在多模态大模型(MLLM)快速发展的今天,一个核心问题日益凸显:预训练视觉编码器的训练方式是否真的适配下游任务?
传统方法依赖图像-文本对比学习(如 CLIP),但这类模型在接入 LLM 进行微调时,常面临“预训练与微调目标不一致”的问题——即所谓的“目标错配”(objective mismatch)。
- 项目主页:https://ucsc-vlaa.github.io/OpenVision2
- GitHub:https://github.com/UCSC-VLAA/OpenVision
- 模型:https://huggingface.co/collections/UCSC-VLAA/openvision-2-68ab5934fe21f3fc463077da
为解决这一瓶颈,来自加州大学圣克鲁兹分校、苹果公司与加州大学伯克利分校的研究团队推出了 OpenVision 2 —— 一个全新设计的生成式预训练视觉编码器家族。它不再追求复杂的多目标训练,而是通过简化架构、重构损失函数,实现更高效率与更强实用性。
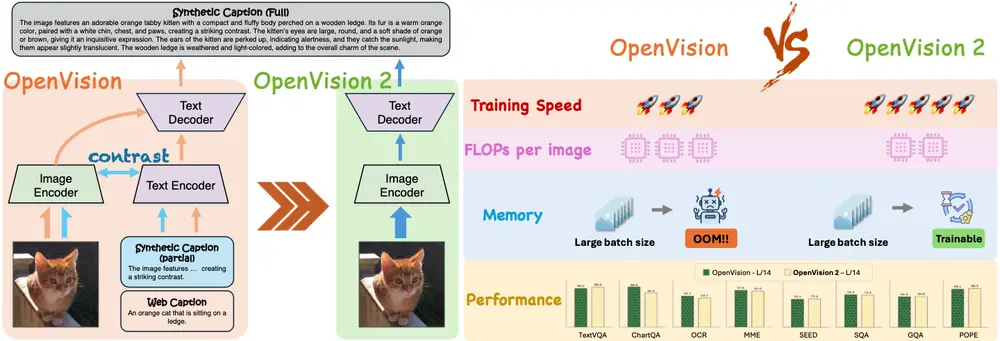
背景:从 OpenVision 到 OpenVision 2
OpenVision 是一个完全开源的视觉编码器系列,基于公开数据与代码,提供从 5.9M 到 632.1M 参数的多种规模模型,支持多模态基础模型的构建。
然而,其原始设计仍沿用典型的对比学习范式:
- 图像编码器 + 文本编码器
- 使用对比损失对齐图文表示
这种结构在接入 LLaVA、MiniGPT-4 等主流 MLLM 架构时,需额外引入适配模块,造成训练冗余与性能损耗。
OpenVision 2 的核心理念是:让预训练更贴近实际使用方式。
核心改进:三大设计变革
1. 仅保留生成式训练:移除文本编码器与对比损失
OpenVision 2 彻底抛弃了传统的双编码器结构和对比学习目标。
取而代之的是:
- ViT 图像编码器(保留)
- 仅解码器文本模型(如 LLM 的 decoder)
- 仅使用标题生成损失(captioning loss)
✅ 模型不再学习“图像和文本是否匹配”,而是学习“看到这张图应该说什么”。
这一改变使预训练流程与现代 MLLM 的微调阶段高度一致,显著减少了目标错配问题。
2. 训练-推理对齐:预训练即“推理”
传统 CLIP 式模型在推理时需重新拼接图像特征与 LLM,而 OpenVision 2 的训练方式本身就模拟了这一过程:
- 输入图像 → 图像编码器提取 token → 送入文本解码器 → 生成描述
- 整个流程与 LLaVA 等模型的推理路径完全一致
💡 这种“训练即部署”的设计理念,提升了模型迁移效率与泛化能力。
3. 大规模效率优化:双管齐下
为了支持更大规模模型的训练,OpenVision 2 引入两项关键技术:
✅ CLIPA 两阶段课程训练
- 低分辨率预训练:先在较低分辨率(如 224×224)上快速完成初步学习
- 短周期高分辨率微调:再切换至高分辨率(如 336×336)进行少量步数的精细调整
显著缩短训练时间,同时保持高分辨率性能。
✅ 视觉令牌随机掩码(Random Token Masking)
- 在输入解码器前,随机掩码约 65%–75% 的视觉 token
- 仅保留 25%–35% 的关键 token 参与解码
✅ 优势:
- 大幅降低解码器计算负担
- 鼓励模型聚焦于最具信息量的区域
- 提升训练吞吐量,节省显存
数据支撑:ReCap-DataComp-1B v2
高质量监督信号是生成式训练的关键。OpenVision 2 使用 ReCap-DataComp-1B v2 数据集进行训练,其特点包括:
- 基于网页 alt-text 构建,覆盖广泛场景
- 使用 LLaMA-3 驱动的重写模型生成更丰富、语法更自然的描述
- 采用 加权 top-k 采样 筛选高质量样本,减少噪声
这一数据策略确保了生成目标的多样性与可靠性,避免模型陷入简单重复或语义偏差。
📊 实验结果:效率与性能兼得
在多个标准多模态基准上,OpenVision 2 表现出色,且训练成本大幅下降。
1. 性能表现(vs 原版 OpenVision)
| 任务 | 结果 |
|---|---|
| TextVQA | 相近或略优 |
| ChartQA | 更强,尤其在图表理解上 |
| OCR-Bench | 显著提升,得益于更丰富的文本生成监督 |
尽管架构简化,但性能未降反升,验证了生成式训练的有效性。
2. 训练效率提升
| 模型 | 原始训练时间 | OpenVision 2 | 缩减比例 |
|---|---|---|---|
| ViT-L/14 | 83 小时 | 57 小时 | ↓ 31% |
| SoViT-400M/14 | 241 小时 | 121 小时 | ↓ 50% |
| 显存占用 |
|---|
| ViT-L/14:24.5GB → 13.8GB(↓ 44%) |
| SoViT-400M/14:27.4GB → 14.5GB(↓ 47%) |
⚡ 效率提升使得训练超过十亿参数的视觉编码器成为可能,远超原版 OpenVision 的能力边界。
✅ 方法特点总结
| 特性 | 说明 |
|---|---|
| 生成式预训练 | 仅用标题损失,贴近真实 MLLM 使用方式 |
| 轻量架构 | 移除文本编码器,降低复杂度 |
| 训练-推理对齐 | 减少目标错配,提升迁移效率 |
| 高效训练 | 掩码 token + 两阶段课程,显著节省资源 |
| 可扩展性强 | 支持超大规模模型训练 |
| 完全开放 | 数据、代码、模型均公开,推动社区发展 |
应用场景
| 场景 | 价值 |
|---|---|
| 多模态基础模型构建 | 可作为 LLaVA、CogVLM 等系统的默认视觉编码器 |
| 高效模型研发 | 降低训练门槛,适合学术与中小团队复现 |
| 长尾任务适应 | 生成式训练更易捕捉细粒度语义(如图表、文字识别) |
| 边缘部署探索 | 显存与计算优化为轻量化部署提供可能 |
研究意义
OpenVision 2 的最大贡献,不在于性能突破,而在于提出了一种新的训练范式:
与其堆叠复杂的多目标训练,不如回归本质:让预训练过程尽可能接近真实使用场景。
它证明了:
- 对比学习并非唯一路径
- 生成式监督足以学习强大的视觉表示
- 效率与性能可以兼得
这对未来多模态系统的设计具有深远启发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











