
字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成复杂的视频编辑任务。
例如,在视频编辑中,用户常常需要从长视频中找到特定的片段,如“找到视频中出现马的场景”或“找到视频中人物在自行车上睡着的片段”。Vidi 能够通过自然语言查询(如“马”或“在自行车上睡着”)快速定位这些片段,大大简化了视频编辑的工作流程。
主要功能
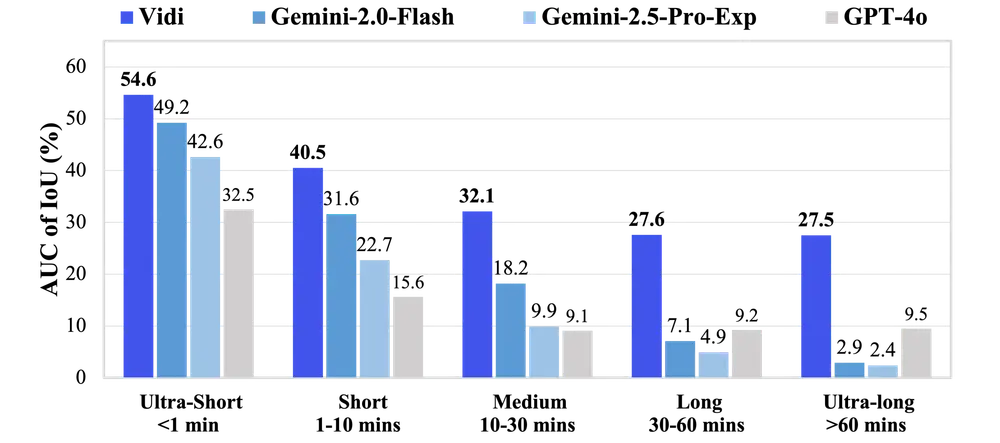
- 时间检索(Temporal Retrieval):Vidi 能够根据自然语言查询,从长视频中检索出与查询相关的具体时间范围。
- 多模态处理:Vidi 支持处理视觉(视频帧)、音频和文本三种模态,能够更全面地理解和处理视频内容。
- 长视频处理:Vidi 能够处理长达数小时的视频,显著超越了现有数据集的时长限制(通常为几分钟)。
- 高精度定位:Vidi 能够以秒级精度定位视频中的相关片段,支持高精度的时间检索。
主要特点
- 多模态对齐:Vidi 通过视觉、音频和文本的对齐,实现了多模态数据的深度融合,能够更好地理解视频内容。
- 分解注意力机制(Decomposed Attention):Vidi 采用了分解注意力机制,将计算复杂度从 降低到 ,使得模型能够高效处理长视频。
- 大规模训练数据:Vidi 使用了大规模的合成数据和真实视频数据进行训练,确保模型在不同场景下的鲁棒性和准确性。
- 多样化查询支持:Vidi 支持多种查询格式(关键词、短语、句子)和模态(视觉、音频、视觉+音频),能够适应不同的用户需求。
工作原理
- 输入处理:
- 视频帧以 1 帧/秒的速率采样,音频以 16,000 Hz 的采样率处理。
- 视频帧和音频片段分别通过预训练的视觉编码器(如 SigLIP)和音频编码器(如 Whisper)转换为多模态嵌入向量。
- 多模态对齐:
- 使用分解注意力机制(Decomposed Attention)将视觉、音频和文本嵌入向量融合。
- 通过多模态适配器(Adapters)将不同模态的嵌入向量映射到预训练语言模型(LLM)的输入空间。
- 训练阶段:
- 适配器训练:训练视觉和音频适配器,使其能够将多模态数据对齐到文本描述。
- 合成数据训练:使用合成视频数据进行训练,帮助模型学习多模态到时间的对齐。
- 真实视频训练:使用大规模真实视频数据进行微调,进一步提升模型在实际场景中的表现。
- 应用后训练:
- 使用任务特定的数据(如时间检索任务)对模型进行微调,增强模型在实际应用中的表现。
应用场景
- 视频编辑:
- 时间检索:用户可以通过自然语言查询快速找到视频中的特定片段,如“找到视频中人物在自行车上睡着的场景”。
- 智能剪辑:Vidi 可以自动识别视频中的关键事件,并生成相应的剪辑建议。
- 视频理解:
- 视频问答(VideoQA):用户可以通过自然语言提问,Vidi 提供详细的视频内容解释。
- 内容标注:Vidi 可以自动生成视频内容的详细标注,帮助用户更好地理解和管理视频资源。
- 创意视频制作:
- 生成视频封面和缩略图:Vidi 可以根据视频内容生成吸引人的封面和缩略图。
- 风格化场景生成:Vidi 可以根据用户需求生成特定风格的视频场景,如复古风格或科幻风格。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











