文不一致样本
- 合成涵盖视觉识别、数学、科学、OCR等领域的指令数据
最终生成 超400B tokens 的高质量训练数据,大幅提升数据利用效率。
2. 拒绝采样微调(Rejection Sampling Fine-tuning)
用于提升复杂任务解决能力与多语言鲁棒性。
具体做法:
- 让模型生成多个回答路径
- 使用规则与判别模型筛选出逻辑正确、语言连贯的答案
- 构建高质量微调数据集
此方法显著改善了模型在小语种问题和复杂推理任务上的表现。
3. 由长到短思维链蒸馏
为了打造高效推理的“短链模型”,团队采用知识蒸馏策略:
- 使用内部更强的“长思维链模型”生成详细推理过程
- 将其压缩改写为简洁、精准的短链推理数据
- 用于训练混元Large-Vision
结果表明,该方法在保持推理准确性的同时,大幅缩短响应时间,更适合实际部署。
4. 多粒度负载均衡训练优化
由于原生分辨率输入导致不同图像的计算量差异巨大,在分布式训练中易出现GPU负载不均(即“气泡”现象)。
为此,团队在 Angel-PTM 框架中实现了多层级负载均衡:
- 数据加载层动态分配高负载样本
- 张量并行与数据并行层面进行任务重调度
实测显示,单GPU最大token处理量降低 18.8%,有效缩短训练周期,提升资源利用率。
实际应用表现
在 LMArena Vision 排行榜中:
| 模型 | 分数 | 排名 |
|---|---|---|
| GPT-4.5 | 1280 | 1 |
| Claude-3.5 Sonnet | 1250 | 3 |
| 混元Large-Vision | 1233 | 6(国内第1) |
在去除风格控制后,模型依然保持高分,说明其能力来自真实的理解而非模式匹配。
在 OpenCompass 多模态评测集:
- 平均得分:79.5
- 视觉推理:83.2
- 视频理解:76.8
- OCR与文档理解:81.1
在多个子任务中超越同类开源模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











