
Adobe和康奈尔大学的研究人员推出新型3D重建模型GS-LRM(Gaussian Splatting Large Reconstruction Model),这个模型能够从少数几张2D图像中快速预测出高质量的3D高斯原始体(3D Gaussian primitives),用于3D场景的重建和渲染。例如,你是一名游戏设计师,需要快速将概念艺术或草图转换成3D模型。使用GS-LRM,你只需提供几张不同角度的2D图像,模型就能迅速预测出3D场景的几何和纹理信息,从而生成可用于游戏引擎中的3D模型。这种方法大大加快了从概念到3D模型的转换过程。
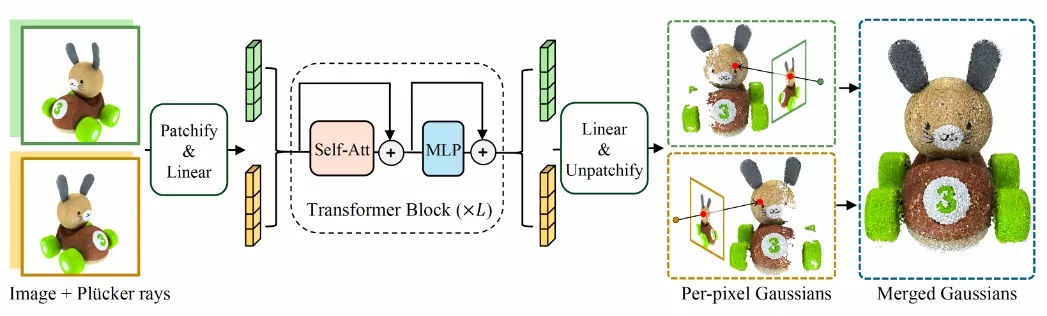
GS-LRM采用了一种非常简单的基于变压器的架构;开发者将输入的带有姿态的图像分割成小块,将多视图图像令牌串联后通过一系列变压器块传递,并直接从这些令牌中解码出用于可微渲染的最终像素级高斯参数。与之前只能重建物体的LRMs不同,通过预测每像素的高斯分布,GS-LRM自然而然地处理了尺度和复杂度存在巨大变化的场景。
主要功能和特点:
- 快速重建:GS-LRM能够在大约0.23秒内,在单个A100 GPU上从2-4张摆好姿势的稀疏图像中预测出3D高斯原语。
- 简单高效:模型采用了基于Transformer的简单架构,直接从图像块(patch tokens)预测每个像素对应的3D高斯参数,无需复杂的体积渲染。
- 高质量渲染:GS-LRM能够自然地处理具有大规模变化的场景,包括物体和复杂场景的重建。
- 可扩展性:模型在尺寸、训练数据和场景规模上都具有很高的可扩展性。
工作原理:
GS-LRM的工作原理包括以下几个步骤:
- 图像分块:将输入的多视图图像分割成小块(patches),并将这些图像块与相机的姿态信息(如Plücker坐标)结合起来。
- Transformer处理:通过一系列的Transformer模块处理这些图像块,利用自注意力机制(self-attention)和多层感知机(MLP)层来提取特征。
- 高斯参数预测:使用线性层从Transformer的输出中直接回归每个像素对应的3D高斯原语的参数。
- 渲染和重建:将预测的3D高斯原语用于不同的渲染任务,以生成新的视图图像或进行3D场景重建。
具体应用场景:
- 虚拟现实(VR):在VR应用中,GS-LRM可以快速从稀疏图像中重建出3D场景,为用户提供沉浸式体验。
- 增强现实(AR):在AR中,GS-LRM可以用于从用户提供的图像中即时生成3D模型,增强现实世界的交互性。
- 3D内容创建:对于电影制作、游戏开发等领域,GS-LRM提供了一种高效的3D重建解决方案,有助于创建逼真的3D场景。
- 文本到3D:GS-LRM还可以与文本条件生成模型结合,实现从文本描述到3D场景的转换。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











