
来自中国科学技术大学和HiDream.ai的研究人员推出新型图像到视频扩散模型TRIP(Temporal Residual Learning with Image noise Prior),它专注于将静态图像转换为动态视频(即图像到视频生成,I2V)。TRIP模型的核心在于利用图像噪声先验来增强帧之间的时间一致性,同时保持与给定静态图像的忠实对齐。
例如,如果有一个静态图像提示为“一只熊猫正在清理自己的毛发”,TRIP模型可以根据这个静态图像和文本提示生成一个动态视频,其中熊猫不仅与原始图像保持视觉上的一致性,而且视频中的动作(如熊猫的毛发清理动作)在时间上也是连贯的。这展示了TRIP在保持图像一致性和生成时间连贯视频方面的能力。
主要功能和特点:
- 时间一致性: TRIP通过学习图像噪声先验来增强视频中相邻帧之间的时间一致性。
- 图像噪声先验: 利用给定静态图像和噪声视频潜在代码,通过一步反向扩散过程获得图像噪声先验。
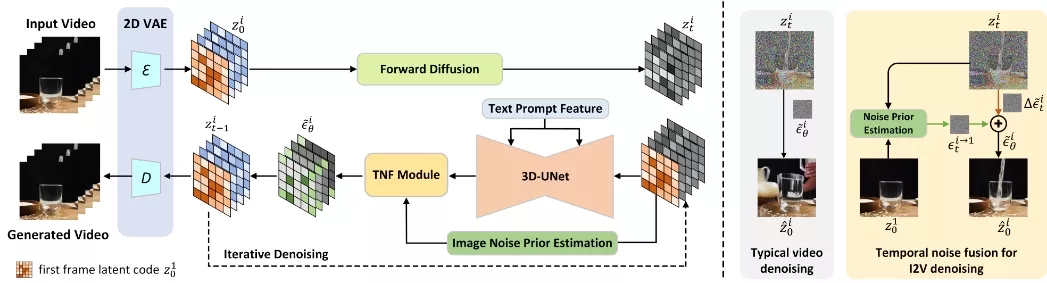
- 残差学习: 采用类似残差的学习方式,通过3D-UNet对噪声视频和静态图像潜在代码进行处理,以便于学习每一帧的残差噪声。
工作原理:
TRIP模型首先通过预训练的2D VAE将输入的视频剪辑编码成一系列帧的潜在代码。然后,将第一帧的图像潜在代码与噪声视频潜在代码在时间维度上进行拼接,作为3D-UNet的输入。接下来,TRIP通过两个路径进行噪声预测:一个是直接使用图像噪声先验作为参考噪声的快捷路径;另一个是通过3D-UNet估计残差噪声的残差路径。最后,使用基于Transformer的时间噪声融合模块动态地合并每一帧的参考噪声和残差噪声,生成与给定图像对齐的高质量视频。
具体应用场景:
- 娱乐和创意媒体: TRIP可以用于创造具有动态效果的图像,例如将静态的艺术作品转换成动态视频,增加娱乐性和吸引力。
- 社交媒体内容创作: 社交媒体用户可以使用TRIP将他们的照片转换成动态视频,以便在平台上分享更有吸引力的内容。
个性化视频生成: 用户可以根据文本提示和静态图像,生成个性化的视频内容,例如制作个性化的生日祝福视频或动画故事。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











