在多模态大模型的竞争中,视频理解正成为下一个关键战场。相比图像,视频包含更丰富的时空信息——动作的起止、事件的因果、场景的演变。要让AI真正“看懂”一段视频,不仅需要识别画面内容,还要理解时间逻辑与行为动机。
近日,快手 Keye 团队发布了其最新版本多模态大语言模型 Keye-VL-1.5。相比前代,它在视频理解、长上下文处理和复杂推理能力上实现显著提升,标志着国产多模态模型在视频场景中的进一步突破。
为什么视频理解如此困难?
传统视觉模型多以图像为输入,而视频带来了三大挑战:
- 信息量大:一分钟视频可能等效于上百张图像
- 时序依赖强:动作的发生顺序决定语义(例如“拿起杯子”和“倒水”必须按序理解)
- 关键帧稀疏:重要内容往往集中在少数帧中,其余为冗余静态画面
Keye-VL-1.5 的设计,正是围绕这些挑战展开。
核心升级:从编码策略到训练方法的系统性优化
1. Slow-Fast 视频编码:动态分配计算资源
Keye-VL-1.5 引入 Slow-Fast 编码策略,灵感来源于经典视频理解架构,但针对大模型场景做了适配。
- Slow 路径:处理关键帧,使用高分辨率捕捉空间细节(如人物表情、物体形态)
- Fast 路径:处理静态或变化较小的帧,降低分辨率与采样率,节省计算开销
通过分析帧间相似性动态调整路径分配,模型在保证精度的同时,显著提升处理长视频的效率。
2. 四阶段渐进式预训练:支持 128K 上下文长度
长上下文是理解复杂视频的基础。Keye-VL-1.5 采用四阶段渐进预训练策略,逐步扩展上下文长度:
- 8K tokens
- 32K tokens
- 64K tokens
- 最终达到 128K tokens
这种分阶段训练方式,使模型能稳定学习长距离依赖关系,适用于长时间对话、连续剧情理解等任务。
3. LongCoT Cold-Start 数据管道 + 强化学习优化推理
为了提升模型的逻辑推理能力,团队构建了 LongCoT(Long Chain-of-Thought)Cold-Start 数据管道,生成包含多步推理的高质量训练样本。
在此基础上,引入迭代式强化学习(RL)训练策略:
- 通过提示引导模型生成推理链
- 利用奖励模型评估输出质量
- 结合人类偏好数据进行对齐优化
这一组合显著提升了模型在视觉问答、行为归因等任务中的响应质量与逻辑严谨性。
4. 超大规模多模态训练数据
模型在超过 1 万亿 tokens 的多样化数据集上训练,涵盖:
- 图像-文本对
- 视频-字幕序列
- 用户行为日志
- 人工标注指令数据
丰富的数据来源保障了模型在真实场景下的泛化能力。
能做什么?三大核心能力
| 能力 | 典型应用 |
|---|---|
| ✅ 视频内容理解 | 自动识别物体出现时间、动作发生顺序、行为动机分析 |
| ✅ 视觉问答(VQA) | 回答“为什么这个人突然跑起来?”“这个操作有什么风险?”等因果类问题 |
| ✅ 长视频摘要生成 | 基于 128K 上下文,生成连贯、有逻辑的视频描述或章节摘要 |
此外,Keye-VL-1.5 也支持通用多模态任务,如图像描述、图文检索、跨模态生成等,具备较强的通用性。
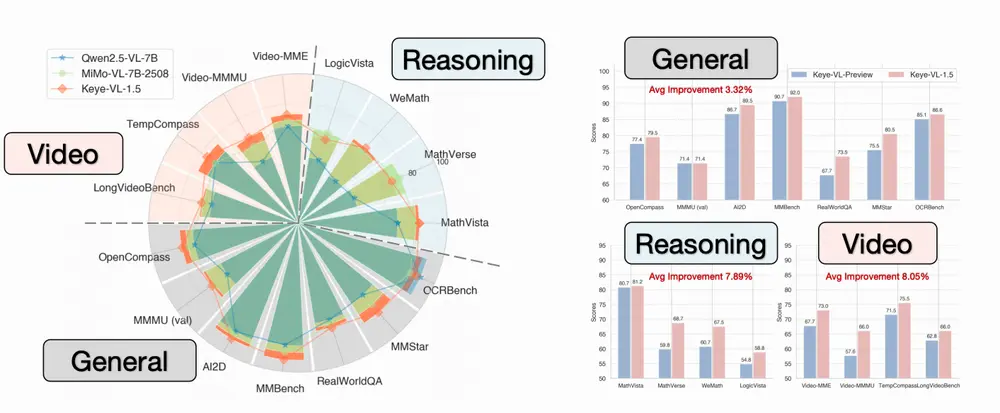
实测表现:全面领先
在多个公开基准和内部测试中,Keye-VL-1.5 表现优异:
- 在视频理解任务中,平均性能显著优于现有主流模型
- 在需要时间推理的任务上(如事件排序、因果推断),准确率提升明显
- 多模态任务综合能力与国际先进模型相当,部分指标领先
尤其在长视频结构化理解和复杂场景推理方面,展现出更强的鲁棒性与连贯性。
技术意义与未来展望
Keye-VL-1.5 的发布,不仅是参数或指标的提升,更体现了对“视频作为时序媒介”这一本质的深入理解。
它的几个关键设计——Slow-Fast 编码、渐进式长上下文训练、LongCoT 数据构建——为后续多模态模型提供了可复用的技术路径。
对于内容平台而言,这类模型可用于:
- 自动生成视频字幕与章节标签
- 提升推荐系统的语义理解能力
- 支持创作者进行智能剪辑与内容分析
而对于通用 AI 系统,它意味着机器正逐步具备“看懂故事”的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











