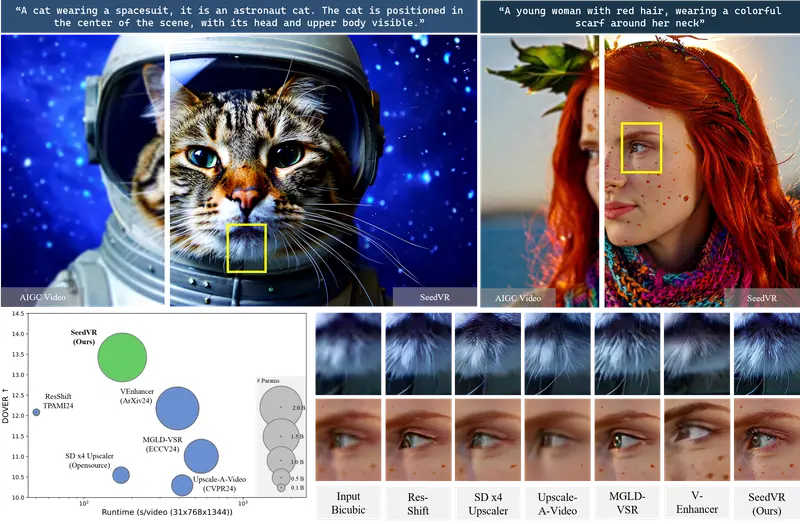
南洋理工大学和字节跳动的研究团队提出了 SeedVR,旨在解决通用视频恢复(video restoration,VR)中面临的挑战,即如何在处理未知退化的真实世界视频时,有效地恢复高质量视频并保持时间一致性和细节保真度,同时克服现有扩散模型在视频恢复方面的效率和效果局限。SeedVR是一个新颖的扩散变换器模型,旨在处理任意长度和分辨率的真实世界视频修复任务。
例如,我们有一段来自监控摄像头的低分辨率视频,视频内容是夜晚的街道,由于光线不足和摄像头质量限制,视频画面模糊且有很多噪点。使用SeedVR模型,我们可以将这段低质量视频转换成高分辨率、细节丰富的高质量视频,比如提升分辨率、增强清晰度、去除噪点等,使得视频中的街道、行人和车辆等细节更加清晰可见。
主要功能
主要特点
工作原理
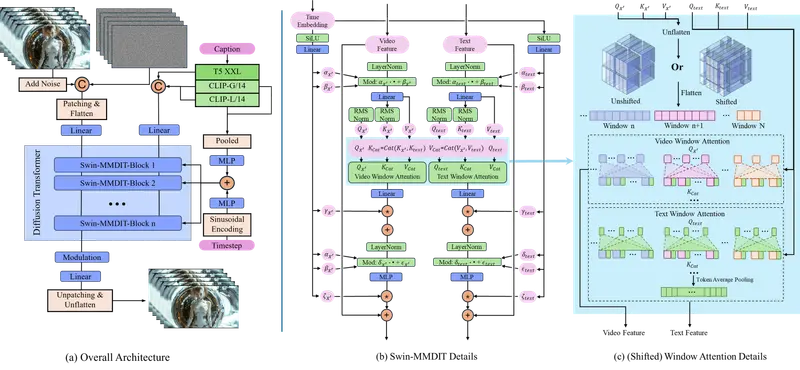
基于移位窗口的 MM - DIT 模块
- 采用 MM - DIT 作为基础模块,但引入移位窗口注意力机制改进其全注意力特性,以适应任意长度和分辨率的视频输入。对于输入视频特征和文本嵌入,先将视频特征扁平化,然后分别提取视频和文本的查询(query)、键(key)、值(value)。计算注意力时,采用两种窗口注意力:从左上角开始的常规窗口注意力和偏移半个窗口大小的移位窗口注意力。在窗口内计算注意力时,使用 3D 相对旋转位置嵌入(RoPE)来避免位置偏差。视频和文本特征的键值进行拼接,分别与各自的查询计算注意力,这种方式不增加计算成本且性能损失小。
因果视频自编码器(CVVAE)
- 为提高视频处理效率和重建质量,重新设计了视频自编码器。使用因果 3D 残差块来捕获时空表示,增加潜在通道数至 16 以提升模型容量,应用时间压缩因子 4 使编码更高效。通过在大规模数据集上使用 L1 损失、LPIPS 损失和 GAN 损失进行训练,该自编码器能有效处理长视频,将其切成片段进行处理。
大规模训练策略
- 混合数据训练:收集约 1 亿张图像和约 500 万视频组成大规模混合数据集,图像分辨率多样且多高于 1024×1024 像素,视频为从高分辨率视频随机裁剪的 720p 片段。通过多种评估指标筛选高质量样本,同时在图像和视频数据上训练模型,以提高其泛化能力。
- 预计算潜在特征和文本嵌入:由于高分辨率数据编码缓慢影响训练效率,预先计算高质量和低质量视频的潜在特征以及文本嵌入,使训练速度提升 4 倍。同时确保了低质量条件下的随机退化应用,且节省 GPU 内存,允许更大批量训练。
- 渐进式训练:模型基于 SD3 - Medium 初始化,从短、低分辨率视频(如 5 帧 256×256)开始训练,逐步增加视频长度和分辨率(如 9 帧 512×512,最终 21 帧 768×768),这种策略使模型能快速收敛,适应不同尺度的视频恢复任务。此外,通过向潜在低质量条件注入随机噪声,缩小合成低质量视频与真实世界视频的退化差距,避免因降低合成训练数据的退化程度而削弱模型生成能力。同时,随机用空提示替换文本输入,增强模型对不同文本条件的适应性,但避免过度增强生成能力导致输出保真度降低。
具体应用场景
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











