
英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM-3B 的目标是解决视觉-语言建模中的一个关键挑战:生成详细的、特定于区域的描述。
- 项目主页:https://describe-anything.github.io
- GitHub:https://github.com/NVlabs/describe-anything
- 模型:https://huggingface.co/collections/nvidia/describe-anything-680825bb8f5e41ff0785834c
- Demo:https://huggingface.co/spaces/nvidia/describe-anything-model-demo

背景与挑战
在视觉-语言建模中,生成全局字幕已经取得了显著进展,但在生成详细的、特定于区域的描述方面,现有模型仍存在不足。特别是在视频数据中,模型需要考虑时间动态,这使得问题更加复杂。主要障碍包括:
- 细粒度细节丢失:在视觉特征提取过程中,细粒度细节容易丢失。
- 标注数据不足:缺乏针对区域描述的足够标注数据集。
- 评估基准问题:现有的评估基准由于参考字幕不完整,可能会惩罚准确的输出。

DAM-3B:为局部描述量身定制的模型
DAM-3B 是一个专门用于生成细粒度局部字幕的多模态大型语言模型。它能够处理静态图像和动态视频输入,并生成上下文相关的描述性文本。DAM-3B 的核心架构组件和设计包括:
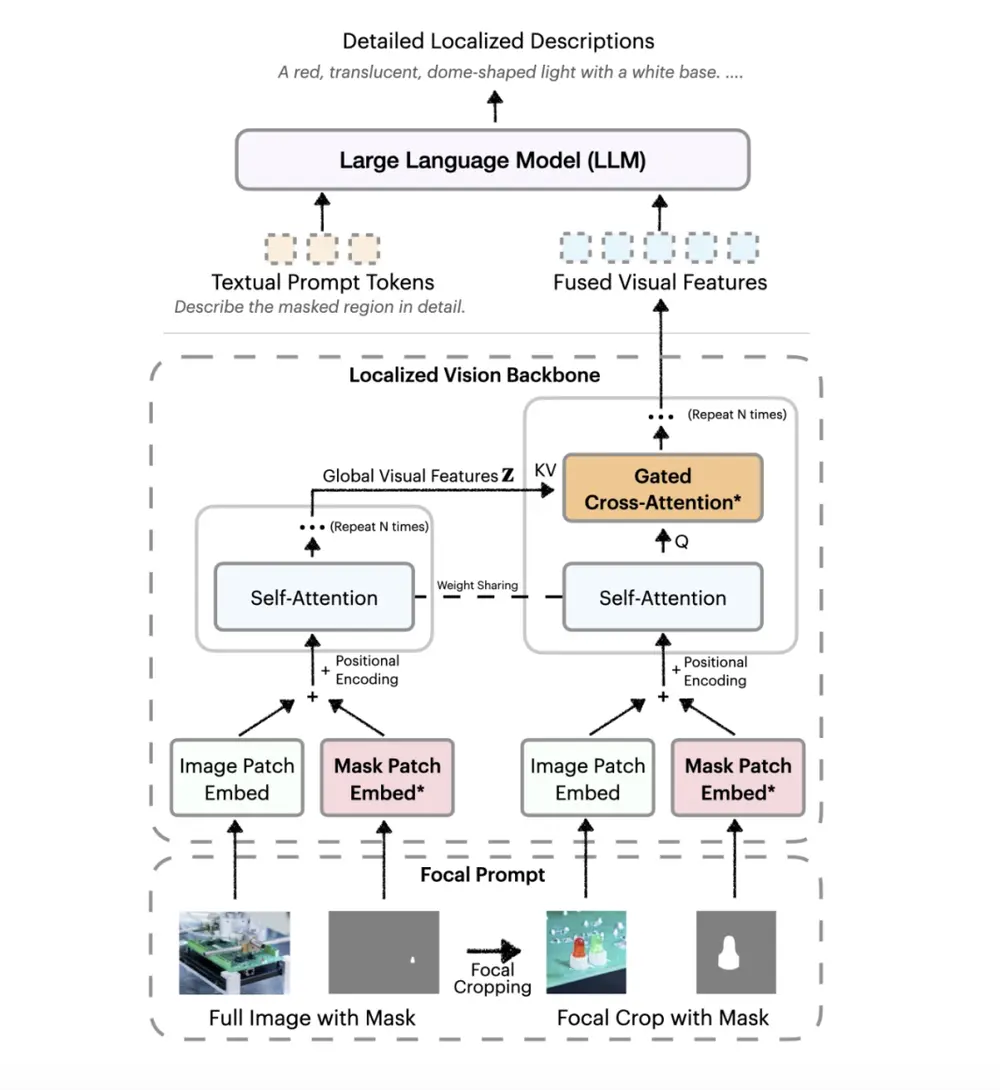
- 焦点提示 (Focal Prompt):将完整图像与目标区域的高分辨率裁剪融合在一起,保留区域细节和更广泛的上下文。
- 局部视觉骨干网络 (Localized Vision Backbone):嵌入图像和掩码输入,并应用交叉注意力来混合全局和焦点特征,然后将其传递给大型语言模型。这些机制在不增加 token 长度的情况下集成,从而保持了计算效率。
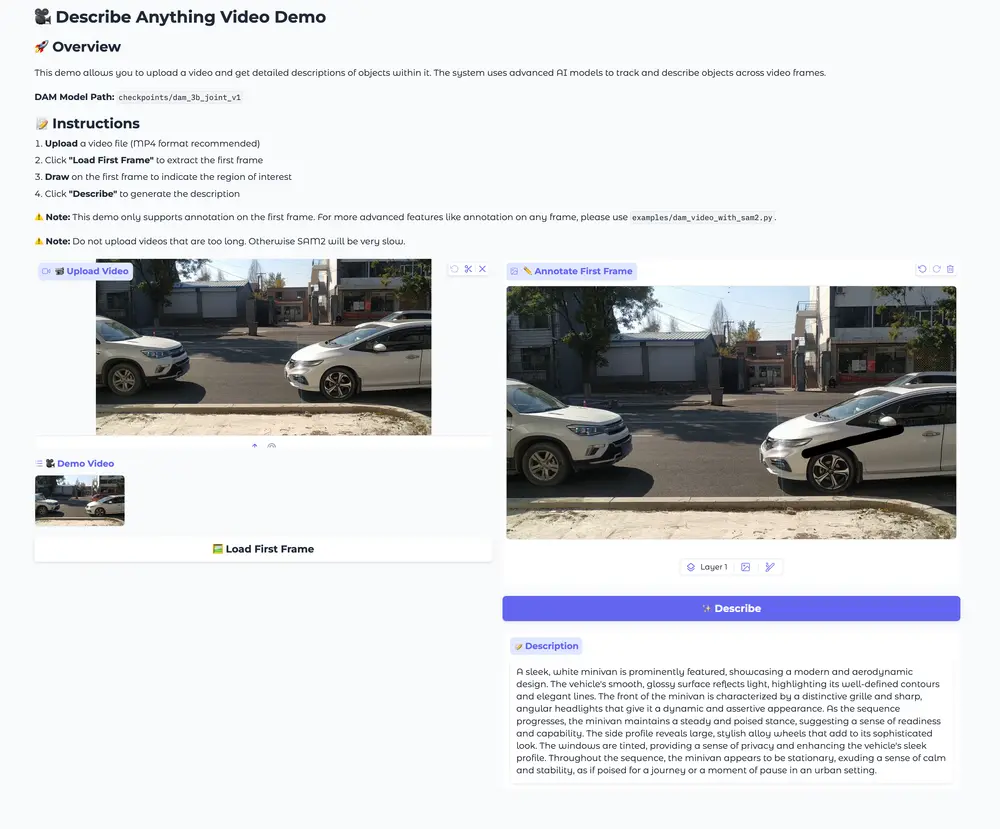
DAM-3B-Video 通过编码逐帧区域掩码并在时间上整合它们,将此架构扩展到时间序列。这使得模型能够为视频生成特定于区域的描述,即使在存在遮挡或运动的情况下也能保持准确性。
训练数据策略和评估基准
为了克服数据稀疏问题,研究团队开发了 DLC-SDP 流程——一种半监督数据生成策略。这个两阶段过程利用分割数据集和未标记的网络规模图像来整理一个包含 150 万个局部示例的训练语料库。区域描述使用自训练方法进行优化,生成高质量的字幕。
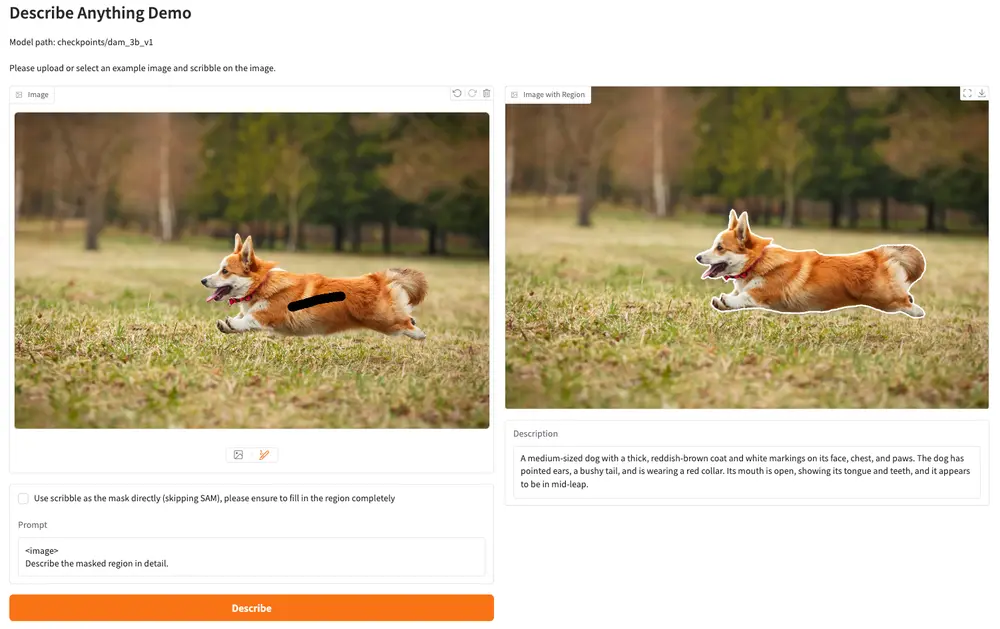
