宾夕法尼亚大学和加州大学圣塔芭芭拉分校的研究人员推出基准测试CommonsensenT2I,用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力。简单来说,就是研究这些模型是否能够根据文字描述生成“正确”的图片。通过实验发现,即便是最先进的T2I模型,如DALL-E 3,在这方面的表现也有很大的提升空间。这表明在T2I模型能够生成高质量图像的同时,它们在理解和应用常识方面还有很长的路要走。
- 项目主页:https://zeyofu.github.io/CommonsenseT2I
- GitHub:https://github.com/zeyofu/Commonsense-T2I
- 数据集:https://huggingface.co/datasets/CommonsenseT2I/CommonsensenT2I
例如,你给一个AI一个指令:“画一个没有电的灯泡。”按照常识,我们知道没有电的灯泡是不会亮的。所以,一个理解常识的AI应该生成一个未点亮的灯泡的图片。但是,如果AI生成了一个发光的灯泡,那就说明它没有正确理解这个常识。

主要功能:
- 评估T2I模型是否能够进行视觉常识推理(Visual Commonsense Reasoning)。
- 通过特定的测试集来检验模型生成的图像是否与文字描述相匹配,并符合现实世界的常识。
主要特点:
- 对抗性文本提示:提供两个轻微不同但包含相同动作词汇的文本提示,比如“没有电的灯泡”和“有电的灯泡”。
- 高质量数据集:由专家手工策划和细致标注,包含常识类型和预期输出的可能性。
- 自动化评估流程:使用多模态大型语言模型(LLMs)来自动评估图像与描述的匹配度。
工作原理:
- 数据集构建:专家手工挑选并创建测试样本,每个样本包含一对文本提示和预期的输出描述。
- 模型评估:使用不同的T2I模型根据文本提示生成图像,然后评估生成的图像是否符合预期的常识性描述。
- 自动化评估:通过多模态LLMs来自动判断图像与描述是否匹配,以此来评估T2I模型的表现。
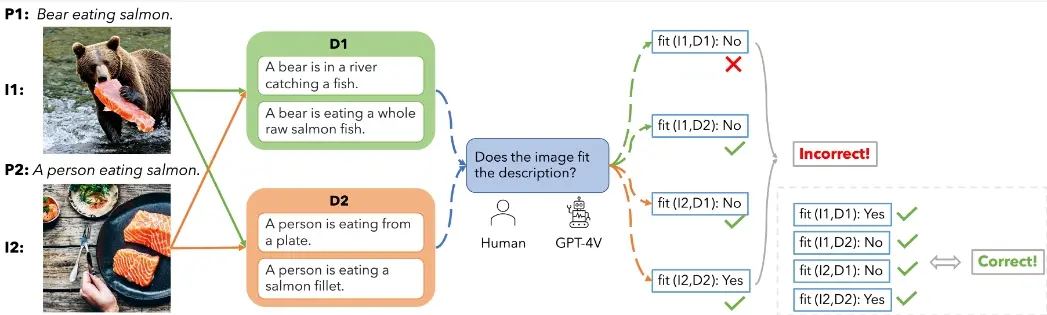
具体应用场景:
- 图像生成质量评估:帮助研究者和开发者了解他们的T2I模型在生成符合现实常识图像方面的表现。
- 人工智能发展:推动AI在理解和生成与人类常识相符的内容方面的进步。
- 创意产业:在游戏设计、电影制作等领域,帮助设计师快速生成符合特定情景的图像概念。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...