普林斯顿大学、北京大学、清华大学和字节跳动的研究人员推出新型多模态扩散基础模型MMaDA系列,该模型通过统一的扩散架构和训练策略,在多种领域(如文本推理、多模态理解和文本到图像生成)中实现卓越性能。
- GitHub:https://github.com/Gen-Verse/MMaDA
- 模型:https://huggingface.co/Gen-Verse/MMaDA-8B-Base
- Demo:https://huggingface.co/spaces/Gen-Verse/MMaDA
MMaDA 通过以下三大创新脱颖而出:
- MMaDA 采用统一的扩散架构,具备共享的概率公式和模态无关的设计,无需模态特定的组件。
- MMaDA 引入了混合长链思维(CoT)微调策略,跨模态整理出统一的 CoT 格式。
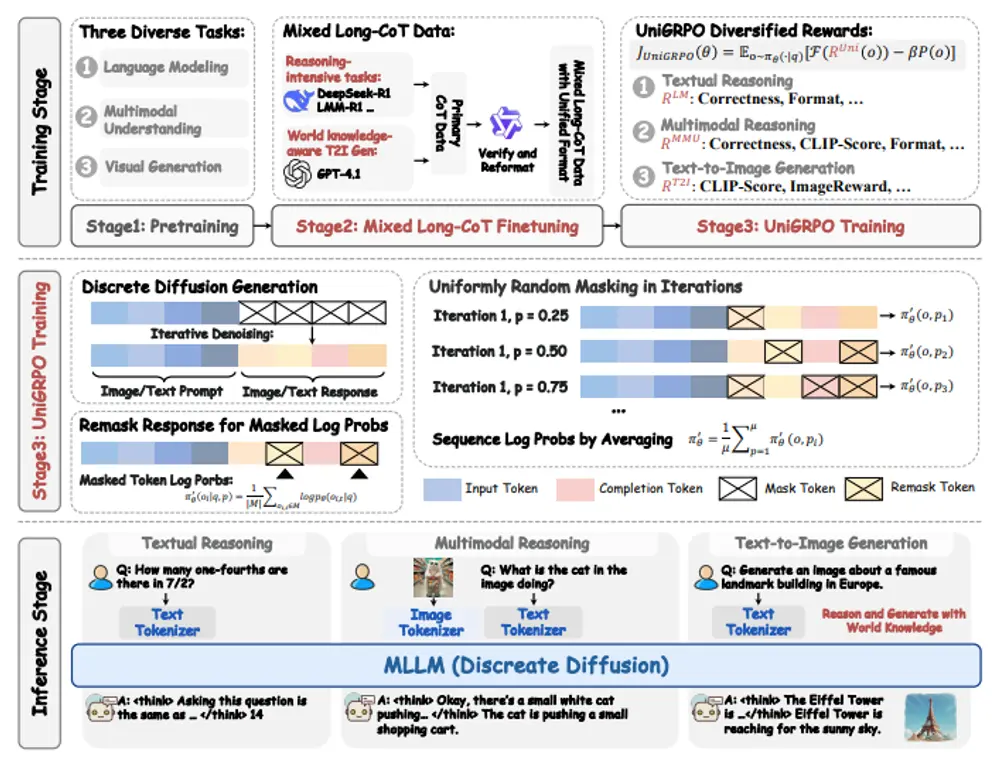
- MMaDA 采用了一种统一的基于策略梯度的强化学习算法,称为 UniGRPO,专为扩散基础模型量身定制。利用多样化的奖励建模,UniGRPO 统一了推理和生成任务的后训练,确保性能的持续提升。
MMaDA 系列概览
MMaDA 包括一系列反映不同训练阶段的检查点:
- MMaDA-8B-Base:完成预训练和指令微调后。具备基本的文本生成、图像生成、图像描述和思维能力。
- MMaDA-8B-MixCoT(即将推出):完成混合长链思维(CoT)微调后。能够进行复杂的文本、多模态和图像生成推理。将于两周后发布。
- MMaDA-8B-Max(即将推出):完成 UniGRPO 强化学习后。擅长复杂推理和出色的视觉生成。将于一个月后发布。
主要功能
MMaDA的主要功能包括:
- 文本推理:能够解决复杂的数学问题和逻辑推理任务,例如计算数学表达式的值、解决几何问题等。

- 多模态理解:可以理解图像内容并回答与图像相关的问题,例如描述图像中的场景、识别物体等。
- 文本到图像生成:根据文本描述生成高质量的图像,例如生成特定动物、地标建筑等的图像。
主要特点
- 统一扩散架构:MMaDA采用统一的扩散架构,消除了模态特定组件的需求,能够无缝处理不同类型的数据(如文本和图像)。
- 混合长链推理(CoT)微调:通过统一的CoT格式对模型进行微调,使模型在推理任务中表现出色。
- 统一强化学习(UniGRPO):提出了一种基于策略梯度的强化学习算法,专门针对扩散基础模型进行优化,提升模型在复杂任务中的性能。
工作原理
MMaDA的工作原理基于以下几个关键步骤:
- 数据预处理:对文本和图像数据进行统一的离散标记化处理,将图像转换为离散的语义标记序列。
- 预训练:采用统一的扩散目标对模型进行预训练,使模型能够预测被掩盖的标记。
- 混合长链推理微调:通过统一的CoT格式对模型进行微调,使模型在推理任务中表现出色。
- 统一强化学习:使用UniGRPO算法对模型进行强化学习,通过多样化的奖励建模提升模型的性能。
测试结果
在多种任务上的测试结果表明,MMaDA具有强大的泛化能力和优越的性能:
- 文本推理:在GSM8K等数学推理基准测试中,MMaDA的性能超过了LLaMA-3-8B和Qwen2-7B等强大基线模型。
- 多模态理解:在POPE、MME、Flickr30k等多模态理解基准测试中,MMaDA的性能与专门的多模态理解模型相当,甚至在某些任务上表现更好。
- 文本到图像生成:在CLIP Score和ImageReward等图像生成基准测试中,MMaDA的性能超过了SDXL和Janus等生成专用模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...