为了进行评估,研究团队引入了 DLC-Bench,该基准根据属性级别的正确性而不是与参考字幕的严格比较来评估描述质量。DAM-3B 在七个基准测试中取得了领先的性能,超越了 GPT-4o 和 VideoRefer 等基线模型。它在关键词级别 (LVIS, PACO)、短语级别 (Flickr30k Entities) 和多句局部字幕 (Ref-L4, HC-STVG) 上都表现出强大的结果。在 DLC-Bench 上,DAM-3B 的平均准确率达到 67.3%,在细节和精确度方面都优于其他模型。
应用场景与未来展望
DAM-3B 通过将上下文感知架构与可扩展的高质量数据管道相结合,解决了长期以来在特定区域字幕方面的局限性。该模型在以下领域具有广泛的适用性:
- 可访问性工具:帮助视障人士更好地理解图像和视频内容。
- 机器人技术:为机器人提供更详细的环境描述,增强其决策能力。
- 视频内容分析:自动生成视频的详细字幕,提高内容理解和分析效率。
通过此次发布,研究团队为未来的研究提供了一个强大且可复现的基准,并为下一代多模态 AI 系统设定了一个精细的技术方向。DAM-3B 不仅展示了研究团队在多模态 AI 领域的创新,也为开发者和研究人员提供了一个强大的工具,推动视觉-语言建模的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











