
香港中文大学、华盛顿大学、不列颠哥伦比亚大学、麻省大学阿默斯特分校、 MIT-IBM Watson AI 实验室和思科研究院的研究人员推出多模态统一模型UniMuMo,它能够处理文本、音乐和动作(运动)数据,并在这三种模式之间生成内容。简单来说,UniMuMo就像一个多才多艺的艺术家,它可以根据你给的文本描述来创造音乐,或者给一段音乐配上合适的舞蹈动作,甚至还能描述一段舞蹈或音乐是什么样的。
- 项目主页:https://hanyangclarence.github.io/unimumo_demo
- GitHub:https://github.com/hanyangclarence/UniMuMo
例如,你是一个视频博主,想要为你的视频制作一个特定的背景音乐和舞蹈,你可以简单地描述你想要的风格和感觉,UniMuMo就能帮你生成音乐和舞蹈动作。或者,如果你听到一首曲子,想知道它是什么样的舞蹈,UniMuMo也可以帮你描述出来。
主要功能
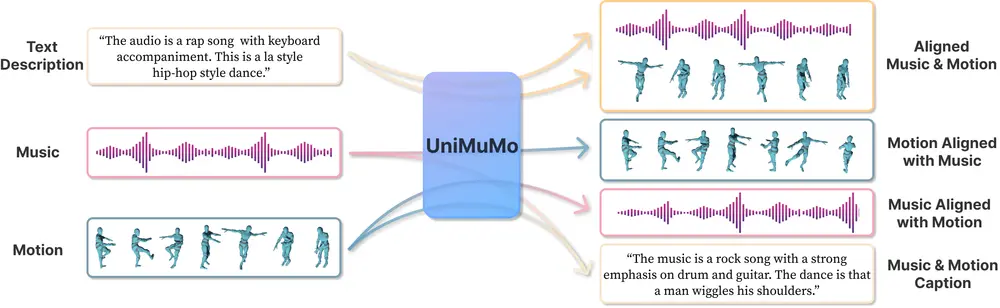
- 文本到音乐:根据文本描述生成音乐。
- 文本到动作:根据文本描述生成舞蹈动作。
- 音乐到动作:给定一段音乐,生成与之相匹配的舞蹈动作。
- 动作到音乐:给定一段舞蹈动作,生成匹配的音乐。
- 音乐描述:为一段音乐生成描述性的文本。
- 动作描述:为一段舞蹈生成描述性的文本。
主要特点
- 多模态:能够理解和生成文本、音乐和动作三种不同的数据形式。
- 统一框架:在一个模型中实现所有功能,而不是分开的多个模型。
- 数据增强:通过节奏模式对不同步态的数据进行对齐,扩充训练数据集。
- 编码器-解码器架构:使用统一的编码器-解码器结构来转换数据。
工作原理
UniMuMo的工作原理可以分为三个阶段:
- 音乐-动作联合标记化:将音乐和动作数据转换成统一的标记(token)表示形式。
- 音乐-动作并行生成:通过并行生成的方式,同时预测音乐和动作的下一个标记,实现音乐和动作的联合生成。
- 音乐-动作描述生成:使用训练好的音乐-动作解码器作为特征提取器,再训练一个文本生成模型来生成描述。
具体应用场景
- 娱乐行业:自动创作音乐视频,为舞蹈编排生成配乐。
- 游戏开发:为游戏中的舞蹈动作或背景音乐提供自动生成的方案。
- 教育:辅助音乐和舞蹈的教学,提供实例和练习材料。
- 虚拟现实(VR):在虚拟环境中,根据用户的文本输入生成相应的音乐或动作。
- 艺术创作:辅助艺术家在创作过程中探索不同艺术形式的结合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











