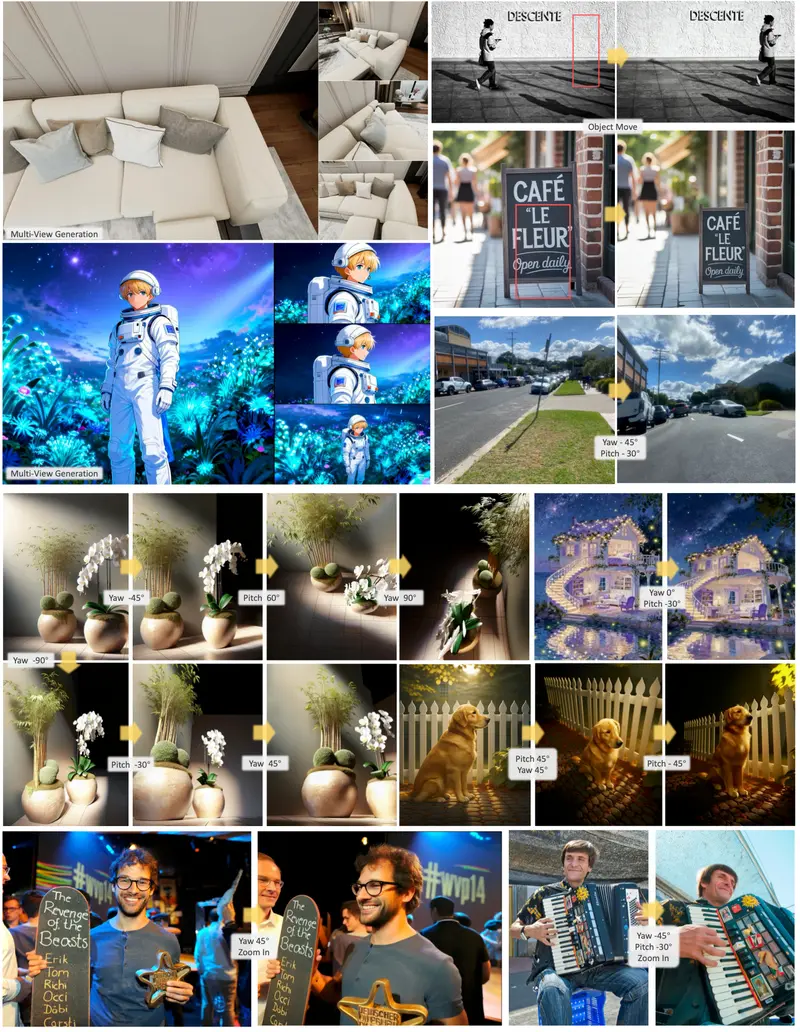
香港科技大学和华为诺亚方舟实验室的研究人员推出图像生成框架OmniBooth,它可以根据用户的多模态指令(如文本提示或图像参考)来生成具有空间控制和实例级定制化的图像。简单来说,用户可以指定多个对象的位置和属性,OmniBooth将根据这些指令生成图像。
- 项目主页:https://len-li.github.io/omnibooth-web
- GitHub:https://github.com/EnVision-Research/OmniBooth
- 模型:https://huggingface.co/lilelife/OmniBooth
OmniBooth的核心贡献在于提出的潜在控制信号,这是一种高维空间特征,提供了一个统一的表示,以无缝集成空间、文本和图像条件。文本条件扩展了 ControlNet,以提供实例级的开放词汇生成。图像条件进一步实现了细粒度的控制,具有个性化的身份。在实践中,OmniBooth使用户在可控生成中具有更大的灵活性,因为用户可以根据需要从文本或图像中选择多模态条件。

例如,你是一名游戏设计师,需要生成一个场景,其中包含一个穿着特定风格夹克的年轻男子在一个繁忙的街道上做一个滑板特技。你可以使用OmniBooth,提供文本描述“一个穿着特定风格夹克的年轻男子”和“繁忙的街道”,并指定滑板手和街道的空间位置。OmniBooth将生成一个符合这些描述和位置要求的图像。
主要功能
- 空间控制:用户可以定义对象的特定位置。
- 实例级定制:用户可以为每个对象指定详细的属性,如外观和风格。
- 多模态指令:用户可以通过文本描述或图像参考来指导图像生成。
主要特点
- 高维空间特征:使用潜在控制信号(latent control signal)来整合空间、文本和图像条件。
- 灵活性:用户可以根据需要选择文本或图像作为控制条件。
- 无需额外训练:在不同的任务和数据集上表现出色,无需针对特定任务进行微调。
工作原理
- 多模态嵌入提取:使用CLIP文本编码器提取文本嵌入,使用DINOv2提取图像嵌入。
- 统一多模态指令:通过将文本嵌入或图像嵌入绘制到潜在控制信号中,形成包含不同模态控制的统一条件。
- 特征对齐:开发了一个特征对齐网络,将潜在控制信号注入到潜在特征中。
- 边缘损失:通过边缘检测和渐进式前景增强来提高高频区域的监督。
具体应用场景
- 艺术创作:艺术家可以使用OmniBooth来生成具有特定风格和布局的图像。
- 设计和建筑:设计师可以使用它来创建符合特定设计规范的概念图。
- 娱乐和游戏:可以用于生成具有特定角色和场景的游戏图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...