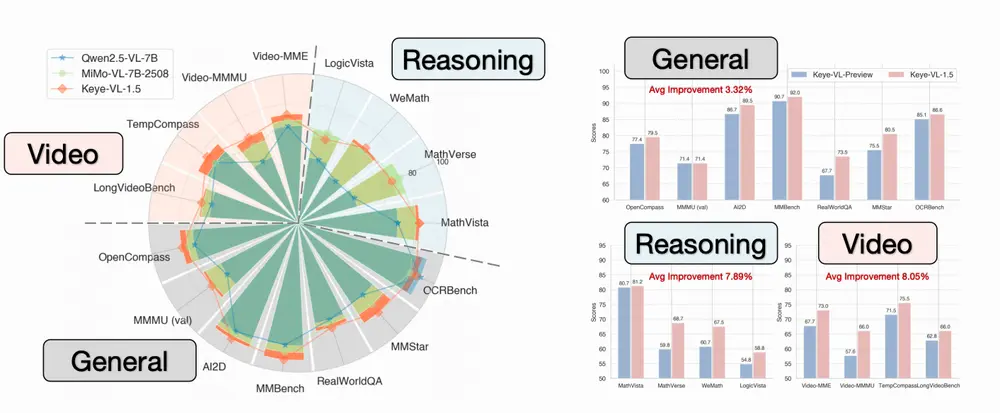
快手 Keye 团队发布Keye-VL-1.5 :支持 128K 上下文的视频理解大模型在多模态大模型的竞争中,视频理解正成为下一个关键战场。相比图像,视频包含更丰富的时空信息——动作的起止、事件的因果、场景的演变。要让AI真正“看懂”一段视频,不仅需要识别画面内容,还要理解时间逻辑与行...多模态模型# Keye-VL-1.5# 快手# 视频理解大模型7个月前0770
基于 Qwen2-VL-7B 开发的实时视频理解大模型LiveCC:快速分析视频内容,并同步生成自然流畅的语音或文字解说新加坡国立大学和字节跳动的研究人员推出基于 Qwen2-VL-7B 开发的实时视频理解大模型LiveCC,能够像专业解说员一样快速分析视频内容,并同步生成自然流畅的语音或文字解说。特别适合需要即时反馈...多模态模型# LiveCC# Qwen2-VL-7B# 视频理解大模型11个月前03900