南洋理工大学和腾讯的研究人员推出新型图像生成模型EMMA,它基于最先进的文本到图像(T2I)扩散模型ELLA,能够接受多模态提示(multi-modal prompts),并生成高质量的图像。简单来说,EMMA模型可以同时处理文本、图像、视频等多种形式的输入,并根据这些输入生成相应的图像。还提到了EMMA的一些限制,比如目前只能处理英文提示,未来的工作将尝试实现支持多语言提示的扩散模型。
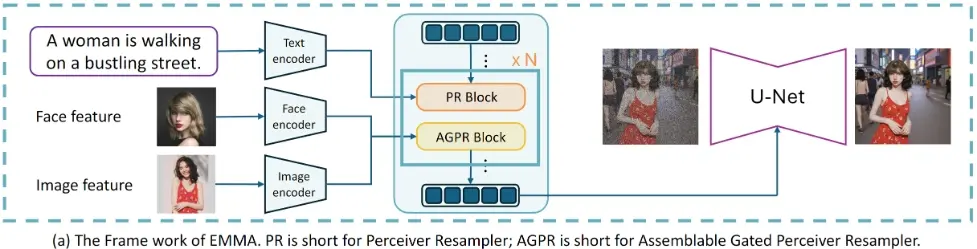
EMMA通过创新的多模态特征连接器设计,无缝整合额外模态与文本,利用特殊的注意力机制高效融合文本与补充模态信息来指导图像生成。研究人员通过冻结原始T2I扩散模型中的所有参数并仅调整一些附加层,揭示了一个有趣的发现:预训练的T2I扩散模型实际上能够隐式地接受多模态提示。这一有趣的特性便于EMMA轻松适应不同的现有框架,使其成为生成个性化和上下文感知图像乃至视频的灵活而有效的工具。此外,开发人员介绍了一种策略,通过组装学习到的EMMA模块来同时基于多种模态条件生成图像,无需使用混合多模态提示进行额外的训练。广泛的实验验证了EMMA在保持生成图像的高保真度和细节方面的有效性,展现了其作为高级多模态条件图像生成任务强大解决方案的潜力。

例如,你想要生成一张穿着绿色连衣裙的女性在繁忙城市街道上行走的图片。使用EMMA,你可以将文本描述(“一个穿着绿色连衣裙的女性在繁忙的城市街道上行走”)和其他模态的提示(如一张绿色连衣裙的图片)结合起来,生成一张符合描述的个性化图像。
主要功能:
- 接受并融合多种模态的提示来生成图像。
- 保持对生成结果的强烈文本控制。
主要特点:
- 多模态输入:能够处理文本、图像、视频等多种输入形式。
- 无需额外训练:通过冻结原始文本到图像扩散模型的所有参数,并只调整一些额外的层,EMMA能够适应不同的现有框架。
- 模块化设计:可以根据不同条件组装模型,简化训练过程,提高模型适应新任务的效率。
工作原理:
EMMA模型基于最新的文本到图像扩散模型ELLA构建。它通过创新的多模态特征连接器(Multi-modal Feature Connector)设计,使用特殊的注意力机制有效地整合文本和补充模态信息。EMMA模型通过在原始的文本到图像扩散模型中插入额外的模块,如Assemblable Gated Perceiver Resampler(AGPR),来实现对其他模态信息的融合。
具体应用场景:
- 个性化图像生成:根据用户的文本描述和其他模态输入生成个性化的图像。
- 艺术创作:艺术家可以使用EMMA将他们的概念和风格转化为视觉图像。
- 视频生成:通过结合文本和视频模态的提示,EMMA可以用于生成视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











